


Docker這麼火,喜歡技術的朋友可能也會想,如果要自己實現一個資源隔離的容器,應該從哪些方面下手呢?也許你第一反應可能就是chroot命 令,這條命令給用戶最直觀的感覺就是使用後根目錄/的掛載點切換了,即文件系統被隔離了。然後,為了在分布式的環境下進行通信和定位,容器必然需要一個獨 立的IP、端口、路由等等,自然就想到了網絡的隔離。同時,你的容器還需要一個獨立的主機名以便在網絡中標識自己。想到網絡,順其自然就想到通信,也就想 到了進程間通信的隔離。可能你也想到了權限的問題,對用戶和用戶組的隔離就實現了用戶權限的隔離。最後,運行在容器中的應用需要有自己的PID,自然也需 要與宿主機中的PID進行隔離。
由此,我們基本上完成了一個容器所需要做的六項隔離,Linux內核中就提供了這六種namespace隔離的系統調用,如下表所示。
Namespace
系統調用參數
隔離內容
UTS
CLONE_NEWUTS
主機名與域名
IPC
CLONE_NEWIPC
信號量、消息隊列和共享內存
PID
CLONE_NEWPID
進程編號
Network
CLONE_NEWNET
網絡設備、網絡棧、端口等等
Mount
CLONE_NEWNS
掛載點(文件系統)
User
CLONE_NEWUSER
用戶和用戶組
表 namespace六項隔離
實際上,Linux內核實現namespace的主要目的就是為了實現輕量級虛擬化(容器)服務。在同一個namespace下的進程可以感知彼此 的變化,而對外界的進程一無所知。這樣就可以讓容器中的進程產生錯覺,仿佛自己置身於一個獨立的系統環境中,以此達到獨立和隔離的目的。
需要說明的是,本文所討論的namespace實現針對的均是Linux內核3.8及其以後的版本。接下來,我們將首先介紹使用namespace的API,然後針對這六種namespace進行逐一講解,並通過程序讓你親身感受一下這些隔離效果{![參考自http://lwn.net/Articles/531114/]}。
namespace的API包括clone()、setns()以及unshare(),還有/proc下的部分文件。為了確定隔離的到底是哪種 namespace,在使用這些API時,通常需要指定以下六個常數的一個或多個,通過|(位或)操作來實現。你可能已經在上面的表格中注意到,這六個參 數分別是CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER和 CLONE_NEWUTS。
使用clone()來創建一個獨立namespace的進程是最常見做法,它的調用方式如下。
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
clone()實際上是傳統UNIX系統調用fork()的一種更通用的實現方式,它可以通過flags來控制使用多少功能。一共有二十多種 CLONE_*的flag(標志位)參數用來控制clone進程的方方面面(如是否與父進程共享虛擬內存等等),下面外面逐一講解clone函數傳入的參 數。
在後續的內容中將會有使用clone()的實際程序可供大家參考。
從3.8版本的內核開始,用戶就可以在/proc/[pid]/ns文件下看到指向不同namespace號的文件,效果如下所示,形如[4026531839]者即為namespace號。
$ ls -l /proc/$$/ns <<-- $$ 表示應用的PID total 0 lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 ipc -> ipc:[4026531839] lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 mnt -> mnt:[4026531840] lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 net -> net:[4026531956] lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 pid -> pid:[4026531836] lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 user->user:[4026531837] lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 uts -> uts:[4026531838]
如果兩個進程指向的namespace編號相同,就說明他們在同一個namespace下,否則則在不同namespace裡面。/proc /[pid]/ns的另外一個作用是,一旦文件被打開,只要打開的文件描述符(fd)存在,那麼就算PID所屬的所有進程都已經結束,創建的 namespace就會一直存在。那如何打開文件描述符呢?把/proc/[pid]/ns目錄掛載起來就可以達到這個效果,命令如下。
# touch ~/uts # mount --bind /proc/27514/ns/uts ~/uts
如果你看到的內容與本文所描述的不符,那麼說明你使用的內核在3.8版本以前。該目錄下存在的只有ipc、net和uts,並且以硬鏈接存在。
上文剛提到,在進程都結束的情況下,也可以通過掛載的形式把namespace保留下來,保留namespace的目的自然是為以後有進程加入做准備。通過setns()系統調用,你的進程從原先的namespace加入我們准備好的新namespace,使用方法如下。
int setns(int fd, int nstype);
為了把我們創建的namespace利用起來,我們需要引入execve()系列函數,這個函數可以執行用戶命令,最常用的就是調用/bin/bash並接受參數,運行起一個shell,用法如下。
fd = open(argv[1], O_RDONLY); /* 獲取namespace文件描述符 */ setns(fd, 0); /* 加入新的namespace */ execvp(argv[2], &argv[2]); /* 執行程序 */
假設編譯後的程序名稱為setns。
# ./setns ~/uts /bin/bash # ~/uts 是綁定的/proc/27514/ns/uts
至此,你就可以在新的命名空間中執行shell命令了,在下文中會多次使用這種方式來演示隔離的效果。
最後要提的系統調用是unshare(),它跟clone()很像,不同的是,unshare()運行在原先的進程上,不需要啟動一個新進程,使用方法如下。
int unshare(int flags);
調用unshare()的主要作用就是不啟動一個新進程就可以起到隔離的效果,相當於跳出原先的namespace進行操作。這樣,你就可以在原進 程進行一些需要隔離的操作。Linux中自帶的unshare命令,就是通過unshare()系統調用實現的,有興趣的讀者可以在網上搜索一下這個命令 的作用。
系統調用函數fork()並不屬於namespace的API,所以這部分內容屬於延伸閱讀,如果讀者已經對fork()有足夠的了解,那大可跳過。
當程序調用fork()函數時,系統會創建新的進程,為其分配資源,例如存儲數據和代碼的空間。然後把原來的進程的所有值都復制到新的進程中,只有少量數值與原來的進程值不同,相當於克隆了一個自己。那麼程序的後續代碼邏輯要如何區分自己是新進程還是父進程呢?
fork()的神奇之處在於它僅僅被調用一次,卻能夠返回兩次(父進程與子進程各返回一次),通過返回值的不同就可以進行區分父進程與子進程。它可能有三種不同的返回值:
下面給出一段實例代碼,命名為fork_example.c。
#include <unistd.h>
#include <stdio.h>
int main (){
pid_t fpid; //fpid表示fork函數返回的值
int count=0;
fpid=fork();
if (fpid < 0)printf("error in fork!");
else if (fpid == 0) {
printf("I am child. Process id is %d/n",getpid());
}
else {
printf("i am parent. Process id is %d/n",getpid());
}
return 0;
}
編譯並執行,結果如下。
root@local:~# gcc -Wall fork_example.c && ./a.out I am parent. Process id is 28365 I am child. Process id is 28366
使用fork()後,父進程有義務監控子進程的運行狀態,並在子進程退出後自己才能正常退出,否則子進程就會成為“孤兒”進程。
下面我們將分別對六種namespace進行詳細解析。
UTS namespace提供了主機名和域名的隔離,這樣每個容器就可以擁有了獨立的主機名和域名,在網絡上可以被視作一個獨立的節點而非宿主機上的一個進程。
下面我們通過代碼來感受一下UTS隔離的效果,首先需要一個程序的骨架,如下所示。打開編輯器創建uts.c文件,輸入如下代碼。
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子進程中!\n");
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序開始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}
編譯並運行上述代碼,執行如下命令,效果如下。
root@local:~# gcc -Wall uts.c -o uts.o && ./uts.o 程序開始: 在子進程中! root@local:~# exit exit 已退出 root@local:~#
下面,我們將修改代碼,加入UTS隔離。運行代碼需要root權限,為了防止普通用戶任意修改系統主機名導致set-user-ID相關的應用運行出錯。
//[...]
int child_main(void* arg) {
printf("在子進程中!\n");
sethostname("Changed Namespace", 12);
execv(child_args[0], child_args);
return 1;
}
int main() {
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWUTS | SIGCHLD, NULL);
//[...]
}
再次運行可以看到hostname已經變化。
root@local:~# gcc -Wall namespace.c -o main.o && ./main.o 程序開始: 在子進程中! root@NewNamespace:~# exit exit 已退出 root@local:~# <- 回到原來的hostname
也許有讀者試著不加CLONE_NEWUTS參數運行上述代碼,發現主機名也變了,輸入exit以後主機名也會變回來,似乎沒什麼區別。實際上不加 CLONE_NEWUTS參數進行隔離而使用sethostname已經把宿主機的主機名改掉了。你看到exit退出後還原只是因為bash只在剛登錄的 時候讀取一次UTS,當你重新登陸或者使用uname命令進行查看時,就會發現產生了變化。
Docker中,每個鏡像基本都以自己所提供的服務命名了自己的hostname而沒有對宿主機產生任何影響,用的就是這個原理。
容器中進程間通信采用的方法包括常見的信號量、消息隊列和共享內存。然而與虛擬機不同的是,容器內部進程間通信對宿主機來說,實際上是具有相同 PID namespace中的進程間通信,因此需要一個唯一的標識符來進行區別。申請IPC資源就申請了這樣一個全局唯一的32位ID,所以IPC namespace中實際上包含了系統IPC標識符以及實現POSIX消息隊列的文件系統。在同一個IPC namespace下的進程彼此可見,而與其他的IPC namespace下的進程則互相不可見。
IPC namespace在代碼上的變化與UTS namespace相似,只是標識位有所變化,需要加上CLONE_NEWIPC參數。主要改動如下,其他部位不變,程序名稱改為ipc.c。{測試方法參考自:http://crosbymichael.com/creating-containers-part-1.html}
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
//[...]
我們首先在shell中使用ipcmk -Q命令創建一個message queue。
root@local:~# ipcmk -Q Message queue id: 32769
通過ipcs -q可以查看到已經開啟的message queue,序號為32769。
root@local:~# ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages 0x4cf5e29f 32769 root 644 0 0
然後我們可以編譯運行加入了IPC namespace隔離的ipc.c,在新建的子進程中調用的shell中執行ipcs -q查看message queue。
root@local:~# gcc -Wall ipc.c -o ipc.o && ./ipc.o 程序開始: 在子進程中! root@NewNamespace:~# ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages root@NewNamespace:~# exit exit 已退出
上面的結果顯示中可以發現,已經找不到原先聲明的message queue,實現了IPC的隔離。
目前使用IPC namespace機制的系統不多,其中比較有名的有PostgreSQL。Docker本身通過socket或tcp進行通信。
PID namespace隔離非常實用,它對進程PID重新標號,即兩個不同namespace下的進程可以有同一個PID。每個PID namespace都有自己的計數程序。內核為所有的PID namespace維護了一個樹狀結構,最頂層的是系統初始時創建的,我們稱之為root namespace。他創建的新PID namespace就稱之為child namespace(樹的子節點),而原先的PID namespace就是新創建的PID namespace的parent namespace(樹的父節點)。通過這種方式,不同的PID namespaces會形成一個等級體系。所屬的父節點可以看到子節點中的進程,並可以通過信號量等方式對子節點中的進程產生影響。反過來,子節點不能看 到父節點PID namespace中的任何內容。由此產生如下結論{![部分內容引自:http://blog.dotcloud.com/under-the-hood-linux-kernels-on-dotcloud-part]}。
到這裡,可能你已經聯想到一種在外部監控Docker中運行程序的方法了,就是監控Docker Daemon所在的PID namespace下的所有進程即其子進程,再進行刪選即可。
下面我們通過運行代碼來感受一下PID namespace的隔離效果。修改上文的代碼,加入PID namespace的標識位,並把程序命名為pid.c。
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS
| SIGCHLD, NULL);
//[...]
編譯運行可以看到如下結果。
root@local:~# gcc -Wall pid.c -o pid.o && ./pid.o 程序開始: 在子進程中! root@NewNamespace:~# echo $$ 1 <<--注意此處看到shell的PID變成了1 root@NewNamespace:~# exit exit 已退出
打印$$可以看到shell的PID,退出後如果再次執行可以看到效果如下。
root@local:~# echo $$ 17542
已經回到了正常狀態。可能有的讀者在子進程的shell中執行了ps aux/top之類的命令,發現還是可以看到所有父進程的PID,那是因為我們還沒有對文件系統進行隔離,ps/top之類的命令調用的是真實系統下的/proc文件內容,看到的自然是所有的進程。
此外,與其他的namespace不同的是,為了實現一個穩定安全的容器,PID namespace還需要進行一些額外的工作才能確保其中的進程運行順利。
當我們新建一個PID namespace時,默認啟動的進程PID為1。我們知道,在傳統的UNIX系統中,PID為1的進程是init,地位非常特殊。他作為所有進程的父進 程,維護一張進程表,不斷檢查進程的狀態,一旦有某個子進程因為程序錯誤成為了“孤兒”進程,init就會負責回收資源並結束這個子進程。所以在你要實現 的容器中,啟動的第一個進程也需要實現類似init的功能,維護所有後續啟動進程的運行狀態。
看到這裡,可能讀者已經明白了內核設計的良苦用心。PID namespace維護這樣一個樹狀結構,非常有利於系統的資源監控與回收。Docker啟動時,第一個進程也是這樣,實現了進程監控和資源回收,它就是dockerinit。
PID namespace中的init進程如此特殊,自然內核也為他賦予了特權——信號量屏蔽。如果init中沒有寫處理某個信號量的代碼邏輯,那麼與init 在同一個PID namespace下的進程(即使有超級權限)發送給它的該信號量都會被屏蔽。這個功能的主要作用是防止init進程被誤殺。
那麼其父節點PID namespace中的進程發送同樣的信號量會被忽略嗎?父節點中的進程發送的信號量,如果不是SIGKILL(銷毀進程)或SIGSTOP(暫停進程) 也會被忽略。但如果發送SIGKILL或SIGSTOP,子節點的init會強制執行(無法通過代碼捕捉進行特殊處理),也就是說父節點中的進程有權終止 子節點中的進程。
一旦init進程被銷毀,同一PID namespace中的其他進程也會隨之接收到SIGKILL信號量而被銷毀。理論上,該PID namespace自然也就不復存在了。但是如果/proc/[pid]/ns/pid處於被掛載或者打開狀態,namespace就會被保留下來。然 而,保留下來的namespace無法通過setns()或者fork()創建進程,所以實際上並沒有什麼作用。
我們常說,Docker一旦啟動就有進程在運行,不存在不包含任何進程的Docker,也就是這個道理。
前文中已經提到,如果你在新的PID namespace中使用ps命令查看,看到的還是所有的進程,因為與PID直接相關的/proc文件系統(procfs)沒有掛載到與原/proc不同 的位置。所以如果你只想看到PID namespace本身應該看到的進程,需要重新掛載/proc,命令如下。
root@NewNamespace:~# mount -t proc proc /proc
root@NewNamespace:~# ps a
PID TTY STAT TIME COMMAND
1 pts/1 S 0:00 /bin/bash
12 pts/1 R+ 0:00 ps a
可以看到實際的PID namespace就只有兩個進程在運行。
注意:因為此時我們沒有進行mount namespace的隔離,所以這一步操作實際上已經影響了 root namespace的文件系統,當你退出新建的PID namespace以後再執行ps a就會發現出錯,再次執行mount -t proc proc /proc可以修復錯誤。
在開篇我們就講到了unshare()和setns()這兩個API,而這兩個API在PID namespace中使用時,也有一些特別之處需要注意。
unshare()允許用戶在原有進程中建立namespace進行隔離。但是創建了PID namespace後,原先unshare()調用者進程並不進入新的PID namespace,接下來創建的子進程才會進入新的namespace,這個子進程也就隨之成為新namespace中的init進程。
類似的,調用setns()創建新PID namespace時,調用者進程也不進入新的PID namespace,而是隨後創建的子進程進入。
為什麼創建其他namespace時unshare()和setns()會直接進入新的namespace而唯獨PID namespace不是如此呢?因為調用getpid()函數得到的PID是根據調用者所在的PID namespace而決定返回哪個PID,進入新的PID namespace會導致PID產生變化。而對用戶態的程序和庫函數來說,他們都認為進程的PID是一個常量,PID的變化會引起這些進程奔潰。
換句話說,一旦程序進程創建以後,那麼它的PID namespace的關系就確定下來了,進程不會變更他們對應的PID namespace。
Mount namespace通過隔離文件系統掛載點對隔離文件系統提供支持,它是歷史上第一個Linux namespace,所以它的標識位比較特殊,就是CLONE_NEWNS。隔離後,不同mount namespace中的文件結構發生變化也互不影響。你可以通過/proc/[pid]/mounts查看到所有掛載在當前namespace中的文件系 統,還可以通過/proc/[pid]/mountstats看到mount namespace中文件設備的統計信息,包括掛載文件的名字、文件系統類型、掛載位置等等。
進程在創建mount namespace時,會把當前的文件結構復制給新的namespace。新namespace中的所有mount操作都只影響自身的文件系統,而對外界 不會產生任何影響。這樣做非常嚴格地實現了隔離,但是某些情況可能並不適用。比如父節點namespace中的進程掛載了一張CD-ROM,這時子節點 namespace拷貝的目錄結構就無法自動掛載上這張CD-ROM,因為這種操作會影響到父節點的文件系統。
2006 年引入的掛載傳播(mount propagation)解決了這個問題,掛載傳播定義了掛載對象(mount object)之間的關系,系統用這些關系決定任何掛載對象中的掛載事件如何傳播到其他掛載對象{![參考自:http://www.ibm.com/developerworks/library/l-mount-namespaces/]}。所謂傳播事件,是指由一個掛載對象的狀態變化導致的其它掛載對象的掛載與解除掛載動作的事件。
一個掛載狀態可能為如下的其中一種:
傳播事件的掛載對象稱為共享掛載(shared mount);接收傳播事件的掛載對象稱為從屬掛載(slave mount)。既不傳播也不接收傳播事件的掛載對象稱為私有掛載(private mount)。另一種特殊的掛載對象稱為不可綁定的掛載(unbindable mount),它們與私有掛載相似,但是不允許執行綁定掛載,即創建mount namespace時這塊文件對象不可被復制。
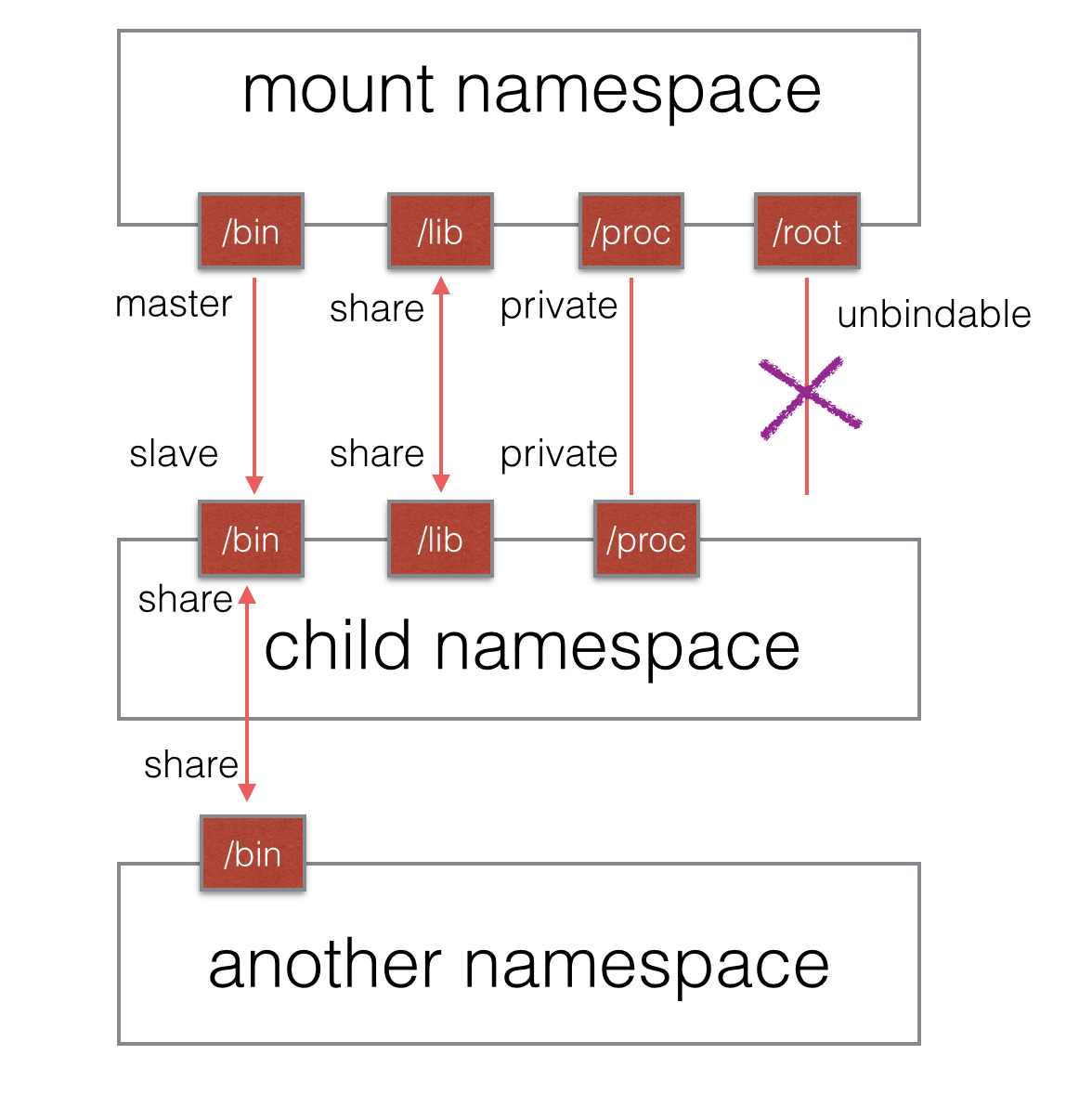
圖1 mount各類掛載狀態示意圖
共享掛載的應用場景非常明顯,就是為了文件數據的共享所必須存在的一種掛載方式;從屬掛載更大的意義在於某些“只讀”場景;私有掛載其實就是純粹的 隔離,作為一個獨立的個體而存在;不可綁定掛載則有助於防止沒有必要的文件拷貝,如某個用戶數據目錄,當根目錄被遞歸式的復制時,用戶目錄無論從隱私還是 實際用途考慮都需要有一個不可被復制的選項。
默認情況下,所有掛載都是私有的。設置為共享掛載的命令如下。
mount --make-shared <mount-object>
從共享掛載克隆的掛載對象也是共享的掛載;它們相互傳播掛載事件。
設置為從屬掛載的命令如下。
mount --make-slave <shared-mount-object>
從從屬掛載克隆的掛載對象也是從屬的掛載,它也從屬於原來的從屬掛載的主掛載對象。
將一個從屬掛載對象設置為共享/從屬掛載,可以執行如下命令或者將其移動到一個共享掛載對象下。
mount --make-shared <slave-mount-object>
如果你想把修改過的掛載對象重新標記為私有的,可以執行如下命令。
mount --make-private <mount-object>
通過執行以下命令,可以將掛載對象標記為不可綁定的。
mount --make-unbindable <mount-object>
這些設置都可以遞歸式地應用到所有子目錄中,如果讀者感興趣可以搜索到相關的命令。
在代碼中實現mount namespace隔離與其他namespace類似,加上CLONE_NEWNS標識位即可。讓我們再次修改代碼,並且另存為mount.c進行編譯運行。
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC
| CLONE_NEWUTS | SIGCHLD, NULL);
//[...]
執行的效果就如同PID namespace一節中“掛載proc文件系統”的執行結果,區別就是退出mount namespace以後,root namespace的文件系統不會被破壞,此處就不再演示了。
通過上節,我們了解了PID namespace,當我們興致勃勃地在新建的namespace中啟動一個“Apache”進程時,卻出現了“80端口已被占用”的錯誤,原來主機上已 經運行了一個“Apache”進程。怎麼辦?這就需要用到network namespace技術進行網絡隔離啦。
Network namespace主要提供了關於網絡資源的隔離,包括網絡設備、IPv4和IPv6協議棧、IP路由表、防火牆、/proc/net目錄、/sys /class/net目錄、端口(socket)等等。一個物理的網絡設備最多存在在一個network namespace中,你可以通過創建veth pair(虛擬網絡設備對:有兩端,類似管道,如果數據從一端傳入另一端也能接收到,反之亦然)在不同的network namespace間創建通道,以此達到通信的目的。
一般情況下,物理網絡設備都分配在最初的root namespace(表示系統默認的namespace,在PID namespace中已經提及)中。但是如果你有多塊物理網卡,也可以把其中一塊或多塊分配給新創建的network namespace。需要注意的是,當新創建的network namespace被釋放時(所有內部的進程都終止並且namespace文件沒有被掛載或打開),在這個namespace中的物理網卡會返回到 root namespace而非創建該進程的父進程所在的network namespace。
當我們說到network namespace時,其實我們指的未必是真正的網絡隔離,而是把網絡獨立出來,給外部用戶一種透明的感覺,仿佛跟另外一個網絡實體在進行通信。為了達到 這個目的,容器的經典做法就是創建一個veth pair,一端放置在新的namespace中,通常命名為eth0,一端放在原先的namespace中連接物理網絡設備,再通過網橋把別的設備連接進 來或者進行路由轉發,以此網絡實現通信的目的。
也許有讀者會好奇,在建立起veth pair之前,新舊namespace該如何通信呢?答案是pipe(管道)。我們以Docker Daemon在啟動容器dockerinit的過程為例。Docker Daemon在宿主機上負責創建這個veth pair,通過netlink調用,把一端綁定到docker0網橋上,一端連進新建的network namespace進程中。建立的過程中,Docker Daemon和dockerinit就通過pipe進行通信,當Docker Daemon完成veth-pair的創建之前,dockerinit在管道的另一端循環等待,直到管道另一端傳來Docker Daemon關於veth設備的信息,並關閉管道。dockerinit才結束等待的過程,並把它的“eth0”啟動起來。整個效果類似下圖所示。
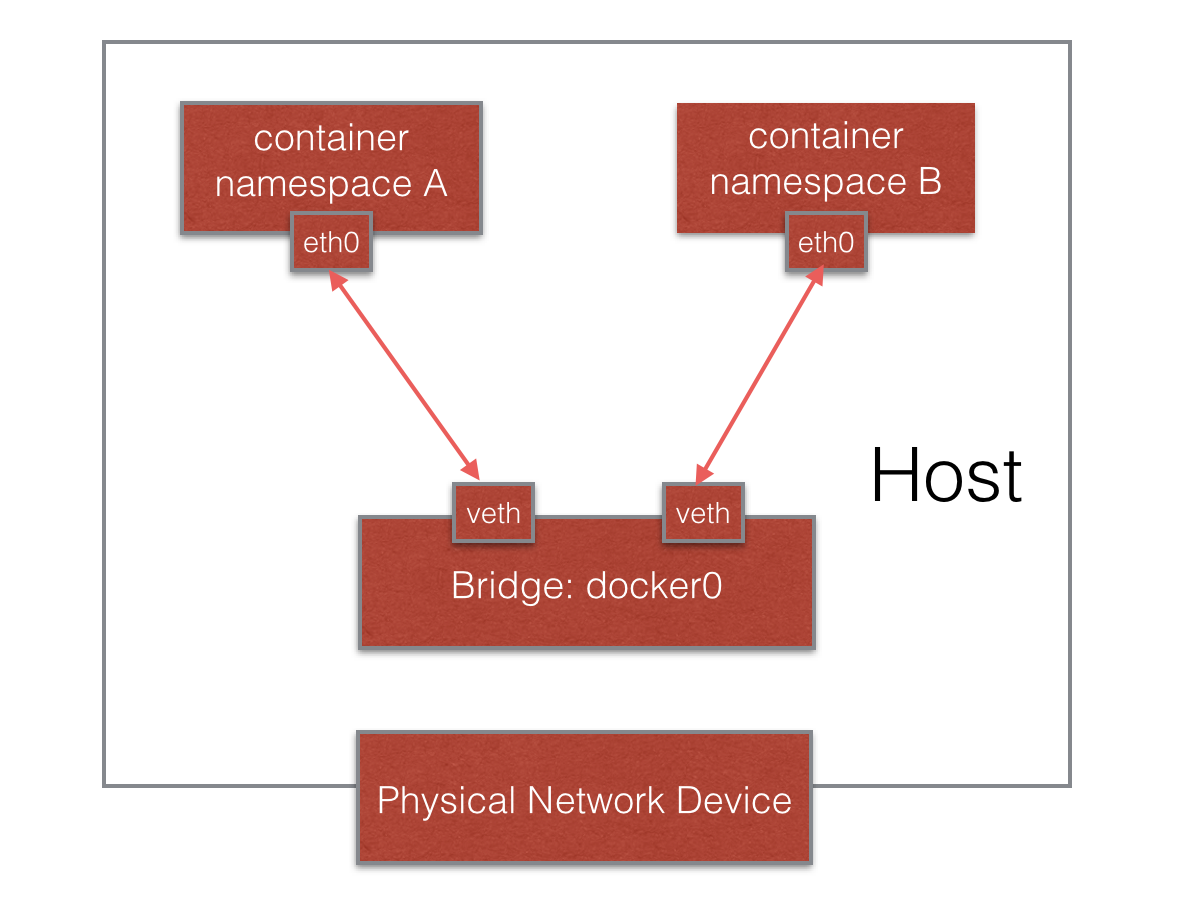
圖2 Docker網絡示意圖
跟其他namespace類似,對network namespace的使用其實就是在創建的時候添加CLONE_NEWNET標識位。也可以通過命令行工具ip創建network namespace。在代碼中建立和測試network namespace較為復雜,所以下文主要通過ip命令直觀的感受整個network namespace網絡建立和配置的過程。
首先我們可以創建一個命名為test_ns的network namespace。
# ip netns add test_ns
當ip命令工具創建一個network namespace時,會默認創建一個回環設備(loopback interface:lo),並在/var/run/netns目錄下綁定一個掛載點,這就保證了就算network namespace中沒有進程在運行也不會被釋放,也給系統管理員對新創建的network namespace進行配置提供了充足的時間。
通過ip netns exec命令可以在新創建的network namespace下運行網絡管理命令。
# ip netns exec test_ns ip link list
3: lo: <LOOPBACK> mtu 16436 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
上面的命令為我們展示了新建的namespace下可見的網絡鏈接,可以看到狀態是DOWN,需要再通過命令去啟動。可以看到,此時執行ping命令是無效的。
# ip netns exec test_ns ping 127.0.0.1 connect: Network is unreachable
啟動命令如下,可以看到啟動後再測試就可以ping通。
# ip netns exec test_ns ip link set dev lo up # ip netns exec test_ns ping 127.0.0.1 PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data. 64 bytes from 127.0.0.1: icmp_req=1 ttl=64 time=0.050 ms ...
這樣只是啟動了本地的回環,要實現與外部namespace進行通信還需要再建一個網絡設備對,命令如下。
# ip link add veth0 type veth peer name veth1 # ip link set veth1 netns test_ns # ip netns exec test_ns ifconfig veth1 10.1.1.1/24 up # ifconfig veth0 10.1.1.2/24 up
此時兩邊就可以互相連通了,效果如下。
# ping 10.1.1.1 PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data. 64 bytes from 10.1.1.1: icmp_req=1 ttl=64 time=0.095 ms ... # ip netns exec test_ns ping 10.1.1.2 PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data. 64 bytes from 10.1.1.2: icmp_req=1 ttl=64 time=0.049 ms ...
讀者有興趣可以通過下面的命令查看,新的test_ns有著自己獨立的路由和iptables。
ip netns exec test_ns route ip netns exec test_ns iptables -L
路由表中只有一條通向10.1.1.2的規則,此時如果要連接外網肯定是不可能的,你可以通過建立網橋或者NAT映射來決定這個問題。如果你對此非常感興趣,可以閱讀Docker網絡相關文章進行更深入的講解。
做完這些實驗,你還可以通過下面的命令刪除這個network namespace。
# ip netns delete netns1
這條命令會移除之前的掛載,但是如果namespace本身還有進程運行,namespace還會存在下去,直到進程運行結束。
通過network namespace我們可以了解到,實際上內核創建了network namespace以後,真的是得到了一個被隔離的網絡。但是我們實際上需要的不是這種完全的隔離,而是一個對用戶來說透明獨立的網絡實體,我們需要與這 個實體通信。所以Docker的網絡在起步階段給人一種非常難用的感覺,因為一切都要自己去實現、去配置。你需要一個網橋或者NAT連接廣域網,你需要配 置路由規則與宿主機中其他容器進行必要的隔離,你甚至還需要配置防火牆以保證安全等等。所幸這一切已經有了較為成熟的方案,我們會在Docker網絡部分 進行詳細的講解。
User namespace主要隔離了安全相關的標識符(identifiers)和屬性(attributes),包括用戶ID、用戶組ID、root目錄、key(指密鑰)以及特殊權限。 說得通俗一點,一個普通用戶的進程通過clone()創建的新進程在新user namespace中可以擁有不同的用戶和用戶組。這意味著一個進程在容器外屬於一個沒有特權的普通用戶,但是他創建的容器進程卻屬於擁有所有權限的超級 用戶,這個技術為容器提供了極大的自由。
User namespace是目前的六個namespace中最後一個支持的,並且直到Linux內核3.8版本的時候還未完全實現(還有部分文件系統不支持)。 因為user namespace實際上並不算完全成熟,很多發行版擔心安全問題,在編譯內核的時候並未開啟USER_NS。實際上目前Docker也還不支持user namespace,但是預留了相應接口,相信在不久後就會支持這一特性。所以在進行接下來的代碼實驗時,請確保你系統的Linux內核版本高於3.8並 且內核編譯時開啟了USER_NS(如果你不會選擇,可以使用Ubuntu14.04)。
Linux中,特權用戶的user ID就是0,演示的最終我們將看到user ID非0的進程啟動user namespace後user ID可以變為0。使用user namespace的方法跟別的namespace相同,即調用clone()或unshare()時加入CLONE_NEWUSER標識位。老樣子,修 改代碼並另存為userns.c,為了看到用戶權限(Capabilities),可能你還需要安裝一下libcap-dev包。
首先包含以下頭文件以調用Capabilities包。
#include <sys/capability.h>
其次在子進程函數中加入geteuid()和getegid()得到namespace內部的user ID,其次通過cap_get_proc()得到當前進程的用戶擁有的權限,並通過cap_to_text()輸出。
int child_main(void* args) {
printf("在子進程中!\n");
cap_t caps;
printf("eUID = %ld; eGID = %ld; ",
(long) geteuid(), (long) getegid());
caps = cap_get_proc();
printf("capabilities: %s\n", cap_to_text(caps, NULL));
execv(child_args[0], child_args);
return 1;
}
在主函數的clone()調用中加入我們熟悉的標識符。
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWUSER | SIGCHLD, NULL);
//[...]
至此,第一部分的代碼修改就結束了。在編譯之前我們先查看一下當前用戶的uid和guid,請注意此時我們是普通用戶。
$ id -u 1000 $ id -g 1000
然後我們開始編譯運行,並進行新建的user namespace,你會發現shell提示符前的用戶名已經變為nobody。
sun@ubuntu$ gcc userns.c -Wall -lcap -o userns.o && ./userns.o 程序開始: 在子進程中! eUID = 65534; eGID = 65534; capabilities: = cap_chown,cap_dac_override,[...]37+ep <<--此處省略部分輸出,已擁有全部權限 nobody@ubuntu$
通過驗證我們可以得到以下信息。
接下來我們就要進行用戶綁定操作,通過在/proc/[pid]/uid_map和/proc/[pid]/gid_map兩個文件中寫入對應的綁定信息可以實現這一點,格式如下。
ID-inside-ns ID-outside-ns length
寫這兩個文件需要注意以下幾點。
明白了上述原理,我們再次修改代碼,添加設置uid和guid的函數。
//[...]
void set_uid_map(pid_t pid, int inside_id, int outside_id, int length) {
char path[256];
sprintf(path, "/proc/%d/uid_map", getpid());
FILE* uid_map = fopen(path, "w");
fprintf(uid_map, "%d %d %d", inside_id, outside_id, length);
fclose(uid_map);
}
void set_gid_map(pid_t pid, int inside_id, int outside_id, int length) {
char path[256];
sprintf(path, "/proc/%d/gid_map", getpid());
FILE* gid_map = fopen(path, "w");
fprintf(gid_map, "%d %d %d", inside_id, outside_id, length);
fclose(gid_map);
}
int child_main(void* args) {
cap_t caps;
printf("在子進程中!\n");
set_uid_map(getpid(), 0, 1000, 1);
set_gid_map(getpid(), 0, 1000, 1);
printf("eUID = %ld; eGID = %ld; ",
(long) geteuid(), (long) getegid());
caps = cap_get_proc();
printf("capabilities: %s\n", cap_to_text(caps, NULL));
execv(child_args[0], child_args);
return 1;
}
//[...]
編譯後即可看到user已經變成了root。
$ gcc userns.c -Wall -lcap -o usernc.o && ./usernc.o 程序開始: 在子進程中! eUID = 0; eGID = 0; capabilities: = [...],37+ep root@ubuntu:~#
至此,你就已經完成了綁定的工作,可以看到演示全程都是在普通用戶下執行的。最終實現了在user namespace中成為了root而對應到外面的是一個uid為1000的普通用戶。
如果你要把user namespace與其他namespace混合使用,那麼依舊需要root權限。解決方案可以是先以普通用戶身份創建user namespace,然後在新建的namespace中作為root再clone()進程加入其他類型的namespace隔離。
講完了user namespace,我們再來談談Docker。雖然Docker目前尚未使用user namespace,但是他用到了我們在user namespace中提及的Capabilities機制。從內核2.2版本開始,Linux把原來和超級用戶相關的高級權限劃分成為不同的單元,稱為 Capability。這樣管理員就可以獨立對特定的Capability進行使能或禁止。Docker雖然沒有使用user namespace,但是他可以禁用容器中不需要的Capability,一次在一定程度上加強容器安全性。
當然,說到安全,namespace的六項隔離看似全面,實際上依舊沒有完全隔離Linux的資源,比如SELinux、 Cgroups以及/sys、/proc/sys、/dev/sd*等目錄下的資源。關於安全的更多討論和講解,我們會在後文中接著探討。
本文從namespace使用的API開始,結合Docker逐步對六個namespace進行講解。相信把講解過程中所有的代碼整合起來,你也能 實現一個屬於自己的“shell”容器了。雖然namespace技術使用起來非常簡單,但是要真正把容器做到安全易用卻並非易事。PID namespace中,我們要實現一個完善的init進程來維護好所有進程;network namespace中,我們還有復雜的路由表和iptables規則沒有配置;user namespace中還有很多權限上的問題需要考慮等等。其中有些方面Docker已經做的很好,有些方面也才剛剛開始。希望通過本文,能為大家更好的理 解Docker背後運行的原理提供幫助。
原文:http://www.infoq.com/cn/articles/docker-kernel-knowledge-namespace-resource-isolation