最初,Hive用於建立大規模的成批計算,這在數據報告、數據挖掘以及數據准備等應用場景很有效。這些應用場景很重要,但是Hadoop的需求十分 廣闊,企業用戶越來越需要Hadooop具備更高的實時性和交互性。在Hortonworks,我們相信開源社區的創新力要超過任何一個專有的提供 商,Stinger initiative再次證明了這一點,我們會聯合(社區)伙伴一起提升Hive的性能。
什麼是Stinger Initiative?
能讓Hive回答問題的速度滿足普通人(例如一個問題的返回時間在5-30秒),如大數據探索、可視化、參數化報告等場景,而且並不依賴其它工具,並分發到用戶社區,可以很好的維護企業原有的投資和開發者的Hive技能。
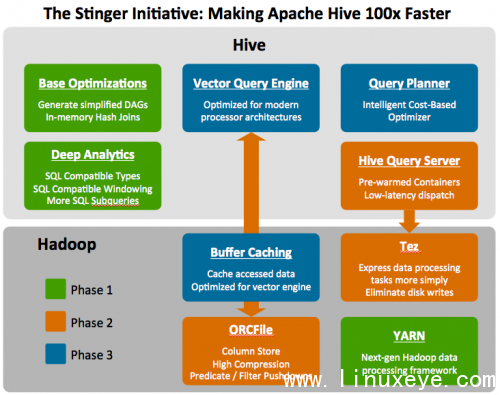
圖:Stinger Initiative的roadmap
為此,我們發布了Stinger Initiative,並進入社區進行分享,為的是讓Hive支持更多SQL,並實現更好的性能。一直以來,HiveQL都沒有什麼變化,而這次HiveQL將變得更強大。同時,與現有的工具保持一致形成完美的互補。
所有這些對Hive的調整仍在公開的進行中,內部預覽版將在今年三月舉行的由Hortonworks主辦的 Hadoop大會上公開。
擁抱社區和Hive
許多不同的團隊在Hive社區貢獻著他們成果。來自SAP的Harish Butani的團隊負責為Hive增加一個分析和數據窗口函數。這個函數將增加到OVER子句中用於已經存在的聚集函數,就像RAND、NTILE和LEAD、LAG等函數一樣, 這裡可以看到詳細的說明。Facebook的Namit Jain已經花了大量時間來優化Hive的查需執行計劃,這讓Join等操作變的更高效,並減少來自用戶的提示。Hortonworks已經參與到這些項目中。
Owen O’Malley,Hortonworks聯合創始人,早期的Hadoop的開發者,已經在Facebook為ORC文件格式進行了大量工作,這項工作將幫助提升Hive讀、寫、處理數據的性能,在 這裡可以看到詳情。我們還在為一些更長遠的目標工作,如重寫Hive的運算符來處理上千的記錄,其效率和現在相比將有大幅提升。
為什麼要重新造輪子呢?