


(一)sed
sed是一個精簡的、非交互式的流式編輯器,它在命令行中輸入編輯命令和指定文件名,然後在屏幕上查看輸出。
逐行讀取文件內容存儲在臨時緩沖區中,稱為“模式空間”(pattern space),接著用sed命令處理緩沖區的內容,處理完成後,把緩沖區的內容送往屏幕。接著處理下一行,這樣不斷重復,直到文件末尾。原文件愛你的內容並沒有改變。
sed '4,$d' test.in # 刪除4~最後一行 sed '3q' test.in # 讀到指定行之後退出 sed 's/public/PUBLIC/' test.in # 替換public為PUBLIC sed -n 's/public/PUBLIC/p' test.in #打印匹配行sed [options] sed_cmd files
-e 連接多個編輯命令
-f 指定sed腳本文件名
-n 阻止輸入行自動輸出
通常grep也能達到效果,例如統計指定文件中的行數
COUNT=$(cat $FILE | grep -a "關鍵字" | wc -l)
指定多個命令的三種方法:
1.用分號分隔命令
sed 's/public/PUBLIC/;s/north/NORTH/' test.in2.每個命令前放置-e
sed -e 's/public/PUBLIC' -e 's/north/NORTH' test.in3.使用分行命令功能,在輸入單引號後按Enter鍵就會出現多行提示符(>)
sed ' > s/public/PUBLIC/ > s/northNORTH' test.in
常用的定位命令:

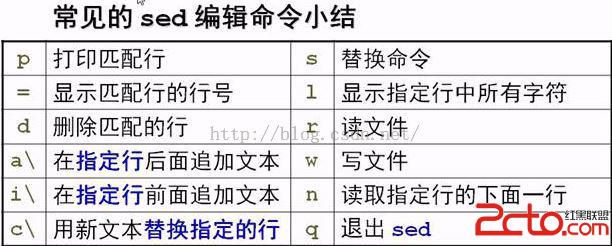
常見的編輯命令:
p: 打印匹配行
sed -n '3,5p' test,in
=: 顯示匹配行的行號
sed -n '/north/=' test.in
d: 刪除匹配的行
sed -n '/north/d' test.in
a\: 在指定行之後追加一行或者多行文本,並顯示添加的新內容。
sed '/north/a\AAA\
>BBB\
>CCC' test.in
i\: 在指定行之前插入一行或者多行文本,並顯示新內容,同上。
c\: 用新文本替換指定的行,使用格式同上
l : 顯示指定行中的所有字符,包括控制字符(非打印字符)
sed -n '/north/l' test.in
s:替換命令,使用格式為
[address] s/old/new/[gpw]
address:如果省略,表示編輯所有的行
g: 全局替換
p: 打印被修改後的行
w fname: 將被替換後的內容寫到指定的文件中
sed -n 's/north/NORTH/gp' test.in
sed -n 's/north/NORTH/w data' test.in
sed 's/[0-9][0-9]$/&.5/' datafile
&符號用在替換字符串中時,代表被替換的字符串
r: 讀文件,將另外一個文件中的內容附加到指定行後
sed '$r data' test.in
w: 寫文件,將指定行寫入到另外一個文件中
sed -n '/public/w date2' test.in
n: 將指定行的下面一行讀入編輯緩沖區
sed -n '/public/{n;s/north/NORTH/p}' test.in
對指定行同時使用多個sed編輯命令時,需用大括號括起來,命令之間用分號;隔開。
q:退出,讀取到指定行之後退出sed
sed '3q' test.in
(二)awk
awk可以對列進行處理
簡單用法:
awk [options] sed_script files
-F 指定輸入記錄字段的分隔符,默認環境變量IFS的值
-f 從指定文件讀取awk_script
-v 為awk設定變量
awk -F:'{print $1}' /etc/passwd
awk -F:'/root{print $1 "|" $3}' /etc/passwd

awk的執行過程:
1. 如果存在BEGIN,awk首先執行他指定的actions
2. awk從輸入中讀取一行,稱為一條消息記錄
3. awk將讀入的記錄分割成數個字段,並將第一個字段放入變量$1中,第二個放入變量$2中,依次類推;$0表示整條記錄;字段分隔符可以通過選項-F指定,否則使用缺省的分隔符。
4. 把當前輸入記錄依次與每一個awk_cmd中的pattern比較:
如果相匹配,就執行對應的actions
如果不匹配,就跳過對應的actions,直到完成所有的awk_cmd
5. 當一條輸入記錄記錄完畢後,awk讀取輸入的下一行,重復上面的處理過程,直到所有輸入全部處理完畢。
6. awk處理完所有的輸入後,若存在END,執行相應的actions
7. 如果輸入是文件列表,awk將按順序處理列表中的每個文件
awk處理的例子:
ifconfig | awk '/inet addr/{ print $2 }'| awk -F:'{ print $2 }'
ifconfig | awk '/inet addr/{ print $2 }'|awk -F: 'BEGIN { print "begin..."}'{ print $2 } END { print "end..." }'
另外,awk還可以處理復合表達式:
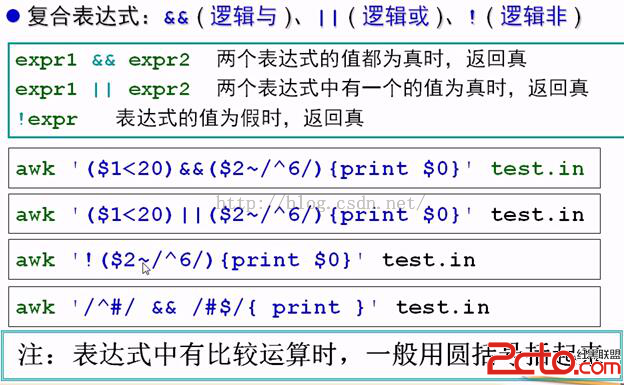
最後,awk不僅是一個命令,它更是一個編程語言
變量:
1. 內部變量 awk '{print NR,$0}' #給文件加上行號
2.自定義變量
函數:
1.內置函數
2.自定義函數
awk '{print sum($1,$2)} function sum(x,y){s=x+y;return s}' grade.txt
數組
awk 'BEGIN {print split("123#456",arr,"#");for(i in arr){print arr[i]}}'
由於這些比較復雜,本文不再展開介紹。
最後附上幾個簡單的shell腳本,更多的實例在我的Github上。
(1)比較大小
#!/bin/bash
echo "please input the two numbers:"
read a
read b
if (($a==$b));then
echo "a = b"
elif (($a>$b));then
echo "a > b"
else
echo "a < b"
fi
(2)查找文件
#!/bin/bash
echo "Enter a file name :"
read a
if [ -e /home/tach/$a ];then
echo "the file is exist!"
else
echo "the file is not exist!"
fi
(3)刪除大小為0的文件
#!/bin/bash
for filename in `ls`
do
a=$(ls -l $filename | awk '{print $5}')
if ((a==0));then
rm $filename
fi
done
(4)查看本機IP地址
#!/bin/bash
ifconfig | grep "inet 地址:" | awk '{print $2}' | sed 's/地址:'//g
(5)IP地址合法性判斷
#!/bin/bash
CheckIPAddr()
{
#IP地址需由三個.分隔且均是數字
echo $1 | grep "^[0-9]\{1,3\}\.\([0-9]\{1,3\}\.\)\{2\}[0-9]\{1,3\}$" > /dev/null
if [ $? -ne 0 ];then
return 1
fi
ipaddr=$1
a=`echo $ipaddr | awk -F. '{print $1}'`
b=`echo $ipaddr | awk -F. '{print $2}'`
c=`echo $ipaddr | awk -F. '{print $3}'`
d=`echo $ipaddr | awk -F. '{print $4}'`
for num in $a $b $c $d
do
if [ $num -gt 255 -o $num -lt 0 ];then
return 1
fi
done
return 0
}
if [ $# -ne 1 ];then
echo "Usage :$0 ipaddr."
exit
else
CheckIPAddr $1
ans=$?
if [ $ans -eq 0 ];then
echo "legal ip address."
else
echo "unlegal ip address."
fi
fi
(6)其他
#!/bin/bash
#顯示當前日期和時間
echo `date +%Y-%m-%d-%H:%M:%S`
#查看哪個IP地址連接的最多
netstat -an | grep ESTABLISHED | awk '{print $5}'|awk -F: '{print $1}' | sort | uniq -c
#awk不排序刪除重復行
awk '!x[$0]++' filename
#x只是一個數據參數的名字,是一個map,做指定的邏輯判斷,如果邏輯判斷成立,則執行指定的命令;不成立,直接跳過這一行
#查看最常使用的10個unix命令
awk '{print $1}' ~/.bash_history | sort | uniq -c | sort -rn | head -n 10
#sort中的-r是降序,_-n是按照數值排序(默認比較字符,10<2)
#逆序查看文件
cat 1.txt | awk '{a[i++]=$0} END {for (j=i-1; j>=0;) print a[j--] }'
#查看第3到6行
awk 'NR >=3 && NR <=6' filename
#crontab文件的一些示例
30 21 * * * /usr/local/etc/rc.d/lighttpd restart #每晚9.30重啟apache
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart #每月的1,10,22日的4:45重啟apache
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart #每周六、日的1:10重啟apache
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart #表示在每天18.00至23.00之間每隔30分鐘重啟apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart #晚上11點到早上7點之間,每隔一小時重啟apache