作者:
[email protected] 博客地址:bean.blog.chinaunix.net
最近花了10幾天的時間,將linux進程調度相關的內核代碼看了兩遍左右,也看了一些講述linux進程調度的一些文章,總想寫個系列文章,把進程調度全景剖析一遍,但是總是感覺力不逮己,自己都不敢下筆寫文章了。算了,還是不難為自己了,就隨便寫寫自己的心得好了。
在用戶空間,或者應用編程領域 ,Linux提供了一些API或者系統調用來影響Linux的內核調度器,或者是獲取內核調度器的信息。比如可以獲取或者設置進程的調度策略、優先級,獲取CPU時間片大小的信息。
這些接口一旦在應用程序中調用,就像給湖面扔進一顆石子,對內核帶來了那些的影響,其實這是我內心很激動很想分享的東西,但是內容好沒有組織好,所以本文的主題暫不深入涉及這些系統調用及對應的內核層的代碼。
嚴格地說,對於優先級對於實時進程和普通進程的意義是不一樣的。
1 在一定程度上,實時進程優先級高,實時進程存在,就沒有普通進程占用CPU的機會,(但是前一篇博文也講過了,實時組調度出現在內核以後,允許普通進程占用少量的CPU時間,取決於配置)。
2 對於實時進程而言,高優先級的進程存在,低優先級的進程是輪不上的,沒機會跑在CPU上,所謂實時進程的調度策略,指的是相同優先級之間的調度策略。如果是FIFO實時進程在占用CPU,除非出現以下事情,否則FIFO一條道跑到黑。
a)FIFO進程良心發現,調用了系統調用sched_yield 自願讓出CPU
b) 更高優先級的進程橫空出世,搶占FIFO進程的CPU。有些人覺得很奇怪,怎麼FIFO占著CPU,為啥還能有更高優先級的進程出現呢。別忘記,我們是多核多CPU ,如果其他CPU上出現了一個比FIFO優先級高的進程,可能會push到FIFO進程所在的CPU上。
c)FIFO進程停止(TASK_STOPPED or TASK_TRACED狀態)或者被殺死(EXIT_ZOMBIE or EXIT_DEAD狀態)
d) FIFO進程執行了阻塞調用並進入睡眠(TASK_INTERRUPTIBLE OR TASK_UNINTERRUPTIBLE)。
如果是進程的調度策略是時間片輪轉RR,那麼,除了前面提到的abcd,RR實時進程耗盡自己的時間片後,自動退到對應優先級實時隊列的隊尾,重新調度。
下面我們就是來探究FIFO策略和RR策略的特點。為了降低理解的難度,我將我們啟動的實時進程綁定到同一個核上。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/time.h>
#include<sys/types.h>
#include<sys/sysinfo.h>
#include<time.h>
#define __USE_GNU
#include<sched.h>
#include<ctype.h>
#include<string.h>
#define COUNT 300000
#define MILLION 1000000L
#define NANOSECOND 1000
void test_func()
{
int i = 0;
unsigned long long result = 0;;
for(i = 0; i<8000 ;i++)
{
result += 2;
}
}
int main(int argc,char* argv[])
{
int i;
struct timespec sleeptm;
long interval;
struct timeval tend,tstart;
struct tm lcltime = {0};
struct sched_param param;
int ret = 0;
if(argc != 3)
{
fprintf(stderr,"usage:./test sched_method sched_priority\n");
return -1;
}
cpu_set_t mask ;
CPU_ZERO(&mask);
CPU_SET(1,&mask);
if (sched_setaffinity(0, sizeof(mask), &mask) == -1)
{
printf("warning: could not set CPU affinity, continuing...\n");
}
int sched_method = atoi(argv[1]);
int sched_priority = atoi(argv[2]);
/* if(sched_method > 2 || sched_method < 0)
{
fprintf(stderr,"sched_method scope [0,2]\n");
return -2;
}
if(sched_priority > 99 || sched_priority < 1)
{
fprintf(stderr,"sched_priority scope [1,99]\n");
return -3;
}
if(sched_method == 1 || sched_method == 2)*/
{
param.sched_priority = sched_priority;
ret = sched_setscheduler(getpid(),sched_method,¶m);
if(ret)
{
fprintf(stderr,"set scheduler to %d %d failed %m\n");
return -4;
}
}
int scheduler = sched_getscheduler(getpid());
fprintf(stderr,"the scheduler of PID(%ld) is %d, priority (%d),BEGIN time
is :%ld\n",
getpid(),scheduler,sched_priority,time(NULL));
sleep(2);
sleeptm.tv_sec = 0;
sleeptm.tv_nsec = NANOSECOND;
for(i = 0;i<COUNT;i++)
{
test_func();
}
interval = MILLION*(tend.tv_sec - tstart.tv_sec)
+(tend.tv_usec-tstart.tv_usec);
fprintf(stderr," PID = %d\t priority: %d\tEND TIME is %ld\n",getpid(),sched_priority,time(NULL));
return 0;
}
上面這個程序有幾點需要說明的地方
1 為了降低復雜度,綁定到了同一個核上,我做實驗的機器是四核(通過cat /proc/cpuinfo可以看到)
2 sleep(2),是給其他進程得到調度的機會,否則無法模擬出多個不同優先級的實時進程並行的場景。sleep過後,就沒有阻塞性的系統調用了,高優先級的就會占據CPU(FIFO),同等優先級的進程輪轉(RR)
struct sched_param {
/* ... */
int sched_priority;
/* ... */
};
int sched_setscheduler (pid_t pid,
int policy,
const struct sched_param *sp);
sched_setscheduler函數的第二個參數調度方法 :
#define SCHED_OTHER 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#ifdef __USE_GNU
# define SCHED_BATCH 3
#endif
SCHED_OTHER表示普通進程,對於普通進程,第三個參數sp->sched_priority只能是0
SCHED_FIFO 和SCHED_RR表示實時進程的調度策略,第三個參數的取值范圍為[1,99]。
如果sched_setscheduler 優先級設置的值和調度策略不符合的話,會返回失敗的。
內核中有這麼一段注釋:
/*
* Valid priorities for SCHED_FIFO and SCHED_RR are
* 1..MAX_USER_RT_PRIO-1, valid
priority for SCHED_NORMAL,
* SCHED_BATCH and SCHED_IDLE is 0.
*/
LINUX系統提供了其他的系統調用來獲取不同策略優先級的取值范圍:
#include <sched.h>
int sched_get_priority_min (int policy);
int sched_get_priority_max (int policy);
另外需要指出的一點是,應用層和內核層的優先級含義是不同的:
首先說實時進程:實時進程的優先級設置可以通過sched_setsheduler設置,也可以通過sched_setparam設置優先級的大小。
int sched_setparam (pid_t pid, const struct
sched_param *sp);
在用戶層或者應用層,1表示優先級最低,99表示優先級最高。但是在內核中,[0,99]表示的實時進程的優先級,0最高,99最低。[100,139]是普通進程折騰的范圍。應用層比較天真率直,就看大小,數字大,則優先級高。ps查看進程的優先級也是如此。有意思的是,應用層實時進程最高優先級的99,在ps看進程優先級的時候,輸出的是139.
下面是ps -C test -o pid,pri,cmd,time,psr 的輸出:
PID PRI CMD TIME PSR
6303 139 ./test 1 99 00:00:04
1
雖說本文主要講的是實時進程,但是需要插句話。對於普通進程,是通過nice系統調用來調整優先級的。從內核角度講[100,139]是普通進程的優先級的范圍,100最高,139最低,默認是120。普通進程的優先級的作用和實時進程不同,普通進程優先級表示的是占的CPU時間。深入linux內核架構中提到,普通優先級越高(100最高,139最低),享受的CPU time越多,相鄰的兩個優先級,高一級的進程比低一級的進程多占用10%的CPU,比如內核優先級數值為120的進程要比數值是121的進程多占用10%的CPU。
內核中有一個數組:prio_to_weight[20]表示的是默認優先級120的權重,數值為1024,prio_to_weight[21]表示nice值為1,優先級為121的進程的權重,數值為820。這就到了CFS的原理了
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
假如有1台電腦,10個人玩,怎麼才公平。
1 約定好時間片,每人玩1小時,玩完後記賬,張XX 1小時,誰玩的時間短,誰去玩
2 引入優先級的概念,李四有緊急情況,需要提高他玩電腦的時間,怎麼辦,玩1個小時,記賬半小時,那麼同等情況下,李四會比其他人被選中玩電腦的頻率要高,就體現了這個優先級的概念。
3 王五也有緊急情況,但是以考察,不如李四的緊急,好吧,玩1個小時,記賬45分鐘。
4 情況有變化,聽說這裡有電腦,突然又來了10個人,如果按照每人玩1小時的時間片,排在最後的那哥們早就開始罵人了,怎麼辦?時間片動態變化,根據人數來確定時間片。人越多,每個人玩的時間越少,防止哥們老撈不著玩,耐心耗盡,開始罵人。
這個記賬就是我們prio_to_weight的作用。我就不多說了,prio_to_weight[20]就是基准,玩一小時,記賬一小時,數組20以前的值是特權一級,玩1小時記賬20分鐘之類的享有特權的,數組20之後是倒霉蛋,玩1小時,記賬1.5小時之類的倒霉蛋。 CFS這種調度好在大家都能撈著玩。
扯到優先級多說了幾句,現在回到正題。我將上面的C程序編譯成可執行程序test,然後寫了一個腳本comp.sh。
[root@localhost sched]# cat comp.sh
#/bin/sh
./test $1 99 &
usleep 1000;
./test $1 70 &
usleep 1000;
./test $1 70 &
usleep 1000;
./test $1 70 &
usleep 1000;
./test $1 50 &
usleep 1000;
./test $1 30 &
usleep 1000;
./test $1 10 &
因為test進程有sleep 2秒,所以可以給comp.sh啟動其他test的機會。可以看到有 99級(最高優先級)的實時進程,3個70級的實時進程,50級,30級,10級的各一個。
對於FIFO而言,一旦sleep過後,高優先級運行,低優先級是沒戲運行的,同等優先級的進程,先運行的不運行完,後運行的也沒戲。
對於RR而言,高優先級的先運行,同等優先級的進程過家家,你玩完,我玩,我玩完你再玩,每個進程耗費一個時間片的時間。對於Linux,RR時間片是100ms:
#define DEF_TIMESLICE (100 * HZ / 1000)
下面我們驗證: 我寫了兩個觀察腳本,來觀察實時進程的調度情況:
第一個腳本比較簡單,觀察進程的CPU 占用的time,用ps工具就可以了:
[root@localhost sched]# cat getpsinfo.sh
#!/bin/sh
for((i = 0; i < 40; i++))
do
ps -C test -o pid,pri,cmd,time,psr >>psinfo.log 2>&1
sleep 2;
done
第二個腳本比較復雜是systemtap腳本,觀察名字為test的進程相關的上下文切換,誰替換了test,或者test替換了誰,同時記錄下test進程的退出:
[root@localhost sched]# cat
cswmon_spec.stp
global time_offset
probe begin { time_offset = gettimeofday_us() }
probe scheduler.ctxswitch {
if(next_task_name == "test" ||prev_task_name == "test")
{
t = gettimeofday_us()
printf(" time_off (%8d )%20s(%6d)(pri=%4d)(state=%d)->%20s(%6d)(pri=%4d)(state=%d)\n",
t-time_offset,
prev_task_name,
prev_pid,
prev_priority,
(prevtsk_state),
next_task_name,
next_pid,
next_priority,
(nexttsk_state))
}
}
probe scheduler.process_exit
{
if(execname() == "test")
printf("task :%s PID(%d) PRI(%d) EXIT\n",execname(),pid,priority);
}
probe timer.s($1) {
printf("--------------------------------------------------------------\n")
exit();
}
A) FIFO調度策略的輸出:
終端1 :
stap ./cswmon_spec.stp 70
終端2 :
./getpsinfo.sh
終端3
./comp.sh 1
輸出結果如下:
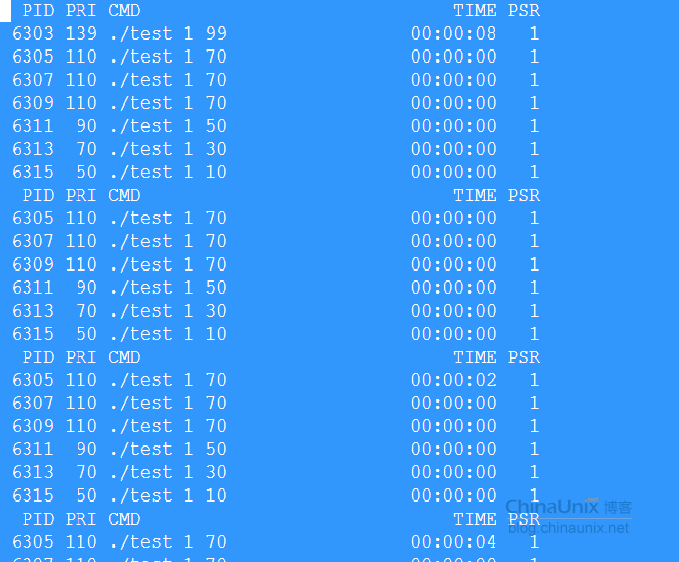
99優先級跑完了,才輪到70優先級,但是雖說有3個70優先級,但是先跑的那個進程跑完了,第二個優先級為70的才能跑。因為輸出結果用代碼無法漂亮的展示,所以我截了圖,截圖又不能把這個輸出都截下來,所以我很蛋疼。有需要結果的,我以附件形式附在最後。
看下第二個腳本的輸出:
time_off ( 689546 ) test( 6305)(pri= 120)(state=0)-> migration/2( 11)(pri= 0)(state=0)
time_off ( 689977 ) stap( 5895)(pri= 120)(state=0)-> test( 6305)(pri= 120)(state=0)
time_off ( 690067 ) test( 6305)(pri= 29)(state=1)-> stap( 5895)(pri= 120)(state=0)
time_off ( 697899 ) test( 6303)(pri= 120)(state=0)-> migration/2( 11)(pri= 0)(state=0)
time_off ( 698042 ) test( 6307)(pri= 120)(state=0)-> migration/0( 3)(pri= 0)(state=0)
time_off ( 699114 ) stap( 5895)(pri= 120)(state=0)-> test( 6303)(pri= 120)(state=0)
time_off ( 699307 ) test( 6303)(pri= 0)(state=1)-> test( 6307)(pri= 120)(state=0)
time_off ( 699371 ) test( 6307)(pri= 29)(state=1)-> stap( 5895)(pri= 120)(state=0)
time_off ( 699392 ) test( 6309)(pri= 120)(state=0)-> migration/3( 15)(pri= 0)(state=0)
time_off ( 699966 ) events/1( 20)(pri= 120)(state=1)-> test( 6309)(pri= 120)(state=0)
time_off ( 700034 ) test( 6309)(pri= 29)(state=1)-> stap( 5895)(pri= 120)(state=0)
time_off ( 707379 ) test( 6311)(pri= 120)(state=0)-> migration/3( 15)(pri= 0)(state=0)
time_off ( 707587 ) test( 6313)(pri= 120)(state=0)-> migration/0( 3)(pri= 0)(state=0)
time_off ( 712021 ) stap( 5895)(pri= 120)(state=0)-> test( 6311)(pri= 120)(state=0)
time_off ( 712145 ) test( 6311)(pri= 49)(state=1)-> test( 6313)(pri= 120)(state=0)
time_off ( 712252 ) test( 6313)(pri= 69)(state=1)-> stap( 5895)(pri= 120)(state=0)
time_off ( 727057 ) test( 6315)(pri= 120)(state=0)-> migration/0( 3)(pri= 0)(state=0)
time_off ( 727952 ) stap( 5895)(pri= 120)(state=0)-> test( 6315)(pri= 120)(state=0)
time_off ( 728047 ) test( 6315)(pri= 89)(state=1)-> stap( 5895)(pri= 120)(state=0)
time_off ( 2690181 ) stap( 5895)(pri= 120)(state=0)-> test( 6305)(pri= 29)(state=0)
time_off ( 2699316 ) test( 6305)(pri= 29)(state=0)-> test( 6303)(pri= 0)(state=0)
task :test PID(6303) PRI(0) EXIT
time_off (13057854 ) test( 6303)(pri= 0)(state=64)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (13057864 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6305)(pri= 29)(state=0)
time_off (15333340 ) test( 6305)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (15333354 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6305)(pri= 29)(state=0)
time_off (18743409 ) test( 6305)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (18743422 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6305)(pri= 29)(state=0)
time_off (22154757 ) test( 6305)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (22154771 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6305)(pri= 29)(state=0)
task :test PID(6305) PRI(29) EXIT
time_off (22466855 ) test( 6305)(pri= 29)(state=64)-> test( 6307)(pri= 29)(state=0)
time_off (25563548 ) test( 6307)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (25563566 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6307)(pri= 29)(state=0)
time_off (28973602 ) test( 6307)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (28973616 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6307)(pri= 29)(state=0)
task :test PID(6307) PRI(29) EXIT
time_off (31846121 ) test( 6307)(pri= 29)(state=64)-> test( 6309)(pri= 29)(state=0)
time_off (32383671 ) test( 6309)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (32383683 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6309)(pri= 29)(state=0)
time_off (35793735 ) test( 6309)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (35793747 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6309)(pri= 29)(state=0)
time_off (39203797 ) test( 6309)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (39203809 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6309)(pri= 29)(state=0)
task :test PID(6309) PRI(29) EXIT
time_off (41200440 ) test( 6309)(pri= 29)(state=64)-> test( 6311)(pri= 49)(state=0)
time_off (42613866 ) test( 6311)(pri= 49)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (42613898 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6311)(pri= 49)(state=0)
time_off (46024070 ) test( 6311)(pri= 49)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (46024082 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6311)(pri= 49)(state=0)
time_off (49434004 ) test( 6311)(pri= 49)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (49434017 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6311)(pri= 49)(state=0)
task :test PID(6311) PRI(49) EXIT
可以清楚的可到,同樣是70優先級(內核態是29),6305退出以前,6307根本就撈不著跑。同樣6307退出一樣,6309根本就撈不著跑。這就是FIFO。
B) RR的情況
終端1 :
stap ./cswmon_spec.stp 70
終端2 :
./getpsinfo.sh
終端3
./comp.sh 1
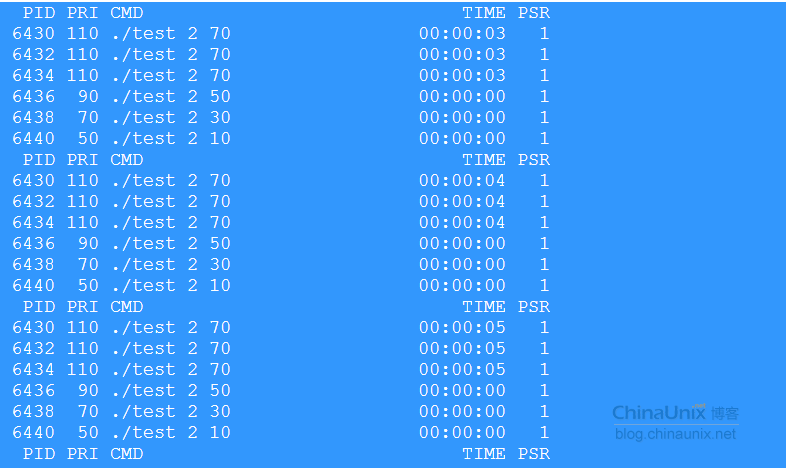
實時優先級是70的三個進程齊頭並進。再看第二個腳本的輸出:
time_off ( 4188015 ) test( 6428)(pri= 0)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off ( 4188025 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6428)(pri= 0)(state=0)
time_off ( 7612014 ) test( 6428)(pri= 0)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off ( 7612024 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6428)(pri= 0)(state=0)
task :test PID(6428) PRI(0) EXIT
time_off (10679062 ) test( 6428)(pri= 0)(state=64)-> test( 6430)(pri= 29)(state=0)
time_off (10964413 ) test( 6430)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (10964422 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6430)(pri= 29)(state=0)
time_off (11709024 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (12736030 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
time_off (13779022 ) test( 6434)(pri= 29)(state=0)-> test( 6430)(pri= 29)(state=0)
time_off (13879021 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (13984075 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
time_off (14084020 ) test( 6434)(pri= 29)(state=0)-> test( 6430)(pri= 29)(state=0)
time_off (14184023 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (14284024 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
time_off (14374486 ) test( 6434)(pri= 29)(state=0)-> watchdog/1( 10)(pri= 0)(state=0)
time_off (14374502 ) watchdog/1( 10)(pri= 0)(state=1)-> test( 6434)(pri= 29)(state=0)
time_off (14384097 ) test( 6434)(pri= 29)(state=0)-> test( 6430)(pri= 29)(state=0)
time_off (14484066 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (14584023 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
time_off (14684020 ) test( 6434)(pri= 29)(state=0)-> test( 6430)(pri= 29)(state=0)
time_off (14786032 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (14886020 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
time_off (14986026 ) test( 6434)(pri= 29)(state=0)-> test( 6430)(pri= 29)(state=0)
time_off (15089023 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (15192030 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
time_off (15292026 ) test( 6434)(pri= 29)(state=0)-> test( 6430)(pri= 29)(state=0)
time_off (15396085 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (15496022 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
time_off (15596027 ) test( 6434)(pri= 29)(state=0)-> test( 6430)(pri= 29)(state=0)
time_off (15696153 ) test( 6430)(pri= 29)(state=0)-> test( 6432)(pri= 29)(state=0)
time_off (15796022 ) test( 6432)(pri= 29)(state=0)-> test( 6434)(pri= 29)(state=0)
用戶態實時優先級為99,內核態優先級為0的進程6428退出後,3個用戶態實時優先級為70的進程6430,6432,6434你方唱罷我登場,每個人都"唱"多久呢?看相鄰2條記錄的時間差,基本都在100ms左右,這就是時間片。
後記:如果放開綁定到一個CPU的限制,同時加大實時進程的個數,多個實時進程在CPU之間PULL和PUSH,是更復雜的情況,呵呵,希望拋磚引玉,能有人模擬下這種情況。
附件為測試代碼及輸出:

study_sched.txt
參考文獻
1 深入linux 內核架構
2 linux system program
3 systemtap example