為了讓 Linux® 應用程序在全世界范圍都可以使用,而不會在西方語言與世界上其他語言之間產生任何區別,我們應該發行一些本地化後的版本,它們可以輸入、存儲、提取或呈現任何語言,而不管這些語言是多麼復雜。多語言庫,或稱為 m17n,為類 UNIX® 平台上的所有語言提供了一個國際化解決方案。
在很短的時間之內 —— 總共還不到 20 年 —— 個人計算機已經成為我們工作和生活中的一種必需設備。受到半導體和處理器快速發展的推動,大量的供應商使得計算機的價格一落千丈,Internet 也已經在全球廣為分布,個人計算機現在已經不再是一種奢侈品,而是一種常見的家用電器了。
實際上,在很多富裕的國家(例如美國、日本、英國),每兩個家庭就會擁有一台計算機,並且會使用寬帶服務。就全世界來看,雖然家庭收入可能會有很大的不同,但是個人計算機都很容易購買了,即使在馬爾代夫,我們也很容易購買到筆記本。另外,如果我們碰巧說的是 Dhivehi 方言(馬爾代夫的一種方言),微軟也為我們提供了一個這種版本的 Microsoft® Windows® XP 操作系統。
就全球廣泛接受的個人計算機來說,大部分現代操作系統都提供了一些編程庫來促進 國際化 的發展,或者將軟件調整為支持多種語言的。國際化(通常簡寫為 i18n,節選自 i-nternationalizatio-n)庫通常都會將應用程序的文本資源(按鈕標簽、用戶界面[UI] 提示和菜單選項)保存成多種語言的。在啟動國際化後的應用程序後顯示哪種語言,這要取決於用戶的區域設置 —— 通常,這是一個可配置的系統或個人帳號首選項。
理想來說 —— 至少對於獨立軟件供應商來說 —— 相同的可執行程序以日語或希臘語運行時都能運行得一樣好。然而,構建 “本地方言” 版本的應用程序的情況遠遠沒有這麼理想。包括被廣泛認可的 ISO(International Standards Organization)/IEC(International Engineering Consortium)10646 和 Unicode,沒有哪種字符編碼可以解決如何實現任意語言的輸入和呈現問題。ISO/IEC 10646 和 Unicode 只指定了如何存儲、檢索和排序字符以及字符的特殊組合。例如,這些標准並沒有規定統一的格式、嵌入式數據或標識來讓使用泰國語書寫的文檔怎樣才能按照泰國語的規范規則正確地呈現出它們的樣子來。是的,Unicode 可以維護使用泰國語書寫的文檔的內容,也可以保證這種文件在所有使用 Unicode 的平台上都可以很好地進行移植,但是它並不能保證我們可以正確查看文件,也不能保證文檔所呈現出來的樣子與作者的意圖一致。
我們來考慮一下這種情況:盡管 Linux GNU C 庫(glibc)提供了一些函數來處理 ISO 10646 兼容的 31 位字符,但是它並不能保證這些字符可以在顯示設備上正確進行顯示。有些 glibc 字符串函數,例如 strcat() 和 strlen(),都可以正確地處理多字節的問題,但是要正確顯示阿拉伯語,需要雙向(bidi)顯示的功能,這種功能只有在圖形用戶界面(GUI)工具包和專用字符串顯示庫中才能找到。
例如,GNOME 需要 GTK+ 工具包和 Pango(一個文本顯示庫)來實現對 i18n 的完整支持(然而,Pango 在解決自己用途不夠廣泛方面有一些限制。請參看側欄 pango 的問題)。其他 GUI 工具包提供了對 i18n 的支持,但卻並不總是能兼容這些標准。當然,Linux 上的圖形應用程序也需要 X Window System 的基本顯示庫 Xlib,它提供了兩種繪圖(形狀和線條)和字符顯示原語。不幸的是,Xlib 只能顯示西歐語言。
![]() Pango 的問題
Pango 的問題
Pango 可以放置(布局)並顯示一些復雜的手稿,但是不能對多字節的文本進行排序或搜索功能。Pango 假設底層庫 —— 通常是使用 C 語言編寫的,可以對使用 Unicode 標准指定的所有語言都進行操作 —— 可以執行基本的文本處理操作。
一個庫顯示所有語言
要讓應用程序在全球都可以使用 —— 而不會在西方國家和世界上其他很多語言之間產生不公平的現象 —— 我們必須要能夠 輸入、存儲、提取並 顯示 任何語言,而不管這究竟會多麼復雜。正如上面介紹的一樣,有一些廣為認可的標准為多字節存儲和可移植性提供了一些便利;然而,現在還沒有為輸入和顯示制定標准。更加糟糕的是,即使是最好的多語言文本編輯器也會被迫混合使用簡單的國際化庫和私有 GUI 工具包。添加一種語言可能會需要另外一種(很可能是新的)定制庫。
Multilingualization Library 或 m17n 庫會盡力為類 UNIX 平台上多種語言書寫的文本的輸入、處理和顯示提供一種單一的解決方案。另外,m17n 的目標是充分利用現有且大家都可以很好地理解的典型 UNIX 應用程序框架,而不是利用軟件開發人員的其他模型。
最後,m17n 會努力使國際化的內容更加豐富,而不僅僅是簡單地從英語移植到另外一種語言上。使用 m17n,同一個二進制文件可以在一個系統上顯示法語,在另外一個系統上顯示蒙古語,甚至在同一個屏幕上就可以顯示多種語言的文本。更好的是,m17n 可以(令人信服地)實現諸如文本數據庫之類的功能,這使它可以存儲並處理大量的國際化內容。
m17n 庫是在日本 Tsukuba 的 National Institute for Advanced Science and Technology 工作的 4 個日本程序員編寫的。很多年以來,日本都一直走在了國際化的前端,部分原因是日語學者一直在試圖為人文學科探索一種百科全書式的方法 —— 尤其對世界上各種語言更為關注(有關歷史上的一些內容,請參看側欄 亞洲語言的起源。)
![]() 亞洲語言的起源
亞洲語言的起源
世界上很多國家的手寫語言(這也是用戶使用的最多的形式)都是在全世界最重要的宗教之一 —— 佛教(也是日本最重要的宗教信仰)之內產生並不斷演進的。
印度、中國以及緬甸的語言和手稿很多都是有關佛經的歷史的。日本的佛教學者也需要學習梵語、巴利語、古漢語、古藏語、中日語以及古日語的幾個變種,另外在深入研究佛教之前,還需要學習 3 本日語手稿(如果它們可以稱為手稿的話)。熟悉梵語、古漢語以及幾種古日語的變種對於佛教學者來說只是工作的一個最低需求。而且他們常常還需要了解現有佛教所使用的一些語言,例如僧伽羅人語、泰國語、現代韓語等。
在以佛教文化為根基的外向型經濟中,要想了解世界,僅僅使用一種語言是不可想像的。
m17n 庫是由 3 個庫和一個存儲單一腳本以及正確顯示腳本所需要的元數據的數據庫構成的:
C 庫可以類似地實現 glibc (以及各種風格的 libc )的一些基本的文本處理功能。
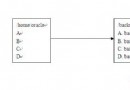
圖 1 給出了 m17n 的 4 個部分,以及這些庫是如何與現有的系統組件對應的。m17n 組件和傳統 UNIX 庫之間存在驚人的類似之處並不意外:m17n 的創建者希望能夠讓多語言的應用程序的編寫盡量簡單。我們只要使用一個等效的多語言庫來替換相同語義的函數即可。
圖 1. m17n 庫的層次結構 
(從側面來看,m17n C 和 X 庫就預示著 X 服務器可以提供國際化功能。不過,m17n 對底層操作系統和呈現機制的假設較少,因此我們可以將 m17n 移植到其他窗口系統上。實際上,將 m17n 集成到跨平台的 GUI 工具包(例如類 UNIX 系統上使用的 Qt)正是當前的工作重點,m17n 團隊正在將自己的代碼加入 GTK 的修正版本中。)