嵌入式Linux應用程序訪問物理地址的實例
2013-05-28 14:09:25 來源:EEWORLD
關鍵字: Linux 驅動 可移植 接口
前言
按照
Linux分層
驅動思想,外設驅動與主機控制器的驅動不相關,主機控制器的驅動不關心外設,而外設驅動也不關心主機,外設訪問核心層的通用應用程序
接口進行數據傳輸,主機和外設之間可以進行任意的組合。這樣思想要求應用程序不應當直接訪問物理地址,而是應當通過驅動程序的調用來實現,以便保持應用程序的
可移植性,操作訪問的統一性,應用程序利用系統的統一調用接口訪問外設,如使用write(),read()等函數進行實際的外設讀寫控制。應用程序通過調用接口進入內核函數後,內核利用copy_from_user()獲得應用層數據,內核驅動程序也通過分層最終執行物理訪問,之後把獲得的數據用copy_to_user()回傳給應用程序的調用者。由於驅動對外需要有個統一接口,所以定義了一些結構體,鏈表等機制,以便讓應用程序操作簡單化,數據在內核一應用之間的復制,填充結構體等都需要時間開銷,有時按這種標准調用方式,因為操作時間過長,無法完成設計目的。
操作效率評估
我們的一個項目中,系統由
FPGA和ARM11結合為核心控制器,其中FPGA連接外部高速ADC、DAC和RF器件在ARM11的控制下,實現GB18000-6C標准的UHF
RFID讀寫控制狀態機。FPGA與ARM11的接口采用SPI,其中ARM11選用三星S3C6410,作為SPI的主機,FPGA作為SPI的從機,受S3C6410的控制。在本系統中,SPI接口充當ARM11和FPGA交互的橋梁,ARM11的命令和動作參數傳給FPGA並啟動FPGA處理狀態機,FPGA動作的結果也通過SPI回傳給ARM11,兩者之間的通訊效率在系統中需要重點關注。
評估通訊接口時,利用三星提供的SPI驅動函數,系統運行在533MHz,SPI時鐘配置為16MHz,程序在linux3.0環境下通過read/write進行操作,為了評估效率,另外采用一個GPIO輸出脈沖指示操作過程,試驗結果顯示效率非常低下,從應用層執行write代碼開始到SPI端口輸出時鐘,延時長達72μs,SPI操作之後,再回到應用層的下一個語句也延時42μs,對於比較少的數據傳輸情況,附加的額外等待時間遠遠長於實際傳輸有效時間,從前面數據看出,通過標准庫調用嚴重影響系統性能,沒法滿足系統需求。通過查看驅動程序的源代碼,可以發現因為驅動程序層層封裝,並且包含應用層到內核的copy_from_user()和內核到應用層的copy_to_user()兩次數據搬移,導致執行效率很低。為了提高數據交互效率,就要設法繞開數據搬移等時間開銷,最好能直接操作寄存器,雖然這種想法與Linux分層驅動思想不相符合,但是在
嵌入式系統中,有時需要高的執行效率,如果利用系統一些特定函數,實現高效率的數據交互從而完成設計目標是有必要和可能的。
linux存在名為mmap的函數,能把物理地址映射為虛擬地址,並且這個函數能直接在應用程序中直接調用而不是僅僅屬於內核調用的函數,這樣在應用層直接操作S3C6410的物理外設成為可能。考慮到在特定的嵌入式系統中,特定外設的使用可以由程序控制,這樣可以簡化共享設備的互斥保護,進一步減少代碼量,提高了訪問效率。
mmap函數調用實例
mmap函數作用是將物理地址映射至用戶空間。下面是函數的參數簡單說明
void* mmap(void * addr, size_t len, int prot, int flags, int fd, off_t offset);
addr: 指定文件應被映射到進程空間的起始地址
len: 映射到用戶空間的字節數
prot: 指定被映射空間的訪問權限,
flags: 由以下幾個常值指定:
fd: 映射到用戶空間的文件的描述符
offset: 被映射內存區在文件中的偏移值該函數映射文件描述符
通過這個函數,我們可以在應用層訪問對應物理地址正確映射後的虛擬地址,這個函數使我們在應用層也具有對任意物理地址的操作權限,下面代碼配置S3C6410的SPI0,因為使用mmap映射,所以不論內核是否帶有SPI驅動都不影響我們使用SPI0,但是因為本程序需要對比研究標准驅動方式與直接存儲器訪問方式的執行差異,所以在內核中編譯了標准SPI的驅動程序。由於S3C6410多數腳都有復用功能,為了使SPI0正確工作,還需要配置相關對應的GPIO為SPI功能(實際上因為我們編譯的內核帶有SPI0的驅動,內核程序已經完成了SPI的初始化,有的內核沒有編譯SPI,所以下面還是完整配置了SPI,供參考),同時為了觀察研究SPI的執行效率,我們程序還對其他GPIO做了配置以便輸出脈沖,通過
示波器來評估觀察。另外我們還使用若干時間標志來記錄操作過程時間,對於在沒有示波器的情況下也能評估執行時間。
下面是測試程序代碼以及測試過程的示波器記錄抓圖。
#include "test.h"
void Init_FPGA_SPI(){ //配置SPI端口
int fbb;
fbb=open("/dev/mem",O_RDWR | O_SYNC);
map_base=(char *)mmap(0,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fbb,0x7f00b000);
*(volatile unsigned int *)(map_base+0x04)=0x00000101; //CLK=16.625MHz
*(volatile unsigned int *)(map_base+0x08)=0x00000000;
*(volatile unsigned int *)(map_base+0x0c)=0x00000002;
*(volatile unsigned int *)(map_base)=0x00000003;
FPGA_RUN=map_base+0x18;
map_base=(char *)mmap(0,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fbb,0x7f008000);
GPC=map_base+0x40; //配置端口復用功能為SPI
map_GPC=*(volatile unsigned int *)(GPC+4);
*(volatile unsigned int *)(GPC)=0x12201222;
GPC+=4;
virt_addr2=map_base+0x824;//配置觀察IO
G
LEDstate=*(volatile unsigned
int *)(virt_addr2);
}
void Init_Timer(){ //添加加配置1微秒時基定時器
int fbb;
unsigned int temp;
fbb=open("/dev/mem",O_RDWR | O_SYNC);
map_base=(char *)mmap(0,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fbb,0x7f006000);
…………………… 篇幅原因略去部分次要代碼
MYSYSTICK=map_base+0x14;
}
void SPI_init(){
bits=8;
speed = 16625000;
trr.len =20;
trr.delay_usecs = 0;
trr.speed_hz = speed;
trr.bits_per_word = bits;
fspi = open("/dev/spidev0.0", O_RDWR);
ioctl(fspi, SPI_IOC_RD_MODE, &mode);
ioctl(fspi, SPI_IOC_WR_MODE, &mode);
}
__inline unsigned int GETSYSCLK(){
return(*(volatile unsigned int *)(MYSYSTICK));
}
__inline void CSFPGAL(){
map_GPC&=0xfffffff7;
*(volatile unsigned int *)(GPC)=map_GPC;
}
__inline void CSFPGAH(){
map_GPC|=0x00000008;
*(volatile unsigned int *)(GPC)=map_GPC;
}
void test(){
GLEDstate&=0xfffffffe;
*(volatile unsigned int *)(virt_addr2)=GLEDstate;//產生GPIO負跳變
starttime2=GETSYSCLK();
*(volatile unsigned int *)(FPGA_RUN-0x0c)=0x00;
*(volatile unsigned int *)(FPGA_RUN-0x18)=0x23;
*(volatile unsigned int *)(FPGA_RUN-0x18)=0x03;
CSFPGAL();
*(volatile unsigned int *)(FPGA_RUN)=tx[0];
*(volatile unsigned int *)(FPGA_RUN)=tx[1];
*(volatile unsigned int *)(FPGA_RUN)=tx[2];
*(volatile unsigned int *)(FPGA_RUN)=tx[3];
*(volatile unsigned int *)(FPGA_RUN)=tx[4];
while (((*(volatile unsigned int *)(FPGA_RUN-4)&0xfe000)>>13)<5){};
CSFPGAH();
stoptime2=GETSYSCLK();
GLEDstate|=0x00000001;
*(volatile unsigned int *)(virt_addr2)=GLEDstate;
GLEDstate&=0xfffffffe;
*(volatile unsigned int *)(virt_addr2)=GLEDstate;
starttime1=GETSYSCLK(); //產生GPIO一個正脈沖
write(fspi,&tx,5);
stoptime1=GETSYSCLK();
GLEDstate|=0x00000001;
*(volatile unsigned int *)(virt_addr2)=GLEDstate; //產生GPIO正跳變
printf("DRVtime=%d REGtime=%d ",starttime1-stoptime1,starttime2-stoptime2);
}
int main(void){
SPI_init(); Init_FPGA_SPI(); Init_Timer();
waittime=GETSYSCLK();
while(1){
if ((waittime-GETSYSCLK())>2000000){ //2000ms測試一次
waittime=GETSYSCLK();
test();
}
}
}
圖1示波器截圖添加了一些時間信息以便對應代碼注釋說明,對應於代碼mmap方式和標准驅動調用方式產生了兩組SCK時鐘,GPIO觀察腳顯示第一次SPI訪問消耗5μs,第二次訪問消耗114μs,其中真正操作SPI的時間也就4μs不到,其它時間消耗在系統應用層到內核兩次雙向的數據拷貝以及為了統一對外接口所做的數據結構配置等方面,由此對比可以看出兩種方式訪問效率上的巨大差異。
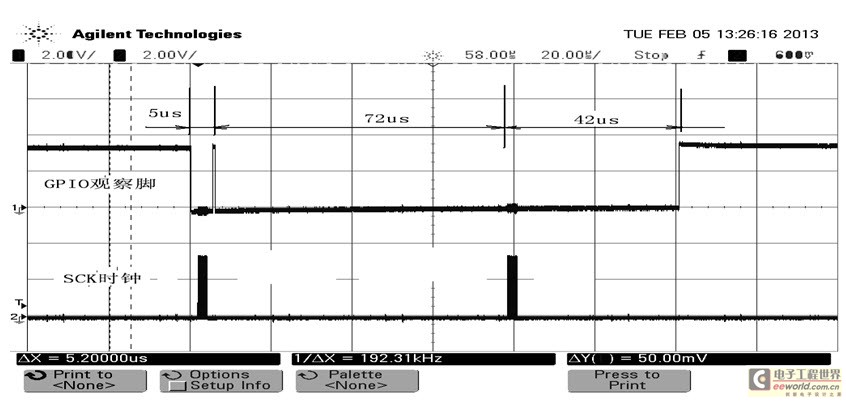
圖 1
結語
通過mmap方式應用程序在Linux下操作硬件寄存器,適合於關注高效率的訪問場合,在嵌入式應用中,我們既能夠獲得使用操作系統管理任務和豐富開源驅動庫的好處,同時又能在局部提升處理效率,提高處理數據的實時性。