部門團建,大家都去長隆了,也有去澳門廣西的...我去了夢裡...本來我也報了名的,想單獨帶著女兒獨處兩天,不光為了培養跟女兒的感情,也是想讓老婆歇兩天...只可惜女兒最近生病,去不了了,六一兒童節的表演也由於生病被拒絕了,很是失落,更失落的是我,於是帶著失落和憤怒,又有些許對不公道的無能的宣洩,我半夜爬起來,把這一切都訴諸給TCP/IP吧!
就像上學時一樣,大家臨考前還在打牌,就我一個人在看書,結果他們就說我裝,我就承認我裝,但問題是,他們說完我裝以後不到半小時,都去看書去了!我希望每個人都TMD裝起來,氣氛搞起來!周末全部用於學習和工作!即使下班回到家裡也要支起攤子,學習和工作!永遠別去旅游!永遠不參加集體活動,99%的時間留給學習和工作!死的時候,嘴裡喊著TCP/ip!忘掉女兒吧,忘掉家人吧,忘掉世界吧,從另一個維度觀察這個令人XX的世界吧!
奇妙的世界
世界上很多事務都可以描述為正態分布,不管你信不信,事實就是如此,如果將這些事務細分,對於很多的離散的事件,均可以描述為泊松分布,不管你信不信,事實就是如此。不要試圖去問“為什麼世界上很多事實符合正態分布或者泊松分布?”,因為本來就是這個樣子,在沒有人出現之前就是這樣,正態分布也好,泊松分布也好,正是人們找到的一種描述這種本質的一個“形容詞”而已。
TCP發送端測量RTT的困惑
TCP的RTT到底可用嗎?可用!只是很難發現規律而已。
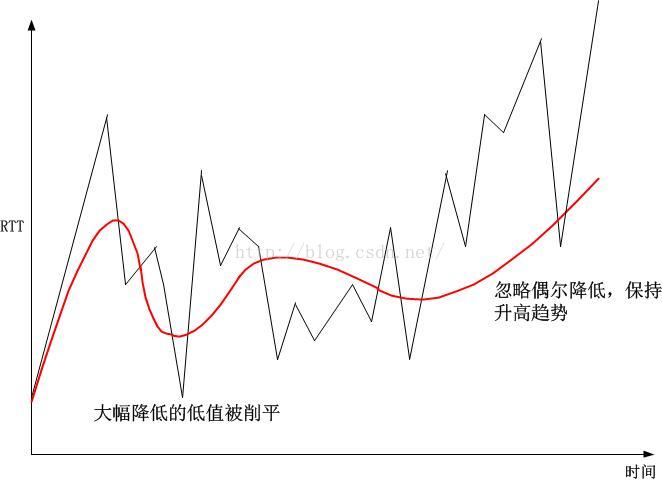
人們天生有一種拔毛刺的習慣,臉上長個粉刺就要想法摳掉它,痣上長根毛也要拔掉它,看見誰愛出風頭耍個性,就想千方百計整死他...如果看到測量的RTT波動很大,就非要想個算法把高值和低值去掉從而不看見它們,
Gaius Julius Caesar不是說過嗎,
人們總希望看到自己想看到的,那我就給他們!拿破侖也說過,
你不是個子高嗎,我削除這個差別!都是帶點血腥的,但是同時意味著只有少數人才能看到真相。
根本就不該對RTT做任何假設,不但要關心它的穩定趨勢,還要關心它的所謂毛刺!我相信波動的疊加,干涉,衍射是一個普遍的真理,任何事務都是有多個波疊加而成的,這些波具有不同的頻率,波長,以及其它特性,我們需要做的就是分解它而不是試圖湮沒它。所以我從來不蔑視精神分裂患者,也不蔑視精神病人,因為這才是本質的,其它的都是裝的,湮沒過的。要想理解RTT的特點,要分兩方面,一個是因,一個是果,原因呢,就是網絡的行為,結果呢,自然就是發送端的行為了。
網絡的行為
我們先來看一下網絡上的數據包分組的行為,這是這種行為影響了TCP端到端的擁塞控制決策,網絡行為是因,擁塞控制是果。
脆弱的隊列
想當然的,我們會覺得路由器,交換機這種中間設備的隊列(或者你可以直接認為是緩沖區)是一個緩解擁塞的有利設施,它可以緩解擁塞造成的後果。這麼理解是對的,然而只對了一方面,如果我們直視問題,那麼“擁塞”這個詞是在有了“隊列”這個設施以後才這麼叫的,問題的本質在於“沖突”!兩個數據包同時經由一個路由器,必然發生沖突,這意味著輸掉的一方必須被丟棄,或者更慘烈的,兩敗俱傷。如果你對早期半雙工總線以太網的CSMA/CD模型有足夠深入的理解,就會明白這個事實。
然而對於IP互聯網,不能采用CSMA/CD這種機制,因為代價太高了,整個網絡是如此之大,以至於即便使用不可超越的光速,沖突檢測的時延也是不可忍受的,另一方面,節點是如此之多,以至於可以預想的沖突是多麼地激烈!因此,互聯網采用了另外一種措施,即沖突前仲裁,也就是引入了隊列的概念,把自由爭搶資源變成了有序復用資源。現實世界到處存在這種事實,比如兩個人打架,隨時開打,但是放眼到整個世界,就會有很多的規則。
但是,這個隊列是不穩定的,它不會像你想象的那樣會優雅的為你提供沖突時的容身之地,而是會隨著流量的增加隨時崩潰,這就意味著端到端協議必須發現排隊現象,以便采取措施緩解隊列。對於路由器而言,它能采取的措施只有一個,就是丟棄數據包!
在繼續定量化分析之前,我們有必要來點排隊論的知識,但一點點就夠了。
排隊理論
排隊論是分組交換的核心,正是它使得分組交換替代電路交換成了可能。事實證明,分組交換的統計復用要比電路交換的固定X分復用(比如TDM)更加有效,也許,統計復用的背後可能就是見縫插針,然而排隊現象的本質卻不是見縫插針的結果,而是到達過程和服務過程的不均衡!到達過程是統計的,然而服務過程不能是統計的,它必須由到達過程來驅動,換句話說,到達的事件在受到服務可以排隊但不能丟棄,而服務者寧可空轉而不搶單!我後面會從一個悖論來詳細說這個問題,最終的結論先給出:服務的效率必須高於到達率才能避免隊列變成無限長!
然而,現實世界更加復雜,我們國家總是看到服務部門效率遠小於到達率,然而並沒有看到永久隊列...TMD不到下午4點就下班了,第二天再來吧!從而消除了隊列!其實你問下隨便排隊的一個人,問他們排幾天了,他們的回答會讓你理解排隊論。另外,即使你不能理解計算機內部的排隊現象,那麼去一下火車站售票口也行,或者,看看高峰期的大城市快速路高架橋...為什麼隊列沒有永久加深,那是因為隊列的清空是強制的。
然而,為了討論簡單,我不談現實,只談理論情形,因此我不會引入任何路由器排隊策略方面的東西。
泊松分布與指數分布
我們直接給出結論,數據包的到達過程中單位時間內到達數據包的數量是符合泊松分布的,由此可以推導出相鄰數據包的到達間隔是符合指數分布的,這是自然界中奇妙統計規律的體現。
如果直觀地理解這兩個分布,非常簡單,統計學中有個中心極限法則,意思是每個事務都有一個中心,即平均點,越偏離中心的概率越低,比如人類的平均身高是1.75cm,這意味著你將很難找到2.5cm或者0.5cm的人。對於指數分布,可以這樣理解,如果你去一家公司面試,過了一天沒有給你打電話,過了三天還是沒有給你電話,那麼你此後接到電話的幾率將迅速降低,這是合理的,一般而言,對於如意的人,招聘方會在很短的時間通知你的。
M/M/1排隊模型
排隊論非常復雜,本文的目的僅僅是為了幫助理解TCP在擁塞時RTT的變化情況以及發送端的反應,因此並不准備深入排隊論內部,這部分內容在研究路由器行為時顯得更加重要(寫到這裡...又讓我想起了去年的事,想起了華為...)。
M/M/1模型屬於排隊論裡描述普遍情況的最簡單的一種,第一個M代表到達過程服從泊松分布,第二個M代表服務過程符合負指數分布(由到達過程驅動,前後被服務對象無關聯),第三個1表示只有一個服務者。整體的過程邏輯上如下圖所示:
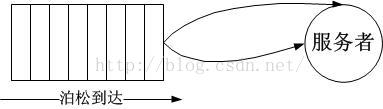
到達過程
按照時間序列展開,到達過程可以直觀地描述成下面的樣子:

我們設到達率##,意味著##只是一個“平均數”,只是說這個到達過程中單位時間到達##的可能性很大,但偶爾也會在單位時間內到達多於##或者少於##,這個務必要記住,因為這是引起排隊的比較重要的原因。
服務過程
服務過程比較簡單,說它是一個指數分布是因為它是受到到達過程驅動的,由泊松分布的理論我們知道到達過程中兩件事到達的時間間隔符合指數分布,對於服務過程來講,它服務的正是到達的事件,因此服務的間隔就是到達的間隔,所以它是符合指數分布的。
你可以把服務過程看作是一個不停輪轉的傳送帶上的一個機械手臂,它沒有智能,只會不停地試圖抓取傳送帶上的物品,如果沒有物品,就空抓一次,有的話就抓取到旁邊的框子裡。它抓到物品的時間間隔符合指數分布。理解了這一點,有助於理解我後面給出的一個悖論的解釋。
排隊分析
我們直接給出根據M/M/1排隊模型得到的結論,並沒有任何關於這個結論的推導過程,這不是本文的核心,事實上推導非常簡單。
(1).排隊數據包的數量
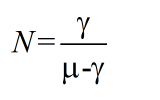
(2).排隊數據包的等待時延
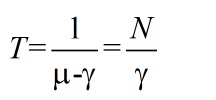
(3).每一個數據包的等待時延
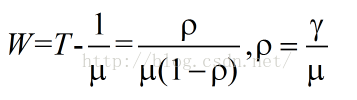
(4).平均隊列長度
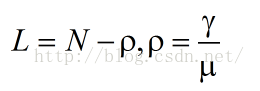
通過上述的(1)可以看出,如果
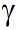
和

的比值小於接近1,N將會趨向於無窮大,這意味著若不想讓隊列無限制擠壓,服務率必須大於到達率才可以,我們再看另一個極端,N為1的時候,也就是說僅僅有自己排隊(可以近似為沒有隊列)的情形,算出來服務率必須是到達率的2倍!也就是
和
的比值為1/2,我們看一下(1)關於N和

比值的圖像:
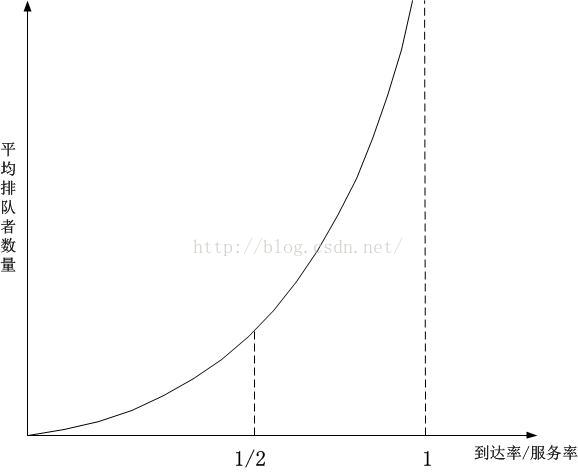
發現上述比值在1/2和1之間的時候,曲線逐漸抖上去了,這意味著,只要到達率稍微增加一丁點,排隊者的數量將迅速增加(對比(4)),如果此時發送方再不降低速率甚至增加速率,隊列將無限制增加,網絡將崩潰。
於此同時,我們看一下(3),隨著到達率的增加,和排隊者一樣,隊列中數據包的排隊時延也將迅速增加!這就是為什麼TCP數據采集到RTT波動特別大的原因,RTT並不會無緣無故地波動,原因幾乎都是發生了擁塞,而波動的幅度和持續時間,受到了路由器的排隊策略的影響,這意味著何時緩解擁塞將決定RTT的波動曲線!
至於說路由的隊列管理,並不是本文的內容范圍,可以簡單說一下,路由器可以簡單的進行尾部丟棄,也可以進行隨機丟棄,可以基於數據包特征進行優先級排隊,更復雜的內容可以自行google關於“主動隊列管理(Active Queue Management,AQM)”的內容。
正是由於存在路由器的隊列管理,現實世界中,網絡才不至於崩潰,因為路由器不允許隊列無限長。在發現有隊列即將暴漲的預兆之後,路由器就會采取措施了,這種措施的結果會反饋到數據包的發送端,由該發送端自行決策如何反應,在接著這部分之前,我們先來看一個好玩的悖論。
一個悖論
我想通過一個悖論來描述一下以上排隊分析這背後的原因,僅從數學上看,它確實如此,但這並不意味著真正的理解,理解了背後的原因後,你可能不一定需要數學工具就能解釋這一切,我相信任何復雜的理論背後都有一個不需要數學來解釋的原因。
在前面的討論中,我們知道數據包的到達率和服務率之比為1的時候,隊列長度將無限大!這不符合常理啊,如果說到達率為a,服務率也是a,這不正是守恆嗎?來一個處理一個,怎麼可能擠壓呢?另外,到達率和服務率之比的這個1/2是怎麼來的呢?
在我想闡釋這個悖論前,和以往一樣,先看看有沒有現成的解釋,於是發了一個知乎上不錯的解釋,也就省了我打字畫圖的時間了,鏈接如下《poisson到達的一個悖論怎麼解釋?》。看明白了嗎?
我這裡再給出另外一個解釋,我這裡基於令牌守恆的原理來解釋,希望能有所幫助。
附:令牌守恆解釋排隊論的悖論
我將到達過程和服務過程想象成物品的湧入過程以及令牌的發放和回收過程:
到達過程--物品按照速率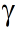 到達一個時間序列,單位時間到達的物品量符合泊松分布。
到達一個時間序列,單位時間到達的物品量符合泊松分布。
服務過程--服務者按照固定速率 在時間序列上發放令牌,如果該點上有物品(不管多少個),則最多帶走一個物品(因為只放一個令牌),如果沒有物品,則空放一個令牌。
在時間序列上發放令牌,如果該點上有物品(不管多少個),則最多帶走一個物品(因為只放一個令牌),如果沒有物品,則空放一個令牌。
我用一個圖來舉一個例子吧!把足夠長的時間縮短到一個有限的時間,假設到達率為3,服務率也是3,到達率符合離散的正態分布(泊松分布也是一樣的結果,這裡強調的只是,到達過程是統計的,而不是勻速的),時間段為8個單位時間,有了以上的假設,我們知道這段時間服務者會勻速放出3*8=24個令牌:
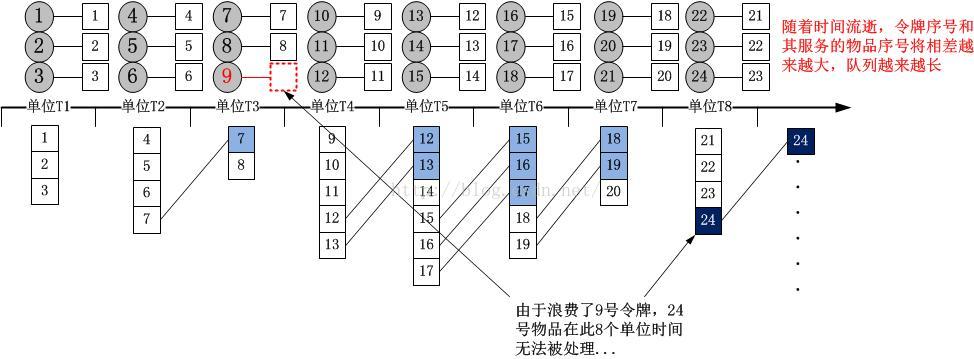
隨著時間流逝,隊列會越來越長,造成這種現象的原因在於,隊列的積壓和排空是不對稱的,服務方比到達方要強勢的多!對於到達方而言,如果恰好沒有服務方,就要安靜地排隊,而對於服務方而言,如果沒有到達方,它只是空轉,要知道,空轉是需要能量的!這是因為,到達的事件必須要被服務。(其實,在銀行大廳,你會發現不管有沒有客戶,總有服務台有辦事員等待,他們是要領工資的...這就是排隊的本質,到達方和服務方不對等!!)
這就是所謂的統計波動。有時候,這種效應可以跟短板效應(木桶)等價起來,這個在艾利.高德拉特的《目標》一書中也有闡述,意思是最慢的環節決定總體進度,我的理解就是:一步錯,步步錯!功不抵過!哈哈。
從這個悖論的分析可以看出網絡節點的隊列確實很脆弱,一不小心就排隊了,而且這個隊列在持續恆定到達率下幾乎不會被清空,反而會增長,這可能不太符合常識,但是統計學表明確實如此,要想清空隊列,必須減小到達率,或者動態增加服務率,也就是增加處理的功率。
結論是什麼呢?結論就是,排隊很容易發生,然而隊列的清空卻很難!在M/M/1模型中,可以證明,

的值大於0.8的時候,隊列就會快速增長到一個很長的穩定值。
好了,目前為止,我們對網絡中間的行為的已經理解得很透徹了,雖然只用了簡單化的M/M/1模型進行了分析,而事實上真實網絡上的模型要復雜的多,然而這對於理解問題的本質已經夠了。接下來我們要分析TCP發送端的反應了。這個反應非常重要,因為隊列的清空也就是擁塞的緩解,幾乎完全依賴與這種發送端的反應!
TCP端到端的行為
我們可以把TCP的擁塞控制機制看作是對上述網絡行為反饋的反應。反應或許可以分為三種,要麼激進,要麼保守,要麼無視之,但不管怎樣,TCP總是要對自己的反應付出代價,或者取得收益。
要知道的是,TCP的發送端對網絡現狀的了解總是有一些滯後性,就像CSMA/CD一樣,網絡擁塞信號傳遞到發送端最少要經過半個RTT的時間,經常會更久,我們知道,TCP發送端的數據發送是靠接收端的ACK來驅動的,即便在接收端附近發生了擁塞,數據包發生了排隊現象,從排隊開始到排隊結束的時間(假設沒有發生丟包),加上ACK返回發送端的半個RTT時間,總的擁塞信號反饋時間就是半個RTT加上排隊時間,而排隊時間我們可以從上一節排隊論分析中的公式(3)平均等待時延中得到,這個過程的時延將決定性地取決與排隊時延!如下圖所示:

對於TCP發送端而言,它會發現RTT變長了,事實上這個變長就是因為排隊引發的。發送端會根據這個RTT的反饋信號調整自己的行為,為了更加精確的反省(我沒有用預測這個詞,因為此時擁塞已經發生了)網絡中到底發生了什麼,對RTT測量值的統計是必要的,這就是我們接下來的內容。
抖動與噪點
如果觀察TCP發送端采集到RTT分布,會發現其波動性特別大,有時候RTT會異常升高,好像魔法一樣...如果理解了排隊時延公式的含義,就會很容易理解這個現象了,因為擁塞發生的時候,即便稍微增加一點流量(這意味著到達率的升高或者僅僅意味著路由器端口的服務率不是到達率的2倍,造成恆定的平均隊列長度的在均值上下波動),也會造成瞬時的排隊時延增加。如何從這些采樣值中看出一些端倪呢?比如說這些采樣值的抖動是持續擁塞導致還是偶爾的突發流量造成的時延噪點呢?就需要從這些采樣值中規劃出某種趨勢。在持續擁塞時,RTT表現為持續保持高值或者隨著隊列長度的加長而快速升高,然而在面對突發流量造成的排隊擁塞時,這些RTT表現為某些高值噪點。我們總不能用肉眼來觀察這些海量數據,因此需要某種計數來將這些表現歸納到某個數值代表的趨勢中,這就涉及到了低通濾波器的運用。
低通濾波
所謂的低通濾波的目的就是消除噪點震蕩,在模擬電路中,我們可以采用一個電感來實現,而對於高通濾波,則使用電容可以實現。這個在統計趨勢的時候怎麼做到呢?無外乎就是做到以下兩點:
1).如果這是一個持續的高值或低值,積累它;
2).如果這是一個偶爾的高值或低值,平滑它;
為了表達一種趨勢,這個濾波器必然是一個有狀態的設施,它可以將歷史值加權累加到當前值之上,以表達歷史的的趨勢。如今,應用比較廣泛的一個低通濾波器就是加權指數平均值,也叫做移動指數平均值。
移動指數平均的意義
首先給出公式:
V=(1-a)*V+(a)*Vnew
這實際上是一個遞推得來的式子,起初,V0是一個初始值x
V0=new0
V1=(1-a)*V0+a*new1=(1-a)*new0+new1
V2=(1-a)*V1+a*new2=(1-a)^2*new0+(1-a)*new1+a*new2
V3=(1-a)*V2+a*new3=(1-a)^3*new0+(1-a)^2*new1+(1-a)*new2+a*new3
V4=(1-a)*V3+a*new4=(1-a)^4*new0+(1-a)^3*new1+(1-a)^2*new2+(1-a)*new3+a*new4
V5=(1-a)*V4+a*new5=(1-a)^5*new0+(1-a)^4*new1+(1-a)^3*new2+(1-a)^2*new3+(1-a)*new4+a*new5
....
V[n]=(1-a)*V[n-1]+a*Vnew=(1-a)^n*new0+(1-a)^[n-1]*new1+(1-a)^[n-2]*new2+(1-a)^[n-3]*new3...a*Vnew[n]
可以看到,某次的瞬時值Vnew[n]的作用隨著時間的推薦指數級遞減,然而另一方面,它的遞減值確實是積累性的,這就既可以平滑掉瞬時值的作用,又可以將該瞬時值成為歷史值後做累加,最終的結果就保證低通濾波器要求的那兩點。
可以看出,關鍵在於系數a的選擇,這個a越大,表明瞬時值的影響越大(即便再大,也會被時間所遺忘)。a的取值一方面靠分析,一方面靠經驗和運氣!
RTT和RTO的計算
有了上面的利器,我們可以應付抖動的RTT了,當前主流的TCP實現中,均采用了上述的移動指數平均來計算RTT和RTO,RTT具體的算法就不說了,至於說瞬時RTT采樣的權值為什麼是1/8,應該是調得一手好參數的經驗值吧。
重點是RTO的計算,我們知道,RTO要比RTT略長一點,那麼到底長多少呢?早期的算法很簡單,就是RTT乘以一個大於1的系數,但是即便是平滑過的RTT反映了正常的擁塞排隊情況,也無法反映是瞬時突發隊列還是長期競流導致的擁塞隊列,因為這涉及到一個動態的過程。這是為什麼呢?為什麼無法反映呢?
因為我們自己在計算RTT的時候用移動平均算法將這種動態特征過濾掉了!這就是所謂“低通”的含義!!低意味著頻率低,也就是穩定的意思,而高則意味著頻率高,也就是抖動的含義。RTT到底該不該平滑掉動態特性呢?這要分兩個方面說:
對於指導窗口的調整:應該平滑掉動態特征
對於設置RTO:恰好要利用其動態高頻特征
RTO不能設置的比合理值大,這樣會降低性能,也不能比合理值小,這樣會增加不必要的重傳,恰恰用以下的原則來指導,如果RTT波動大,則設置的要大一點,如果波動小,就要設置的小一點。
這就正如除法得商取余數一樣美妙,什麼也不浪費,即使平滑掉了RTT的抖動,也可以再為其抖動特征求個標准差!
求RTT瞬時采樣值和移動指數平均的RTT做差,然後對此差值做移動指數平均作為設置RTO的標准。幾乎任何講網絡的書上都有這個,我不再重復書上的內容了。
FAST TCP對RTT的合理化優化
雖然我們知道,RTT在做移動指數平均的時候,1/8是一個奇妙的數字,“不知道怎麼來的,但是就是可以工作的很好!”,然而還是受到了挑戰。FAST TCP並不認為1/8是一個永恆的系數,它有其自己的算法,在另一篇文章中給出了:
4.2 avgRTT Computation
In [VJ88], the average weight for Exponential Weighted Moving Average
(EWMA) is 1/8. For high-speed long-distance network, smaller average
weight is recommended since, with a large window, successive RTT
samples capture congestion information over a timescale that is much
smaller than a RTT. Average RTT values should capture the state of a
network during the last window. We suggest an average weight that
is proportional to the reciprocal of cwnd:
weight = min{ 3/cwnd, 1/8 }
The average RTT is updated on the receipt of a new RTT sample,
as follows:
avgRTT_new = (1-weight)*avgRTT_old + weight*RTT
因此可以看到,它不光把RTT作為了網絡擁塞判斷的指標,還把窗口因素也算進去了,某種意義上,由於窗口在很短的時間間隔內不會陡升陡降,可以代表著上一次發送時的網絡情況,將這個和歷史的avgRTT_old就行加權是一個很好的想法,因為這裡面有一種Bloom Filter的意思。
如果一個判斷無法判斷出一個趨勢,那就找幾個正交的判斷一起來吧,如果這些判斷同時或者起碼絕大多數結果都反映了同一個趨勢,那就說明這個趨勢是一個必然的趨勢!
回到開始
我們回到開始Gaius Julius Caesar和拿破侖的話,我們看看
真實的RTT和
人們想看到的RTT: