


在 Linux 內核中主要有兩種類型的定時器。一類稱為 timeout 類型,另一類稱為 timer 類型。timeout 類型的定時器通常用於檢測各種錯誤條件,例如用於檢測網卡收發數據包是否會超時的定時器,IO 設備的讀寫是否會超時的定時器等等。通常情況下這些錯誤很少發生,因此,使用 timeout 類型的定時器一般在超時之前就會被移除,從而很少產生真正的函數調用和系統開銷。總的來說,使用 timeout 類型的定時器產生的系統開銷很小,它是下文提及的 timer wheel 通常使用的環境。此外,在使用 timeout 類型定時器的地方往往並不關心超時處理,因此超時精確與否,早 0.01 秒或者晚 0.01 秒並不十分重要,這在下文論述 deferrable timers 時會進一步介紹。timer 類型的定時器與 timeout 類型的定時器正相反,使用 timer 類型的定時器往往要求在精確的時鐘條件下完成特定的事件,通常是周期性的並且依賴超時機制進行處理。例如設備驅動通常會定時讀寫設備來進行數據交互。如何高效的管理 timer 類型的定時器對提高系統的處理效率十分重要,下文在介紹 hrtimer 時會有更加詳細的論述。
內核需要進行時鐘管理,離不開底層的硬件支持。在早期是通過 8253 芯片提供的 PIT(Programmable Interval Timer)來提供時鐘,但是 PIT 的頻率很低,只能提供最高 1ms 的時鐘精度,由於 PIT 觸發的中斷速度太慢,會導致很大的時延,對於像音視頻這類對時間精度要求更高的應用並不足夠,會極大的影響用戶體驗。隨著硬件平台的不斷發展變化,陸續出現了 TSC(Time Stamp Counter),HPET(High Precision Event Timer),ACPI PM Timer(ACPI Power Management Timer),CPU Local APIC Timer 等精度更高的時鐘。這些時鐘陸續被 Linux 的時鐘子系統所采納,從而不斷的提高 Linux 時鐘子系統的性能和靈活性。這些不同的時鐘會在下文不同的章節中分別進行介紹。
Timer wheel
在 Linux 2.6.16 之前,內核一直使用一種稱為 timer wheel 的機制來管理時鐘。這就是熟知的 kernel 一直采用的基於 HZ 的 timer 機制。Timer wheel 的核心數據結構如清單 1 所示:
清單 1. Timer wheel 的核心數據結構
#define TVN_BITS (CONFIG_BASE_SMALL ? 4 : 6)
#define TVR_BITS (CONFIG_BASE_SMALL ? 6 : 8)
#define TVN_SIZE (1 << TVN_BITS)
#define TVR_SIZE (1 << TVR_BITS)
#define TVN_MASK (TVN_SIZE - 1)
#define TVR_MASK (TVR_SIZE - 1)
struct tvec {
struct list_head vec[TVN_SIZE];
};
struct tvec_root {
struct list_head vec[TVR_SIZE];
};
struct tvec_base {
spinlock_t lock;
struct timer_list *running_timer;
unsigned long timer_jiffies;
unsigned long next_timer;
struct tvec_root tv1;
struct tvec tv2;
struct tvec tv3;
struct tvec tv4;
struct tvec tv5;
} ____cacheline_aligned;
以 CONFIG_BASE_SMALL 定義為 0 為例,TVR_SIZE = 256,TVN_SIZE = 64,這樣
可以得到如圖 1 所示的 timer wheel 的結構。
圖 1. Timer wheel 的邏輯結構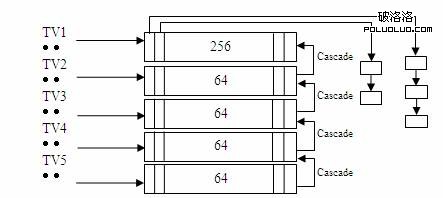
list_head的作用
list_head 是 Linux 內核使用的一個雙向循環鏈表表頭。任何一個需要使用鏈表的數據結構可以通過內嵌 list_head 的方式,將其鏈接在一起從而形成一個雙向鏈表。參見 list_head 在 include/Linux/list.h 中的定義和實現。
在 timer wheel 的框架下,所有系統正在使用的 timer 並不是順序存放在一個平坦的鏈表中,因為這樣做會使得查找,插入,刪除等操作效率低下。Timer wheel 提供了 5 個 timer 數組,數組之間存在著類似時分秒的進位關系。TV1 為第一個 timer 數組,其中存放著從 timer_jiffies(當前到期的 jiffies)到 timer_jiffies + 255 共 256 個 tick 對應的 timer list。因為在一個 tick 上可能同時有多個 timer 等待超時處理,timer wheel 使用 list_head 將所有 timer 串成一個鏈表,以便在超時時順序處理。TV2 有 64 個單元,每個單元都對應著 256 個 tick,因此 TV2 所表示的超時時間范圍從 timer_jiffies + 256 到 timer_jiffies + 256 * 64 – 1。依次類推 TV3,TV4,TV5。以 HZ=1000 為例,每 1ms 產生一次中斷,TV1 就會被訪問一次,但是 TV2 要每 256ms 才會被訪問一次,TV3 要 16s,TV4 要 17 分鐘,TV5 甚至要 19 小時才有機會檢查一次。最終,timer wheel 可以管理的最大超時值為 2^32。一共使用了 512 個 list_head(256+64+64+64+64)。如果 CONFIG_BASE_SMALL 定義為 1,則最終使用的 list_head 個數為 128 個(64+16+16+16+16),占用的內存更少,更適合嵌入式系統使用。Timer wheel 的處理邏輯如清單 2 所示:
清單 2. timer wheel 的核心處理函數
static inline void __run_timers(struct tvec_base *base)
{
struct timer_list *timer;
spin_lock_irq(&base->lock);
while (time_after_eq(jiffies, base->timer_jiffies)) {
struct list_head work_list;
struct list_head *head = &work_list;
int index = base->timer_jiffies & TVR_MASK;
/*
* Cascade timers:
*/
if (!index &&
(!cascade(base, &base->tv2, INDEX(0))) &&
(!cascade(base, &base->tv3, INDEX(1))) &&
!cascade(base, &base->tv4, INDEX(2)))
cascade(base, &base->tv5, INDEX(3));
++base->timer_jiffies;
list_replace_init(base->tv1.vec + index, &work_list);
while (!list_empty(head)) {
void (*fn)(unsigned long);
unsigned long data;
timer = list_first_entry(head, struct timer_list,entry);
fn = timer->function;
data = timer->data;
. . . .
fn(data);
. . . .
}
base->timer_jiffies 用來記錄在 TV1 中最接近超時的 tick 的位置。index 是用來遍歷 TV1 的索引。每一次循環 index 會定位一個當前待處理的 tick,並處理這個 tick 下所有超時的 timer。base->timer_jiffies 會在每次循環後增加一個 jiffy,index 也會隨之向前移動。當 index 變為 0 時表示 TV1 完成了一次完整的遍歷,此時所有在 TV1 中的 timer 都被處理了,因此需要通過 cascade 將後面 TV2,TV3 等 timer list 中的 timer 向前移動,類似於進位。這種層疊的 timer list 實現機制可以大大降低每次檢查超時 timer 的時間,每次中斷只需要針對 TV1 進行檢查,只有必要時才進行 cascade。即便如此,timer wheel 的實現機制仍然存在很大弊端。一個弊端就是 cascade 開銷過大。在極端的條件下,同時會有多個 TV 需要進行 cascade 處理,會產生很大的時延。這也是為什麼說 timeout 類型的定時器是 timer wheel 的主要應用環境,或者說 timer wheel 是為 timeout 類型的定時器優化的。因為 timeout 類型的定時器的應用場景多是錯誤條件的檢測,這類錯誤發生的機率很小,通常不到超時就被刪除了,因此不會產生 cascade 的開銷。另一方面,由於 timer wheel 是建立在 HZ 的基礎上的,因此其計時精度無法進一步提高。畢竟一味的通過提高 HZ 值來提高計時精度並無意義,結果只能是產生大量的定時中斷,增加額外的系統開銷。因此,有必要將高精度的 timer 與低精度的 timer 分開,這樣既可以確保低精度的 timeout 類型的定時器應用,也便於高精度的 timer 類型定時器的應用。還有一個重要的因素是 timer wheel 的實現與 jiffies 的耦合性太強,非常不便於擴展。因此,自從 2.6.16 開始,一個新的 timer 子系統 hrtimer 被加入到內核中。
hrtimer (High-resolution Timer)
hrtimer 首先要實現的功能就是要克服 timer wheel 的缺點:低精度以及與內核其他模塊的高耦合性。在正式介紹 hrtimer 之前,有必要先介紹幾個常用的基本概念:
時鐘源設備(clock-source device)
系統中可以提供一定精度的計時設備都可以作為時鐘源設備。如 TSC,HPET,ACPI PM-Timer,PIT 等。但是不同的時鐘源提供的時鐘精度是不一樣的。像 TSC,HPET 等時鐘源既支持高精度模式(high-resolution mode)也支持低精度模式(low-resolution mode),而 PIT 只能支持低精度模式。此外,時鐘源的計時都是單調遞增的(monotonically),如果時鐘源的計時出現翻轉(即返回到 0 值),很容易造成計時錯誤, 內核的一個 patch(commit id: ff69f2)就是處理這類問題的一個很好示例。時鐘源作為系統時鐘的提供者,在可靠並且可用的前提下精度越高越好。在 Linux 中不同的時鐘源有不同的 rating,具有更高 rating 的時鐘源會優先被系統使用。如圖 2 所示:
表 1. 時鐘源中 rating 的定義
1 ~ 99 100 ~ 199 200 ~ 299 300 ~ 399 400 ~ 499 非常差的時鐘源,只能作為最後的選擇。如 jiffies 基本可以使用但並非理想的時鐘源。如 PIT 正確可用的時鐘源。如 ACPI PM Timer,HPET 快速並且精確的時鐘源。如 TSC 理想時鐘源。如 kvm_clock,xen_clock
時鐘事件設備(clock-event device)
系統中可以觸發 one-shot(單次)或者周期性中斷的設備都可以作為時鐘事件設備。如 HPET,CPU Local APIC Timer 等。HPET 比較特別,它既可以做時鐘源設備也可以做時鐘事件設備。時鐘事件設備的類型分為全局和 per-CPU 兩種類型。全局的時鐘事件設備雖然附屬於某一個特定的 CPU 上,但是完成的是系統相關的工作,例如完成系統的 tick 更新;per-CPU 的時鐘事件設備主要完成 Local CPU 上的一些功能,例如對在當前 CPU 上運行進程的時間統計,profile,設置 Local CPU 上的下一次事件中斷等。和時鐘源設備的實現類似,時鐘事件設備也通過 rating 來區分優先級關系。
tick device
Tick device 用來處理周期性的 tick event。Tick device 其實是時鐘事件設備的一個 wrapper,因此 tick device 也有 one-shot 和周期性這兩種中斷觸發模式。每注冊一個時鐘事件設備,這個設備會自動被注冊為一個 tick device。全局的 tick device 用來更新諸如 jiffies 這樣的全局信息,per-CPU 的 tick device 則用來更新每個 CPU 相關的特定信息。
broadcast
CPU 的 C-STATE
CPU 在空閒時會根據空閒時間的長短選擇進入不同的睡眠級別,稱為 C-STATE。C0 為正常運行狀態,C1 到 C7 為睡眠狀態,數值越大,睡眠程度越深,也就越省電。CPU 空閒越久,進入睡眠的級別越高,但是喚醒所需的時間也越長。喚醒也是需要消耗能源的,因此,只有選擇合適的睡眠級別才能確保節能的最大化。
Broadcast 的出現是為了應對這樣一種情況:假定 CPU 使用 Local APIC Timer 作為 per-CPU 的 tick device,但是某些特定的 CPU(如 Intel 的 Westmere 之前的 CPU)在進入 C3+ 的狀態時 Local APIC Timer 也會同時停止工作,進入睡眠狀態。在這種情形下 broadcast 可以替代 Local APIC Timer 繼續完成統計進程的執行時間等有關操作。本質上 broadcast 是發送一個 IPI(Inter-processor interrupt)中斷給其他所有的 CPU,當目標 CPU 收到這個 IPI 中斷後就會調用原先 Local APIC Timer 正常工作時的中斷處理函數,從而實現了同樣的功能。目前主要在 x86 以及 MIPS 下會用到 broadcast 功能。
Timekeeping & GTOD (Generic Time-of-Day)
Timekeeping(可以理解為時間測量或者計時)是內核時間管理的一個核心組成部分。沒有 Timekeeping,就無法更新系統時間,維持系統“心跳”。GTOD 是一個通用的框架,用來實現諸如設置系統時間 gettimeofday 或者修改系統時間 settimeofday 等工作。為了實現以上功能,Linux 實現了多種與時間相關但用於不同目的的數據結構。
struct timespec {
__kernel_time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
timespec 精度是納秒。它用來保存從 00:00:00 GMT, 1 January 1970 開始經過的時間。內核使用全局變量 xtime 來記錄這一信息,這就是通常所說的“Wall Time”或者“Real Time”。與此對應的是“System Time”。System Time 是一個單調遞增的時間,每次系統啟動時從 0 開始計時。
struct timeval {
__kernel_time_t tv_sec; /* seconds */
__kernel_suseconds_t tv_usec; /* microseconds */
};
timeval 精度是微秒。timeval 主要用來指定一段時間間隔。
union ktime {
s64 tv64;
#if BITS_PER_LONG != 64 && !defined(CONFIG_KTIME_SCALAR)
struct {
# ifdef __BIG_ENDIAN
s32 sec, nsec;
# else
s32 nsec, sec;
# endif
} tv;
#endif
};
ktime_t 是 hrtimer 主要使用的時間結構。無論使用哪種體系結構,ktime_t 始終保持 64bit 的精度,並且考慮了大小端的影響。
typedef u64 cycle_t;
cycle_t 是從時鐘源設備中讀取的時鐘類型。
為了管理這些不同的時間結構,Linux 實現了一系列輔助函數來完成相互間的轉換。
ktime_to_timespec,ktime_to_timeval,ktime_to_ns/ktime_to_us,反過來有諸如 ns_to_ktime 等類似的函數。
timeval_to_ns,timespec_to_ns,反過來有諸如 ns_to_timeval 等類似的函數。
timeval_to_jiffies,timespec_to_jiffies,msecs_to_jiffies, usecs_to_jiffies, clock_t_to_jiffies 反過來有諸如 ns_to_timeval 等類似的函數。
clocksource_cyc2ns / cyclecounter_cyc2ns
有了以上的介紹,通過圖 3 可以更加清晰的看到這幾者之間的關聯。
圖 2. 內核時鐘子系統的結構關系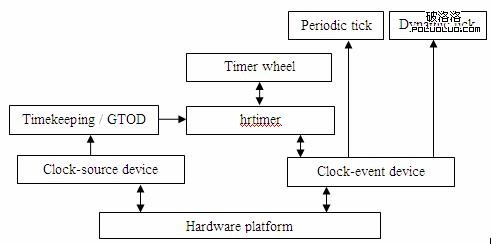
時鐘源設備和時鐘事件設備的引入,將原本放在各個體系結構中重復實現的冗余代碼封裝到各自的抽象層中,這樣做不但消除了原來 timer wheel 與內核其他模塊的緊耦合性,更重要的是系統可以在運行狀態動態更換時鐘源設備和時鐘事件設備而不影響系統正常使用,譬如當 CPU 由於睡眠要關閉當前使用的時鐘源設備或者時鐘事件設備時系統可以平滑的切換到其他仍處於工作狀態的設備上。Timekeeping/GTOD 在使用時鐘源設備的基礎上也采用類似的封裝實現了體系結構的無關性和通用性。hrtimer 則可以通過 timekeeping 提供的接口完成定時器的更新,通過時鐘事件設備提供的事件機制,完成對 timer 的管理。在圖 3 中還有一個重要的模塊就是 tick device 的抽象,尤其是 dynamic tick。Dynamic tick 的出現是為了能在系統空閒時通過停止 tick 的運行以達到降低 CPU 功耗的目的。使用 dynamic tick 的系統,只有在有實際工作時才會產生 tick,否則 tick 是處於停止狀態。下文會有專門的章節進行論述。
hrtimer 的實現機制
hrtimer 是建立在 per-CPU 時鐘事件設備上的,對於一個 SMP 系統,如果只有全局的時鐘事件設備,hrtimer 無法工作。因為如果沒有 per-CPU 時鐘事件設備,時鐘中斷發生時系統必須產生必要的 IPI 中斷來通知其他 CPU 完成相應的工作,而過多的 IPI 中斷會帶來很大的系統開銷,這樣會令使用 hrtimer 的代價太大,不如不用。為了支持 hrtimer,內核需要配置 CONFIG_HIGH_RES_TIMERS=y。hrtimer 有兩種工作模式:低精度模式(low-resolution mode)與高精度模式(high-resolution mode)。雖然 hrtimer 子系統是為高精度的 timer 准備的,但是系統可能在運行過程中動態切換到不同精度的時鐘源設備,因此,hrtimer 必須能夠在低精度模式與高精度模式下自由切換。由於低精度模式是建立在高精度模式之上的,因此即便系統只支持低精度模式,部分支持高精度模式的代碼仍然會編譯到內核當中。
在低精度模式下,hrtimer 的核心處理函數是 hrtimer_run_queues,每一次 tick 中斷都要執行一次。如清單 3 所示。這個函數的調用流程為:
update_process_times
run_local_timers
hrtimer_run_queues
raise_softirq(TIMER_SOFTIRQ)
清單 3. 低精度模式下 hrtimer 的核心處理函數
void hrtimer_run_queues(void)
{
struct rb_node *node;
struct hrtimer_cpu_base *cpu_base = &__get_cpu_var(hrtimer_bases);
struct hrtimer_clock_base *base;
int index, gettime = 1;
if (hrtimer_hres_active())
return;
for (index = 0; index < HRTIMER_MAX_CLOCK_BASES; index++) {
base = &cpu_base->clock_base[index];
if (!base->first)
continue;
if (gettime) {
hrtimer_get_softirq_time(cpu_base);
gettime = 0;
}
raw_spin_lock(&cpu_base->lock);
while ((node = base->first)) {
struct hrtimer *timer;
timer = rb_entry(node, struct hrtimer, node);
if (base->softirq_time.tv64 <=
hrtimer_get_expires_tv64(timer))
break;
__run_hrtimer(timer, &base->softirq_time);
}
raw_spin_unlock(&cpu_base->lock);
}
}
hrtimer_bases 是實現 hrtimer 的核心數據結構,通過 hrtimer_bases,hrtimer 可以管理掛在每一個 CPU 上的所有 timer。每個 CPU 上的 timer list 不再使用 timer wheel 中多級鏈表的實現方式,而是采用了紅黑樹(Red-Black Tree)來進行管理。hrtimer_bases 的定義如清單 4 所示:
清單 4. hrtimer_bases 的定義
DEFINE_PER_CPU(struct hrtimer_cpu_base, hrtimer_bases) =
{
.clock_base =
{
{
.index = CLOCK_REALTIME,
.get_time = &ktime_get_real,
.resolution = KTIME_LOW_RES,
},
{
.index = CLOCK_MONOTONIC,
.get_time = &ktime_get,
.resolution = KTIME_LOW_RES,
},
}
};
圖 4 展示了 hrtimer 如何通過 hrtimer_bases 來管理 timer。
圖 3. hrtimer 的時鐘管理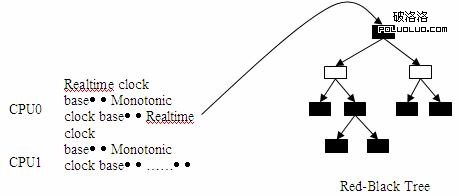
每個 hrtimer_bases 都包含兩個 clock_base,一個是 CLOCK_REALTIME 類型的,另一個是 CLOCK_MONOTONIC 類型的。hrtimer 可以選擇其中之一來設置 timer 的 expire time, 可以是實際的時間 , 也可以是相對系統運行的時間。
在 hrtimer_run_queues 的處理中,首先要通過 hrtimer_bases 找到正在執行當前中斷的 CPU 相關聯的 clock_base,然後逐個檢查每個 clock_base 上掛的 timer 是否超時。由於 timer 在添加到 clock_base 上時使用了紅黑樹,最早超時的 timer 被放到樹的最左側,因此尋找超時 timer 的過程非常迅速,找到的所有超時 timer 會被逐一處理。超時的 timer 根據其類型分為 softIRQ / per-CPU / unlocked 幾種。如果一個 timer 是 softIRQ 類型的,這個超時的 timer 需要被轉移到 hrtimer_bases 的 cb_pending 的 list 上,待 IRQ0 的軟中斷被激活後,通過 run_hrtimer_pending 執行,另外兩類則必須在 hardIRQ 中通過 __run_hrtimer 直接執行。不過在較新的 kernel(> 2.6.29)中,cb_pending 被取消,這樣所有的超時 timers 都必須在 hardIRQ 的 context 中執行。這樣修改的目的,一是為了簡化代碼邏輯,二是為了減少 2 次 context 的切換:一次從 hardIRQ 到 softIRQ,另一次從 softIRQ 到被超時 timer 喚醒的進程。
在 update_process_times 中,除了處理處於低精度模式的 hrtimer 外,還要喚醒 IRQ0 的 softIRQ(TIMER_SOFTIRQ(run_timer_softirq))以便執行 timer wheel 的代碼。由於 hrtimer 子系統的加入,在 IRQ0 的 softIRQ 中,還需要通過 hrtimer_run_pending 檢查是否可以將 hrtimer 切換到高精度模式,如清單 5 所示:
清單 5. hrtimer 進行精度切換的處理函數
void hrtimer_run_pending(void)
{
if (hrtimer_hres_active())
return;
/*
* This _is_ ugly: We have to check in the softirq context,
* whether we can switch to highres and / or nohz mode. The
* clocksource switch happens in the timer interrupt with
* xtime_lock held. Notification from there only sets the
* check bit in the tick_oneshot code, otherwise we might
* deadlock vs. xtime_lock.
*/
if (tick_check_oneshot_change(!hrtimer_is_hres_enabled()))
hrtimer_switch_to_hres();
}
正如這段代碼的作者注釋中所提到的,每一次觸發 IRQ0 的 softIRQ 都需要檢查一次是否可以將 hrtimer 切換到高精度,顯然是十分低效的,希望將來有更好的方法不用每次都進行檢查。
如果可以將 hrtimer 切換到高精度模式,則調用 hrtimer_switch_to_hres 函數進行切換。如清單 6 所示:
清單 6. hrtimer 切換到高精度模式的核心函數
/*
* Switch to high resolution mode
*/
static int hrtimer_switch_to_hres(void)
{
int cpu = smp_processor_id();
struct hrtimer_cpu_base *base = &per_cpu(hrtimer_bases, cpu);
unsigned long flags;
if (base->hres_active)
return 1;
local_irq_save(flags);
if (tick_init_highres()) {
local_irq_restore(flags);
printk(KERN_WARNING "Could not switch to high resolution "
"mode on CPU %d\n", cpu);
return 0;
}
base->hres_active = 1;
base->clock_base[CLOCK_REALTIME].resolution = KTIME_HIGH_RES;
base->clock_base[CLOCK_MONOTONIC].resolution = KTIME_HIGH_RES;
tick_setup_sched_timer();
/* "Retrigger" the interrupt to get things going */
retrigger_next_event(NULL);
local_irq_restore(flags);
return 1;
}
hrtimer_interrupt的使用環境
hrtimer_interrupt 有 2 種常見的使用方式。一是作為 tick 的推動器在產生 tick 中斷時被調用;另一種情況就是通過軟中斷 HRTIMER_SOFTIRQ(run_hrtimer_softirq)被調用,通常是被驅動程序或者間接的使用這些驅動程序的用戶程序所調用
在這個函數中,首先使用 tick_init_highres 更新與原來的 tick device 綁定的時鐘事件設備的 event handler,例如將在低精度模式下的工作函數 tick_handle_periodic / tick_handle_periodic_broadcast 換成 hrtimer_interrupt(它是 hrtimer 在高精度模式下的 timer 中斷處理函數),同時將 tick device 的觸發模式變為 one-shot,即單次觸發模式,這是使用 dynamic tick 或者 hrtimer 時 tick device 的工作模式。由於 dynamic tick 可以隨時停止和開始,以不規律的速度產生 tick,因此支持 one-shot 模式的時鐘事件設備是必須的;對於 hrtimer,由於 hrtimer 采用事件機制驅動 timer 前進,因此使用 one-shot 的觸發模式也是順理成章的。不過這樣一來,原本 tick device 每次執行中斷時需要完成的周期性任務如更新 jiffies / wall time (do_timer) 以及更新 process 的使用時間(update_process_times)等工作在切換到高精度模式之後就沒有了,因此在執行完 tick_init_highres 之後緊接著會調用 tick_setup_sched_timer 函數來完成這部分設置工作,如清單 7 所示:
清單 7. hrtimer 高精度模式下模擬周期運行的 tick device 的簡化實現
void tick_setup_sched_timer(void)
{
struct tick_sched *ts = &__get_cpu_var(tick_cpu_sched);
ktime_t now = ktime_get();
u64 offset;
/*
* Emulate tick processing via per-CPU hrtimers:
*/
hrtimer_init(&ts->sched_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS);
ts->sched_timer.function = tick_sched_timer;
. . . .
for (;;) {
hrtimer_forward(&ts->sched_timer, now, tick_period);
hrtimer_start_expires(&ts->sched_timer,
HRTIMER_MODE_ABS_PINNED);
/* Check, if the timer was already in the past */
if (hrtimer_active(&ts->sched_timer))
break;
now = ktime_get();
}
. . . .
}
這個函數使用 tick_cpu_sched 這個 per-CPU 變量來模擬原來 tick device 的功能。tick_cpu_sched 本身綁定了一個 hrtimer,這個 hrtimer 的超時值為下一個 tick,回調函數為 tick_sched_timer。因此,每過一個 tick,tick_sched_timer 就會被調用一次,在這個回調函數中首先完成原來 tick device 的工作,然後設置下一次的超時值為再下一個 tick,從而達到了模擬周期運行的 tick device 的功能。如果所有的 CPU 在同一時間點被喚醒,並發執行 tick 時可能會出現 lock 競爭以及 cache-line 沖突,為此 Linux 內核做了特別處理:如果假設 CPU 的個數為 N,則所有的 CPU 都在 tick_period 前 1/2 的時間內執行 tick 工作,並且每個 CPU 的執行間隔是 tick_period / (2N),見清單 8 所示:
清單 8. hrtimer 在高精度模式下 tick 執行周期的設置
void tick_setup_sched_timer(void)
{
. . . .
/* Get the next period (per cpu) */
hrtimer_set_expires(&ts->sched_timer, tick_init_jiffy_update());
offset = ktime_to_ns(tick_period) >> 1;
do_div(offset, num_possible_cpus());
offset *= smp_processor_id();
hrtimer_add_expires_ns(&ts->sched_timer, offset);
. . . .
}
回到 hrtimer_switch_to_hres 函數中,在一切准備就緒後,調用 retrigger_next_event 激活下一次的 timer 就可以開始正常的運作了。
隨著 hrtimer 子系統的發展,一些問題也逐漸暴露了出來。一個比較典型的問題就是 CPU 的功耗問題。現代 CPU 都實現了節能的特性,在沒有工作時 CPU 會主動降低頻率,關閉 CPU 內部一些非關鍵模塊以達到節能的目的。由於 hrtimer 的精度很高,觸發中斷的頻率也會很高,頻繁的中斷會極大的影響 CPU 的節能。在這方面 hrtimer 一直在不斷的進行調整。以下幾個例子都是針對這一問題所做的改進。
schedule_hrtimeout 函數
/**
* schedule_hrtimeout - sleep until timeout
* @expires: timeout value (ktime_t)
* @mode: timer mode, HRTIMER_MODE_ABS or HRTIMER_MODE_REL
*/
int __sched schedule_hrtimeout(ktime_t *expires, const enum hrtimer_mode mode)
schedule_hrtimeout 用來產生一個高精度的調度超時,以 ns 為單位。這樣可以更加細粒度的使用內核的調度器。在 Arjan van de Ven 的最初實現中,這個函數有一個很大的問題:由於其粒度很細,所以可能會更加頻繁的喚醒內核,導致消耗更多的能源。為了實現既能節省能源,又能確保精確的調度超時,Arjan van de Ven 的辦法是將一個超時點變成一個超時范圍。設置 hrtimer A 的超時值有一個上限,稱為 hard expire,在 hard expire 這個時間點上設置 hrtimer A 的超時中斷;同時設置 hrtimer A 的超時值有一個下限,稱為 soft expire。在 soft expire 到 hard expire 之間如果有一個 hrtimer B 的中斷被觸發,在 hrtimer B 的中斷處理函數中,內核會檢查是否有其他 hrtimer 的 soft expire 超時了,譬如 hrtimer A 的 soft expire 超時了,即使 hrtimer A 的 hard expire 沒有到,也可以順帶被處理。換言之,將原來必須在 hard expire 超時才能執行的一個點變成一個范圍後,可以盡量把 hrtimer 中斷放在一起處理,這樣 CPU 被重復喚醒的幾率會變小,從而達到節能的效果,同時這個 hrtimer 也可以保證其執行精度。
Deferrable timers & round jiffies
在內核中使用的某些 legacy timer 對於精確的超時值並不敏感,早一點或者晚一點執行並不會產生多大的影響,因此,如果可以把這些對時間不敏感同時超時時間又比較接近的 timer 收集在一起執行,可以進一步減少 CPU 被喚醒的次數,從而達到節能的目地。這正是引入 Deferrable timers 的目地。如果一個 timer 可以被短暫延時,那麼可以通過調用 init_timer_deferrable 設置 defer 標記,從而在執行時靈活選擇處理方式。不過,如果這些 timers 都被延時到同一個時間點上也不是最優的選擇,這樣同樣會產生 lock 競爭以及 cache-line 的問題。因此,即便將 defer timers 收集到一起,彼此之間也必須稍稍錯開一些以防止上述問題。這正是引入 round_jiffies 函數的原因。雖然這樣做會使得 CPU 被喚醒的次數稍多一些,但是由於間隔短,CPU 並不會進入很深的睡眠,這個代價還是可以接受的。由於 round_jiffies 需要在每次更新 timer 的超時值(mod_timer)時被調用,顯得有些繁瑣,因此又出現了更為便捷的 round jiffies 機制,稱為 timer slack。Timer slack 修改了 timer_list 的結構定義,將需要偏移的 jiffies 值保存在 timer_list 內部,通過 apply_slack 在每次更新 timer 的過程中自動更新超時值。apply_slack 的實現如清單 9 所示:
清單 9. apply_slack 的實現
/*
* Decide where to put the timer while taking the slack into account
*
* Algorithm:
* 1) calculate the maximum (absolute) time
* 2) calculate the highest bit where the expires and new max are different
* 3) use this bit to make a mask
* 4) use the bitmask to round down the maximum time, so that all last
* bits are zeros
*/
static inline
unsigned long apply_slack(struct timer_list *timer, unsigned long expires)
{
unsigned long expires_limit, mask;
int bit;
expires_limit = expires;
if (timer->slack >= 0) {
expires_limit = expires + timer->slack;
} else {
unsigned long now = jiffies; /* avoid reading jiffies twice */
/* if already expired, no slack; otherwise slack 0.4% */
if (time_after(expires, now))
expires_limit = expires + (expires - now)/256;
}
mask = expires ^ expires_limit;
if (mask == 0)
return expires;
bit = find_last_bit(&mask, BITS_PER_LONG);
mask = (1 << bit) - 1;
expires_limit = expires_limit & ~(mask);
return expires_limit;
}
隨著現代計算機系統的發展,對節能的需求越來越高,尤其是在使用筆記本,手持設備等移動環境是對節能要求更高。Linux 當然也會更加關注這方面的需求。hrtimer 子系統的優化盡量確保在使用高精度的時鐘的同時節約能源,如果系統在空閒時也可以盡量的節能,則 Linux 系統的節能優勢可以進一步放大。這也是引入 dynamic tick 的根本原因。
Dynamic tick & tickless
在 dynamic tick 引入之前,內核一直使用周期性的基於 HZ 的 tick。傳統的 tick 機制在系統進入空閒狀態時仍然會產生周期性的中斷,這種頻繁的中斷迫使 CPU 無法進入更深的睡眠。如果放開這個限制,在系統進入空閒時停止 tick,有工作時恢復 tick,實現完全自由的,根據需要產生 tick 的機制,可以使 CPU 獲得更多的睡眠機會以及更深的睡眠,從而進一步節能。dynamic tick 的出現,就是為徹底替換掉周期性的 tick 機制而產生的。周期性運行的 tick 機制需要完成諸如進程時間片的計算,更新 profile,協助 CPU 進行負載均衡等諸多工作,這些工作 dynamic tick 都提供了相應的模擬機制來完成。由於 dynamic tick 的實現需要內核的很多模塊的配合,包括了很多實現細節,這裡只介紹 dynamic tick 的核心工作機制,以及如何啟動和停止 dynamic tick。
Dynamic tick 的核心處理流程
從上文中可知內核時鐘子系統支持低精度和高精度兩種模式,因此 dynamic tick 也必須有兩套對應的處理機制。從清單 5 中可以得知,如果系統支持 hrtimer 的高精度模式,hrtimer 可以在此從低精度模式切換到高精度模式。其實清單 5 還有另外一個重要功能:它也是低精度模式下從周期性 tick 到 dynamic tick 的切換點。如果當前系統不支持高精度模式,系統會嘗試切換到 NOHZ 模式,也就是使用 dynamic tick 的模式,當然前提是內核使能了 NOHZ 模式。其核心處理函數如清單 10 所示。這個函數的調用流程如下:
tick_check_oneshot_change
tick_nohz_switch_to_nohz
tick_switch_to_oneshot(tick_nohz_handler)
清單 10. 低精度模式下 dynamic tick 的核心處理函數
static void tick_nohz_handler(struct clock_event_device *dev)
{
struct tick_sched *ts = &__get_cpu_var(tick_cpu_sched);
struct pt_regs *regs = get_irq_regs();
int cpu = smp_processor_id();
ktime_t now = ktime_get();
dev->next_event.tv64 = KTIME_MAX;
if (unlikely(tick_do_timer_cpu == TICK_DO_TIMER_NONE))
tick_do_timer_cpu = cpu;
/* Check, if the jiffies need an update */
if (tick_do_timer_cpu == cpu)
tick_do_update_jiffies64(now);
/*
* When we are idle and the tick is stopped, we have to touch
* the watchdog as we might not schedule for a really long
* time. This happens on complete idle SMP systems while
* waiting on the login prompt. We also increment the "start
* of idle" jiffy stamp so the idle accounting adjustment we
* do when we go busy again does not account too much ticks.
*/
if (ts->tick_stopped) {
touch_softlockup_watchdog();
ts->idle_jiffies++;
}
update_process_times(user_mode(regs));
profile_tick(CPU_PROFILING);
while (tick_nohz_reprogram(ts, now)) {
now = ktime_get();
tick_do_update_jiffies64(now);
}
}
在這個函數中,首先模擬周期性 tick device 完成類似的工作:如果當前 CPU 負責全局 tick device 的工作,則更新 jiffies,同時完成對本地 CPU 的進程時間統計等工作。如果當前 tick device 在此之前已經處於停止狀態,為了防止 tick 停止時間過長造成 watchdog 超時,從而引發 soft-lockdep 的錯誤,需要通過調用 touch_softlockup_watchdog 復位軟件看門狗防止其溢出。正如代碼中注釋所描述的,這種情況有可能出現在啟動完畢,完全空閒等待登錄的 SMP 系統上。最後需要設置下一次 tick 的超時時間。如果 tick_nohz_reprogram 執行時間超過了一個 jiffy,會導致設置的下一次超時時間已經過期,因此需要重新設置,相應的也需要再次更新 jiffies。這裡雖然設置了下一次的超時事件,但是由於系統空閒時會停止 tick,因此下一次的超時事件可能發生,也可能不發生。這也正是 dynamic tick 根本特性。
從清單 7 中可以看到,在高精度模式下 tick_sched_timer 用來模擬周期性 tick device 的功能。dynamic tick 的實現也使用了這個函數。這是因為 hrtimer 在高精度模式時必須使用 one-shot 模式的 tick device,這也同時符合 dynamic tick 的要求。雖然使用同樣的函數,表面上都會觸發周期性的 tick 中斷,但是使用 dynamic tick 的系統在空閒時會停止 tick 工作,因此 tick 中斷不會是周期產生的。
Dynamic tick 的開始和停止
當 CPU 進入空閒時是最好的時機。此時可以啟動 dynamic tick 機制,停止 tick;反之在 CPU 從空閒中恢復到工作狀態時,則可以停止 dynamic tick。見清單 11 所示:
清單 11. CPU 在 idle 時 dynamic tick 的啟動 / 停止設置
void cpu_idle(void)
{
. . . .
while (1) {
tick_nohz_stop_sched_tick(1);
while (!need_resched()) {
. . . .
}
tick_nohz_restart_sched_tick();
}
. . . .
}
timer 子系統的初始化過程
在分別了解了內核時鐘子系統各個模塊後,現在可以系統的介紹內核時鐘子系統的初始化過程。系統剛上電時,需要注冊 IRQ0 時鐘中斷,完成時鐘源設備,時鐘事件設備,tick device 等初始化操作並選擇合適的工作模式。由於剛啟動時沒有特別重要的任務要做,因此默認是進入低精度 + 周期 tick 的工作模式,之後會根據硬件的配置(如硬件上是否支持 HPET 等高精度 timer)和軟件的配置(如是否通過命令行參數或者內核配置使能了高精度 timer 等特性)進行切換。在一個支持 hrtimer 高精度模式並使能了 dynamic tick 的系統中,第一次發生 IRQ0 的軟中斷時 hrtimer 就會進行從低精度到高精度的切換,然後再進一步切換到 NOHZ 模式。IRQ0 為系統的時鐘中斷,使用全局的時鐘事件設備(global_clock_event)來處理的,其定義如下:
static struct irqaction irq0 = {
.handler = timer_interrupt,
.flags = IRQF_DISABLED | IRQF_NOBALANCING | IRQF_IRQPOLL | IRQF_TIMER,
.name = "timer"
};
它的中斷處理函數 timer_interrupt 的簡化實現如清單 12 所示:
清單 12. IRQ0 中斷處理函數的簡化實現
static irqreturn_t timer_interrupt(int irq, void *dev_id)
{
. . . .
global_clock_event->event_handler(global_clock_event);
. . . .
return IRQ_HANDLED;
}
在 global_clock_event->event_handler 的處理中,除了更新 local CPU 上運行進程時間的統計,profile 等工作,更重要的是要完成更新 jiffies 等全局操作。這個全局的時鐘事件設備的 event_handler 根據使用環境的不同,在低精度模式下可能是 tick_handle_periodic / tick_handle_periodic_broadcast,在高精度模式下是 hrtimer_interrupt。目前只有 HPET 或者 PIT 可以作為 global_clock_event 使用。其初始化流程清單 13 所示:
清單 13. timer 子系統的初始化流程
void __init time_init(void)
{
late_time_init = x86_late_time_init;
}
static __init void x86_late_time_init(void)
{
x86_init.timers.timer_init();
tsc_init();
}
/* x86_init.timers.timer_init 是指向 hpet_time_init 的回調指針 */
void __init hpet_time_init(void)
{
if (!hpet_enable())
setup_pit_timer();
setup_default_timer_irq();
}
由清單 13 可以看到,系統優先使用 HPET 作為 global_clock_event,只有在 HPET 沒有使能時,PIT 才有機會成為 global_clock_event。在使能 HPET 的過程中,HPET 會同時被注冊為時鐘源設備和時鐘事件設備。
hpet_enable
hpet_clocksource_register
hpet_legacy_clockevent_register
clockevents_register_device(&hpet_clockevent);
clockevent_register_device 會觸發 CLOCK_EVT_NOTIFY_ADD 事件,即創建對應的 tick device。然後在 tick_notify 這個事件處理函數中會添加新的 tick device。
clockevent_register_device trigger event CLOCK_EVT_NOTIFY_ADD
tick_notify receives event CLOCK_EVT_NOTIFY_ADD
tick_check_new_device
tick_setup_device
在 tick device 的設置過程中,會根據新加入的時鐘事件設備是否使用 broadcast 來分別設置 event_handler。對於 tick device 的處理函數,可見圖 5 所示:
表 2. tick device 在不同模式下的處理函數
low resolution mode High resolution mode periodic tick tick_handle_periodic hrtimer_interrupt dynamic tick tick_nohz_handler hrtimer_interrupt
另外,在系統運行的過程中,可以通過查看 /proc/timer_list 來顯示系統當前配置的所有時鐘的詳細情況,譬如當前系統活動的時鐘源設備,時鐘事件設備,tick device 等。也可以通過查看 /proc/timer_stats 來查看當前系統中所有正在使用的 timer 的統計信息。包括所有正在使用 timer 的進程,啟動 / 停止 timer 的函數,timer 使用的頻率等信息。內核需要配置 CONFIG_TIMER_STATS=y,而且在系統啟動時這個功能是關閉的,需要通過如下命令激活"echo 1 >/proc/timer_stats"。/proc/timer_stats 的顯示格式如下所示:
<count>, <pid> <command> <start_func> (<expire_func>)
總結
隨著應用環境的改變,使用需求的多樣化,Linux 的時鐘子系統也在不斷的衍變。為了更好的支持音視頻等對時間精度高的應用,Linux 提出了 hrtimer 這一高精度的時鐘子系統,為了節約能源,Linux 改變了長久以來一直使用的基於 HZ 的 tick 機制,采用了 tickless 系統。即使是在對硬件平台的支持上,也是在不斷改進。舉例來說,由於 TSC 精度高,是首選的時鐘源設備。但是現代 CPU 會在系統空閒時降低頻率以節約能源,從而導致 TSC 的頻率也會跟隨發生改變。這樣會導致 TSC 無法作為穩定的時鐘源設備使用。隨著新的 CPU 的出現,即使 CPU 的頻率發生變化,TSC 也可以一直維持在固定頻率上,從而確保其穩定性。在 Intel 的 Westmere 之前的 CPU 中,TSC 和 Local APIC Timer 類似,都會在 C3+ 狀態時進入睡眠,從而導致系統需要切換到其他較低精度的時鐘源設備上,但是在 Intel Westmere 之後的 CPU 中,TSC 可以一直保持運行狀態,即使 CPU 進入了 C3+ 的睡眠狀態,從而避免了時鐘源設備的切換。在 SMP 的環境下,尤其是 16-COREs,32-COREs 這樣的多 CPU 系統中,每個 CPU 之間的 TSC 很難保持同步,很容易出現“Out-of-Sync”。如果在這種環境下使用 TSC,會造成 CPU 之間的計時誤差,然而在 Intel 最新的 Nehalem-EX CPU 中,已經可以確保 TSC 在多個 CPU 之間保持同步,從而可以使用 TSC 作為首選的時鐘源設備。由此可見,無論是現在還是將來,只要有需要,內核的時鐘子系統就會一直向前發展。