


save命令調度rdbSave函數,會阻塞主線程的工作,當快照比較大時對性能影響是非常大的,會間斷性暫停服務,所以Master最好不要寫內存快照。
如果不重寫AOF文件,這個持久化方式對性能的影響是最小的,但是AOF文件會不斷增大,AOF文件過大會影響Master重啟的恢復速度。
Master調用BGREWRITEAOF重寫AOF文件,AOF在重寫的時候會占大量的CPU和內存資源,導致服務load過高,出現短暫服務暫停現象。
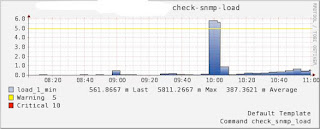
下面是我的一個實際項目的情況,大概情況是這樣的:一個Master,4個Slave,沒有Sharding機制,僅是讀寫分離,Master負責 寫入操作和AOF日志備份,AOF文件大概5G,Slave負責讀操作,當Master調用BGREWRITEAOF時,Master和Slave負載會 突然陡增,Master的寫入請求基本上都不響應了,持續了大概5分鐘,Slave的讀請求過也半無法及時響應,Master和Slave的服務器負載圖 如下:
Master Server load:
Slave server load:
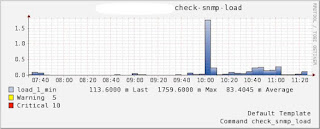
上面的情況本來不會也不應該發生的,是因為以前Master的這個機器是Slave,在上面有一個shell定時任務在每天的上午10點調用 BGREWRITEAOF重寫AOF文件,後來由於Master機器down了,就把備份的這個Slave切成Master了,但是這個定時任務忘記刪除 了,就導致了上面悲劇情況的發生,原因還是找了幾天才找到的。
將no-appendfsync-on-rewrite的配置設為yes可以緩解這個問題,設置為yes表示rewrite期間對新寫操作不fsync,暫時存在內存中,等rewrite完成後再寫入。最好是不開啟Master的AOF備份功能。
第一次Slave向Master同步的實現是:Slave向Master發出同步請求,Master先dump出rdb文件,然後將rdb文件全量 傳輸給slave,然後Master把緩存的命令轉發給Slave,初次同步完成。第二次以及以後的同步實現是:Master將變量的快照直接實時依次發 送給各個Slave。不管什麼原因導致Slave和Master斷開重連都會重復以上過程。Redis的主從復制是建立在內存快照的持久化基礎上,只要有 Slave就一定會有內存快照發生。雖然Redis宣稱主從復制無阻塞,但由於Redis使用單線程服務,如果Master快照文件比較大,那麼第一次全 量傳輸會耗費比較長時間,且文件傳輸過程中Master可能無法提供服務,也就是說服務會中斷,對於關鍵服務,這個後果也是很可怕的。
以上1.2.3.4根本問題的原因都離不開系統io瓶頸問題,也就是硬盤讀寫速度不夠快,主進程 fsync()/write() 操作被阻塞。
由於目前Redis的主從復制還不夠成熟,所以存在明顯的單點故障問題,這個目前只能自己做方案解決,如:主動復制,Proxy實現Slave對 Master的替換等,這個也是Redis作者目前比較優先的任務之一,作者的解決方案思路簡單優雅,詳情可見 Redis Sentinel design draft http://redis.io/topics/sentinel-spec。