1. container
container是linux很重要的一個概念。有了container方法,才能實現對對象的封裝。
分析一下container方法。
======================================================================
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
這個方法巧妙的實現了通過結構的一個成員找到整個結構的地址。有了container方法,list才
成為了一個通用的數據結構,通過container方法,還可以實現內核的封裝,程序之間不暴露
內部的數據。
2. 雙向鏈表list
List定義在/include/linux目錄下。首先看看list的結構定義:
struct list_head {
struct list_head *next, *prev;
};
List是雙向鏈表的一個抽象,list庫提供了list_entry,使用了container方法,通過container 可以從list找到整個數據對象,這樣list就成為了一種通用的數據結構。
======================================================================
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
內核定義了很多對list結構操作的內聯函數和宏,計有:
list_del:刪除一個list成員
3. hash list
Hash list和雙向鏈表list很相似,它適用於hash表。看一下hash list的head定義:
struct hlist_head {
struct hlist_node *first;
};
和通常的list比較,hlist頭只有一個指針,這樣就節省了一個指針的內存。如果hash表非常
龐大,那麼每個hash 表頭節省一個指針,整個hash表節省的內存就很可觀了。這就是內核
中專門定義hash list的原因。
Hash list庫提供的函數和list很相似,計有:
l HLIST_HEAD:定義並初始化一個hash list鏈表頭
l hlist_add_head:加一個成員到hash鏈表頭
l hlist_del:刪除一個hash list成員
l hlist_empty:檢查hash 鏈表是否為空
l hlist_for_each:遍歷hash 鏈表。
l hlist_for_each_safe:遍歷鏈表。和hlist_for_each區別是可以刪除遍歷的成員
l hlist_for_each_entry:遍歷hash 鏈表,通過container方法返回結構指針
4. 單向鏈表
內核中,沒有提供單向鏈表的定義。但實際上,有多處使用了單向鏈表的概念。
======================================================================
for (i = 0, p -= n; i < n; i++, p++, index++) {
struct probe **s = &domain->probes[index % 255];
while (*s && (*s)->range < range)
s = &(*s)->next;
p->next = *s;
*s = p;
}
上面的例子是加入一個新的字符設備到系統的表裡面。在系統的字符設備表裡,
probe結構其實就是單向鏈表。這種結構在內核中應用很廣泛。
5. red-black tree
紅黑樹位於/lib/rbtree.c文件。紅黑樹是一種自平衡的二叉樹。實際上,紅黑樹可以看做是折半查找。我們知道,排序的快速做法是取隊列的中間值比較,然後在剩下的隊列中再次取中間值比較,迭代進行直到找到最合適的位置。紅黑樹實際就是實現了這種算法。
那麼紅黑樹裡面的“紅黑”代表什麼意思?紅黑的顏色處理是避免樹的不平衡。舉個例子,如果1,2,3,4,5五個數字依次插入一顆紅黑樹,那麼五個值都落在了樹的右側,如果6再插入這顆紅黑樹,那麼需要比較五次。“紅黑規則”就要將樹旋轉,樹的根部要落在3這個節點,只需要比較兩次,這樣就避免了樹的不平衡導致的問題。
內核中的io調度算法和內存管理中都使用了紅黑樹。紅黑樹有很多介紹的文章,讀者可以結合代碼分析一下。
6. radix tree
內核提供了一個基樹庫,代碼在/lib/radix-tree.c文件。基樹是一種空間換時間的數據結構,
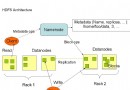
通過空間的冗余減少了時間上的消耗。用一張圖來分析:
圖中顯示,元素空間總共為256,但元素個數不固定。那麼如果用數組存儲,好處是插入查找只用一次操作,但是存儲空間需要256,這是不可思議的。如果用鏈表存儲,存儲空間節省了,但是極限情況下查找操作次數等於元素的個數。而采用一顆高度為2的基樹,第一級最多16個冗余結構,代表元素前四位的索引。第二級代表元素後四位的索引。那麼只要兩級查找就可以找到特定的元素,而且只有少量的冗余數據。圖中假設只有一個元素10001000,那麼只有樹的第一級有元素,而且樹的第二級只有1000這個節點有子節點,其它節點都不必分配空間。這樣既可以快速定位查找,也減少了冗余數據。
基樹很適合存儲稀疏的數據,內核中文件的頁cache就采用了基樹。關於基樹的文章很多,讀者可以結合代碼分析一下。