


數據包嗅探工具如tcpdump是普遍用於實時數據包轉儲,需要設定一些過濾規則,只捕獲HTTP流量,即便如此,它的輸出內容很難理解,需要一定的協議基礎知識。實時的Web服務器日志分析工具如ngxtop提供了可讀的實時網絡流量的痕跡,但僅適用於具有完全訪問過的Web服務器的日志。
有沒有一款功能強大且又只針對HTTP流量的工具呢?那就是httpry,HTTP數據包嗅探工具。捕獲HTTP數據包,並顯示可讀格式的HTTP協議層面的內容。
安裝httpry
在基於debian系統如Ubuntu,httpry沒有包含在基礎倉庫中。
$ sudo apt-get install gcc make git libpcap0.8-dev $ git clone https://github.com/jbittel/httpry.git $ cd httpry $ make $ sudo make install
Fedora、centos、RHEL系統需要安裝EPEL源
$ sudo yum install httpry
也可以源碼編譯
$ sudo yum install gcc make git libpcap-devel $ git clone https://github.com/jbittel/httpry.git $ cd httpry $ make $ sudo make install
httpry基本用法
$ sudo httpry -i <network-interface>
httpry監聽在指定的網卡下,實時捕獲並顯示HTTP請求與響應的包
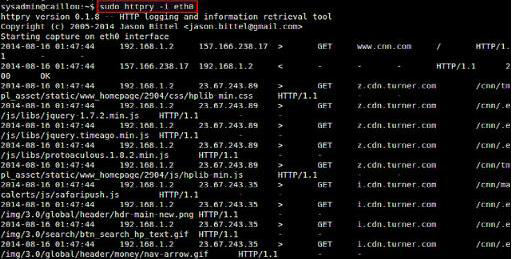
在大多數情況下,輸出滾動非常快的,需要保存捕獲的HTTP數據包進行離線分析。可以使用-b或-o選項。“-b”選項將原始的HTTP數據包保存到一個二進制文件,然後可以用httpry進行重播。 “-o”選項保存可讀的輸出到文本文件。
保存到二進制文件中:
$ sudo httpry -i eth0 -b output.dump
重放:
$ httpry -r output.dump
保存到文本文件:
$ sudo httpry -i eth0 -o output.txt
httpry高級用法
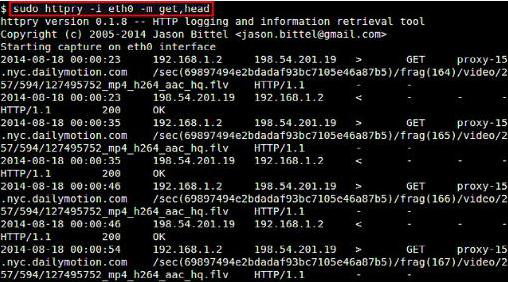
如果你要捕獲特定的HTTP方法,如GET、POST、PUT、HEAD、CONNECT等等,可以使用‘-m’選項:
$ sudo httpry -i eth0 -m get,head
如果你下載httpry源碼,在源碼目錄下,有一個perl腳本來幫助我們分析httpry輸出。該腳本在httpry/scripts/plugins目錄下。 如果你想編寫一個httpry輸出的定制解析器,這些腳本是個很好的例子。功能有:
hostname : 顯示一些列唯一主機名
find_proxies:檢測web代理
search_terms:查找並計算在搜索服務中輸入搜索詞
content_analysis:查找包含特定關鍵字的URI
xml_output:以xml格式輸出
log_summary:生成日志摘要
db_dump:將日志轉存到mysql數據庫中
在使用這些腳本前,先使用’-o’選項運行一段時間。一旦得到輸出,運行這些腳本分析:
$ cd httpry/scripts
$ perl parse_log.pl -d ./plugins <httpry-output-file>
parse_log.pl執行完後,會在httpry/scripts目錄下生成一些分析結果文件(*.txt/xml)。例如,log_summary.txt看起來像下面這樣:

總而言之,如果你碰到需要解讀實時HTTP數據包的情況,httpry就幫得上大忙。普通的Linux用戶可能不常解讀實時HTTP數據包,但防患未然總歸不是件壞事。
上面就是Linux下使用httpry工具嗅探HTTP流量的介紹了,httpry工具除了能夠嗅探HTTP流量外,還能夠捕獲實時HTTP數據包,是不是很實用呢?不妨試試看吧。