


看書歸看書,寫程序是另外一件事情,上一篇文章裡把環境搭建起來了,可是我還是不知道怎麼創建CUDA工程,怎麼動手開始寫程序。還好CUDA提供了一個SDK,裡面有很多的實例可以供我們參考,於是乎,我的第一個CUDA程序就從這裡開始了。
CUDA SDK的實例都在src目錄下,每一個實例都有一個自己的目錄,例如deviceuery,在它的目錄下還有一個編譯時候使用的Makefile文件,這是編譯單個項目的。現在我們將所有實例都編譯一遍,在CUDA_SDK根目錄下運行sudo make之後,可以在 <CUDA_SDK_HOME>/bin/linux/release下看到編譯之後的可執行程序,運行即可看到結果。
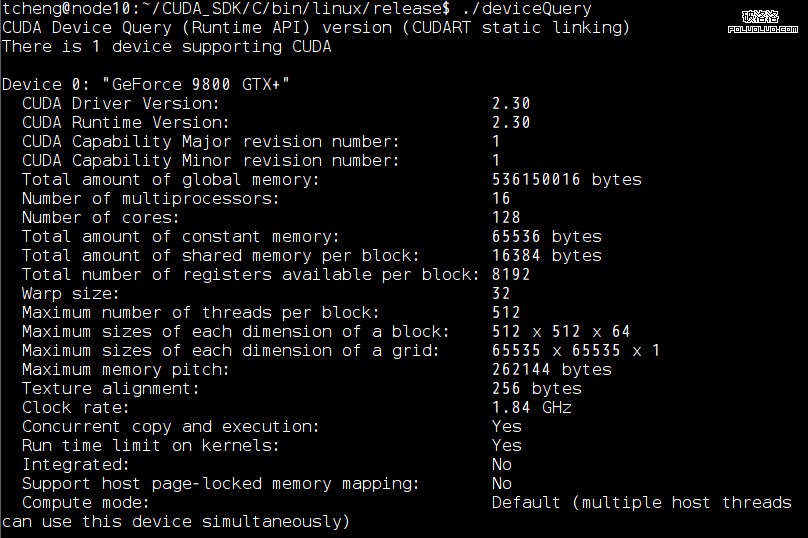
這是deviceQuery的運行結果:
那麼到這裡相信讀者應該想到了我們完全可以利用這些實例來創建我們自己的工程。再實例中有一個template,將該目錄下src中的.cu、.cpp文件刪除,將obj目錄下的內容清空,這就成為一個空的CUDA工程,可以再src下編寫程序,然後在Makefie中將編譯的文件名修改正確,編譯即可。所生成的執行文件在CUDA_SDK_HOME/bin/linux/release下。這裡是一個測試代碼,執行矩陣加法運算的:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 #include <cuda_runtime.h>
5 #include <cutil.h>
6
7 #define VEC_SIZE 16
8
9 //kernel function
10 __global__ void vecAdd(float* d_A,float* d_B,float* d_C)
11 {
12 int index=threadIdx.x;
13 d_C[index]=d_A[index]+d_B[index];
14 }
15
16 int main()
17 {
18 //得到分配空間的大小
19 size_t size=VEC_SIZE*sizeof(float);
20
21 //為本地分配內存
22 float* h_A=(float*)malloc(size);
23 float* h_B=(float*)malloc(size);
24 float* h_C=(float*)malloc(size);
25
26 //初始化
27 for (int i=0;i<VEC_SIZE;++i)
28 {
29 h_A[i]=1.0;
30 h_B[i]=2.0;
31 }
32
33 //將本地內存的中的數據復制到設備中
34 float* d_A;
35 cudaMalloc((void**)&d_A,size);
36 cudaMemcpy(d_A,h_A,size,cudaMemcpyHostToDevice);
37
38 float* d_B;
39 cudaMalloc((void**)&d_B,size);
40 cudaMemcpy(d_B,h_B,size,cudaMemcpyHostToDevice);
41
42 //分配存放結果的空間
43 float* d_C;
44 cudaMalloc((void**)&d_C,size);
45
46 //定義16個線程
47 dim3 dimblock(16);
48 vecAdd<<<1,dimblock>>>(d_A,d_B,d_C);
49
50 //講計算結果復制回主存中
51 cudaMemcpy(h_C,d_C,size,cudaMemcpyDeviceToHost);
52
53 &
nbsp; //輸出計算結果
54 for (int j=0;j<VEC_SIZE;++j)
55 {
56 printf("%f\t",h_C[j]);
57 }
58
59 //釋放主機和設備內存
60 cudaFree(d_A);
61 cudaFree(d_B);
62 cudaFree(d_C);
63
64 free(h_A);
65 free(h_B);
66 free(h_C);
67
68 return 0;
69 }