我們選取一個TPC-H標准測試來說明不同的文件格式在存儲上的開銷。因為此數據是公開的,所以讀者如果對此結果感興趣,也可以對照後面的實驗自行 做一遍。Orders 表文本格式的原始大小為1.62G。 我們將其裝載進Hadoop 並使用Hive 將其轉化成以上幾種格式,在同一種LZO 壓縮模式下測試形成的文件的大小。
Orders_text1
1732690045
1.61G
非壓縮
TextFile
Orders_tex2
772681211
736M
LZO壓縮
TextFile
Orders_seq1
1935513587
1.80G
非壓縮
SequenceFile
Orders_seq2
822048201
783M
LZO壓縮
SequenceFile
Orders_rcfile1
1648746355
1.53G
非壓縮
RCFile
Orders_rcfile2
686927221
655M
LZO壓縮
RCFile
Orders_avro_table1
1568359334
1.46G
非壓縮
Avro
Orders_avro_table2
652962989
622M
LZO壓縮
Avro
表1:不同格式文件大小對比
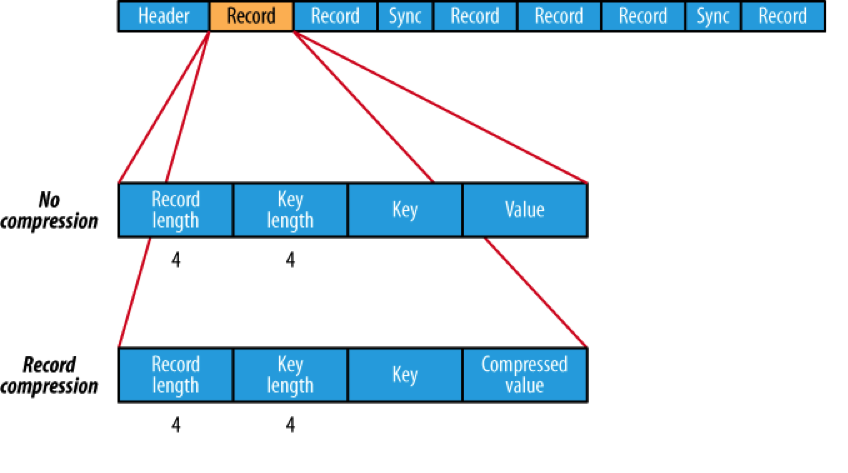
從上述實驗結果可以看到,SequenceFile無論在壓縮和非壓縮的情況下都比 原始純文本TextFile大,其中非壓縮模式下大11%, 壓縮模式下大6.4%。這跟SequenceFile的文件格式的定義有關: SequenceFile在文件頭中定義了其元數據,元數據的大小會根據壓縮模式的不同略有不同。一般情況下,壓縮都是選取block 級別進行的,每一個block都包含key的長度和value的長度,另外每4K字節會有一個sync-marker的標記。對於TextFile文件格 式來說不同列之間只需要用一個行間隔符來切分,所以TextFile文件格式比SequenceFile文件格式要小。但是TextFile 文件格式不定義列的長度,所以它必須逐個字符判斷每個字符是不是分隔符和行結束符。因此TextFile 的反序列化開銷會比其他二進制的文件格式高幾十倍以上。
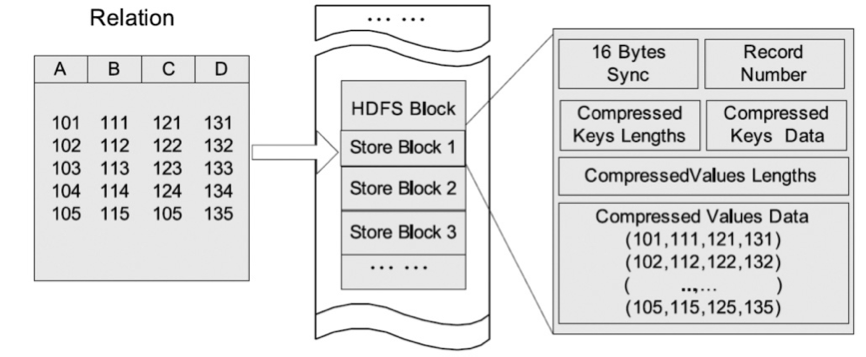
RCFile 文件格式同樣也會保存每個列的每個字段的長度。但是它是連續儲存在頭部元數據塊中,它儲存實際數據值也是連續的。另外RCFile 會每隔一定塊大小重寫一次頭部的元數據塊(稱為row group,由hive.io.rcfile.record.buffer.size控制,其默認大小為4M),這種做法對於新出現的列是必須的,但是如 果是重復的列則不需要。RCFile 本來應該會比SequenceFile 文件大,但是RCFile 在定義頭部時對於字段長度使用了Run Length Encoding進行壓縮,所以RCFile 比SequenceFile又小一些。Run length Encoding針對固定長度的數據格式有非常高的壓縮效率,比如Integer、Double和Long等占固定長度的數據類型。在此提一個特例—— Hive 0.8引入的TimeStamp 時間類型,如果其格式不包括毫秒,可表示為”YYYY-MM-DD HH:MM:SS”,那麼就是固定長度占8個字節。如果帶毫秒,則表示為”YYYY-MM-DD HH:MM:SS.fffffffff”,後面毫秒的部分則是可變的。
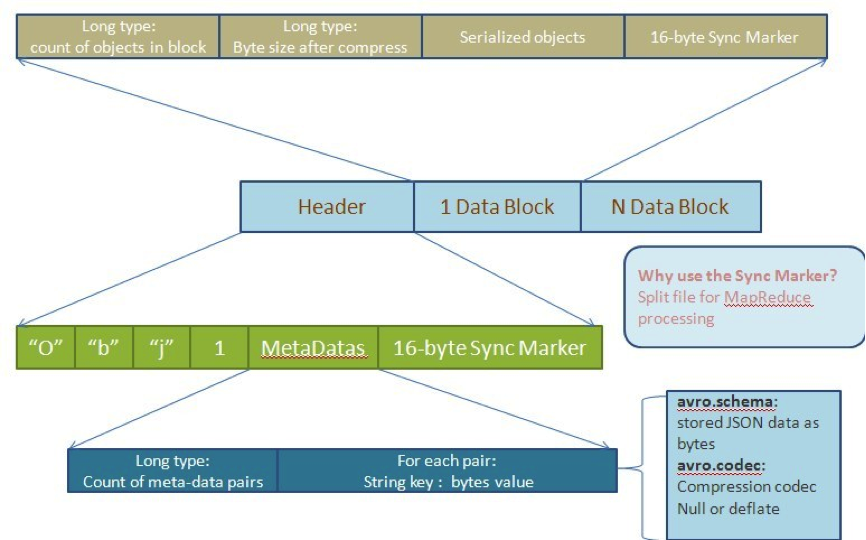
Avro 文件格式也按group進行劃分。但是它會在頭部定義整個數據的模式(Schema), 而不像RCFile那樣每隔一個row group就定義列的類型,並且重復多次。另外,Avro在使用部分類型的時候會使用更小的數據類型,比如Short或者Byte類型,所以Avro的數 據塊比RCFile 的文件格式塊更小。
我們可以使用Java的profile工具來查看Hadoop 運行時任務的CPU和內存開銷。以下是在Hive 命令行中的設置:
hive>set mapred.task.profile=true;
hive>set mapred.task.profile.params =-agentlib:hprof=cpu=samples,heap=sites, depth=6,force=n,thread=y,verbose=n,file=%s
當map task 運行結束後,它產生的日志會寫在$logs/userlogs/job-<jobid> 文件夾下。當然,你也可以直接在JobTracker的Web界面的logs或jobtracker.jsp 頁面找到日志。
我們運行一個簡單的SQL語句來觀察RCFile 格式在序列化和反序列化上的開銷:
hive> select O_CUSTKEY,O_ORDERSTATUS from orders_rc2 where O_ORDERSTATUS=’P';
其中的O_CUSTKEY列為integer類型,O_ORDERSTATUS為String類型。在日志輸出的最後會包含內存和CPU 的消耗。
下表是一次CPU 的開銷:
rank
self
accum
count
trace
method
20
0.48%
79.64%
65
315554
org.apache.hadoop.hive.ql.io.RCFile$Reader.getCurrentRow
28
0.24%
82.07%
32
315292
org.apache.hadoop.hive.serde2.columnar.ColumnarStruct.init
55
0.10%
85.98%
14
315788
org.apache.hadoop.hive.ql.io.RCFileRecordReader.getPos
56
0.10%
86.08%
14
315797
org.apache.hadoop.hive.ql.io.RCFileRecordReader.next
表2:一次CPU的開銷
其中第五列可以對照上面的Track信息查看到底調用了哪些函數。比如CPU消耗排名20的函數對應Track:
TRACE 315554: (thread=200001)
org.apache.hadoop.hive.ql.io.RCFile$Reader.getCurrentRow(RCFile.java:1434)
org.apache.hadoop.hive.ql.io.RCFileRecordReader.next(RCFileRecordReader.java:88)
org.apache.hadoop.hive.ql.io.RCFileRecordReader.next(RCFileRecordReader.java:39)
org.apache.hadoop.hive.ql.io.CombineHiveRecordReader.doNext(
CombineHiveRecordReader.java:98)
org.apache.hadoop.hive.ql.io.CombineHiveRecordReader.doNext(
CombineHiveRecordReader.java:42)
org.apache.hadoop.hive.ql.io.HiveContextAwareRecordReader.next(
HiveContextAwareRecordReader.java:67)
其 中,比較明顯的是RCFile,它為了構造行而消耗了不必要的數組移動開銷。其主要是因為RCFile 為了還原行,需要構造RowContainer,順序讀取一行構造RowContainer,然後給其中對應的列進行賦值,因為RCFile早期為了兼容 SequenceFile所以可以合並兩個block,又由於RCFile不知道列在哪個row group結束,所以必須維持數組的當前位置,類似如下格式定義:
Array<RowContainer extends List<Object>>
而此數據格式可以改為面向列的序列化和反序列化方式。如:
Map<array<col1Type>,array<col2Type>,array<col3Type>….>
這種方式的反序列化會避免不必要的數組移動,當然前提是我們必須知道列在哪個row group開始到哪個row group結束。這種方式會提高整體反序列化過程的效率。
關於Hadoop文件格式的思考
1. 高效壓縮
Hadoop目前尚未出現針對數據特性的高效編碼(Encoding)和解碼(Decoding)數據格式。尤其是支持Run Length Encoding、Bitmap 這些極為高效算法的數據格式。HIVE-2065 討論過使用更加高效的壓縮形式,但是對於如何選取列的順序沒有結論。關於列順序選擇可以看Daniel Lemire的一篇論文 《Reordering Columns for Smaller Indexes》[1]。作者同時也是Hive 0.8中引入的bitmap 壓縮算法基礎庫的作者。該論文的結論是:當某個表需要選取多個列進行壓縮時,需要根據列的選擇性(selectivity)進行升序排列,即唯一值越少的 列排得越靠前。 事實上這個結論也是Vertica多年來使用的數據格式。其他跟壓縮有關的還有HIVE-2604和HIVE-2600。
2. 基於列和塊的序列化和反序列化
不論排序後的結果是不是真的需要,目前Hadoop的整體框架都需要不斷根據數據key進行排序。除了上面提到的基於列的排序,序列化和反序列化之 外,Hadoop的文件格式應該支持某種基於塊(Block) 級別的排序和序列化及反序列化方式,只有當數據滿足需要時才進行這些操作。來自Google Tenzing論文中曾將它作為MR 的優化手段提到過。
“Block Shuffle:正常來說,MR 在Shuffle 的時候使用基於行的編碼和解碼。為了逐個處理每一行,數據必須先排序。然而,當排序不是必要的時候這種方式並不高效,我們在基於行的shuffle基礎上實現了一種基於block的shuffle方式,每一次處理大概1M的壓縮block,通過把整個block當成一行,我們能夠避免MR框架上的基於行的序列化和反序列化消耗,這種方式比基於行的shuffle 快上3倍以上。”
3. 數據過濾(Skip List)
除常見的分區和索引之外,使用排序之後的塊(Block)間隔也是常見列數據庫中使用的過濾數據的方法。Google Tenzing同樣描述了一種叫做ColumnIO 的數據格式,ColumnIO在頭部定義該Block的最大值和最小值,在進行數據判斷的時候,如果當前Block的頭部信息裡面描述的范圍中不包含當前 需要處理的內容,則會直接跳過該塊。Hive社區裡曾討論過如何跳過不需要的塊 ,可是因為沒有排序所以一直沒有較好的實現方式。包括RCFile格式,Hive的index 機制裡面目前還沒有一個高效的根據頭部元數據就可以跳過塊的實現方式。
4. 延遲物化
真正好的列數據庫,都應該可以支持直接在壓縮數據之上不需要通過解壓和排序就能夠直接操作塊。通過這種方式可以極大的降低MR 框架或者行式數據庫中先解壓,再反序列化,然後再排序所帶來的開銷。Google Tenzing裡面描述的Block Shuffle 也屬於延遲物化的一種。更好的延遲物化可以直接在壓縮數據上進行操作,並且可以做內部循環, 此方面在論文《Integrating Compression and Execution in Column-Oriented Database System》[5]的5.2 章節有描述。 不過考慮到它跟UDF 集成也有關系,所以,它會不會將文件接口變得過於復雜也是一件有爭議的事情。
5. 與Hadoop框架集成
無論文本亦或是二進制格式,都只是最終的儲存格式。Hadoop運行時產生的中間數據卻沒有辦法控制。包括一個MR Job在map和reduce之間產生的數據或者DAG Job上游reduce 和下游map之間的數據,尤其是中間格式並不是列格式,這會產生不必要的IO和CPU 開銷。比如map 階段產生的spill,reduce 階段需要先copy 再sort-merge。如果這種中間格式也是面向列的,然後將一個大塊切成若干小塊,並在頭部加上每個小塊的最大最小值索引,就可以避免大量sort- mege操作中解壓—反序列化—排序—合並(Merge)的開銷,從而縮短任務的運行時間。
其他文件格式
Hadoop社區也曾有對其他文件格式的研究。比如,IBM 研究過面向列的數據格式並發表論文《Column-Oriented Storage Techniques for MapReduce》[4],其中特別提到IBM 的CIF(Column InputFormat)文件格式在序列化和反序列化的IO消耗上比RCFile 的消耗要小20倍。裡面提到的將列分散在不同的HDFS Block 塊上的實現方式RCFile 也有考慮過,但是最後因為重組行的消耗可能會因分散在遠程機器上產生的延遲而最終放棄了這種實現。此外,最近Avro也在實現一種面向列的數據格式,不過 目前Hive 與Avro 集成尚未全部完成。有興趣的讀者可以關注avro-806 和hive-895。
Hadoop 可以與各種系統兼容的前提是Hadoop MR 框架本身能夠支持多種數據格式的讀寫。但如果要提升其性能,Hadoop 需要一種高效的面向列的基於整個MR 框架集成的數據格式。尤其是高效壓縮,塊重組(block shuffle),數據過濾(skip list)等高級功能,它們是列數據庫相比MR 框架在文件格式上有優勢的地方。相信隨著社區的發展以及Hadoop 的逐步成熟,未來會有更高效且統一的數據格式出現。
轉載地址:http://www.infoq.com/cn/articles/hadoop-file-format