


什麼是網站運維(Web operations) ?運維,絕不是某些人眼中安裝系統、做幾根網線那麼簡單? 除去應用開發和業務運營之外的保障網站能運轉的事兒都可能是運維工作的職責范圍。運維的工作包括(但不限於) 軟硬件部署、網絡管理、應用程序維護、安全、容量規劃、故障修復等等。
運維,有別於"運營"。在中文的語境中,運營更多和業務結合在一起的。而運維,則是偏向技術層面。
任何一個成功的站點都離不開一只優秀的運維團隊,盡管他們更多時候隱身在網站背後不為人知。
所謂網站可用性(availability)也即網站正常運行時間的百分比,這是每個運營團隊最主要的 KPI (Key Performance Indicators ,關鍵業績指標)。對於 Web 站點來說,傳統的那個 24x7 的說法已經不是很適用了,現在業界更傾向用 N 個9 來量化可用性, 最常說的就是類似 "4個9(也就是99.99%)" 的可用性。看一下表 1 能更為直觀一些。
可用性級別 年度停機時間 基本可用性 2個9 99% 87.6小時 較高可用性 3個9 99.9% 8.8小時 具有故障自動恢復能力的可用性 4個9 99.99% 53分鐘 極高可用性 5個9 99.999% 5分鐘根據墨菲定理的推論,世界上沒有 100% 可靠的 Web站點(除非不運行)。業界網站的可用性都是多少?引人注目的 Web 新貴 Twitter (http://twitter.com), 2008 年前四個月的可用性只有 98.72%,有 37小時 16分鐘不能提供服務,連2個9 都達不到,甚至還沒達到"基本可用"狀態。電子商務巨頭 eBay 2007 年的可用性是 99.94%,考慮到 eBay 站點的規模與應用的復雜程度,這是個很不錯可用性指標了。Web 應用類型決定了不同的站點對可用性的依賴性是不同的。 要知道 4 個 9 的可用性實際上是很難實現的目標。至於 5 個9 的 Web 站點,一半靠內功,另一半恐怕是要靠點運氣。
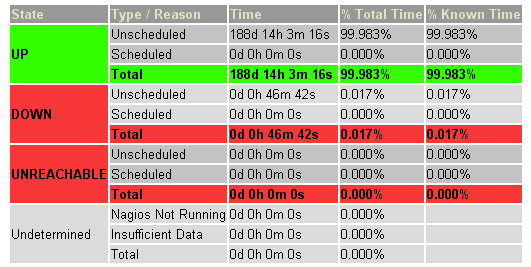
(圖1 維基百科網站的一台數據庫服務器的可用情況報告, 由Nagios的監控得到的)
提高可用性的一些常規策略有消除單點,部署冗余設備(或集群),配置帶外管理網絡等,對可用性要求不高的網站這些可能足夠了。如果要提供更高的可用 性,比如 4 個 9 甚至 5 個9,就不是簡單靠硬件就能做到的事情,還需要建立完善的流程制度、建立變更機制、提升事故響應速度等。正所謂是"沒有最高可用,只有更高可用性"。
一般來說,所有的網站運維人員都在追求網站的更高級別的高可用性,但是必須注意,這是以額外的軟硬件投入、更多的人力成本為代價的。成本與可用性之間也請做到良好的平衡,盲目追求高可用性是不可取的。
(補充:Twitter 的可用性現在已經有了很大提升,但是可以看到,可用性不佳並非一個網站的殺手,只要產品對用戶足夠友好,足夠有粘度,足夠不可或缺,那麼可用性並非是第一 要追求的運維目標。有些運維人員被 Amazon 的某年聖誕節期間宕機所造成的影響埋下心理陰影,其實沒那麼可怕,如果真的覺得可怕,那麼你可能被一些廠商銷售人員洗腦了。)
定義了網站可用性指標,如何獲取網站的可用值? 監控工具該粉墨登場了。
多數網站都會傾向於利用開源軟件自行搭建監控平台。筆者一向認為,即使網站有一台服務器,也應該搭建監控工具,這是保障網站能持續改進的基石。常見的開源監控工具有Nagios(www.nagios.org)、monit(www.tildeslash.com/monit) 等。Nagios也可能是當前國內最被廣泛采用的監控軟件了,根據官方描述,Nagios 是開源的主機、網絡、服務監控程序,從這個描述能看出,Nagios 的設計目標是很龐大的。依賴其強大的擴展性,通過分布式監控模式,管理上千台甚至更多的服務器也不在話下。而對於大型集群環境,Ganglia (http://ganglia.info/) 是個不錯的選擇。
另外商業化運作的比較好的開源監控工具或框架還有 Zenoss (http://www.zenoss.com/)、Zabbix (http://www.zabbix.com/)、Hyperic (http://www.hyperic.com/)、 OpenNMS(http://opennms.org/) 等。這幾個的定位都是"企業級"監控平台。當然,功能的確不比 Nagios 差,也有的彌補了 Nagios 的一些不足之處(比如 Zenoss 增強了對 Windows 服務器的監控能力)。但出於種種原因,在國內的流行程度並不廣泛。
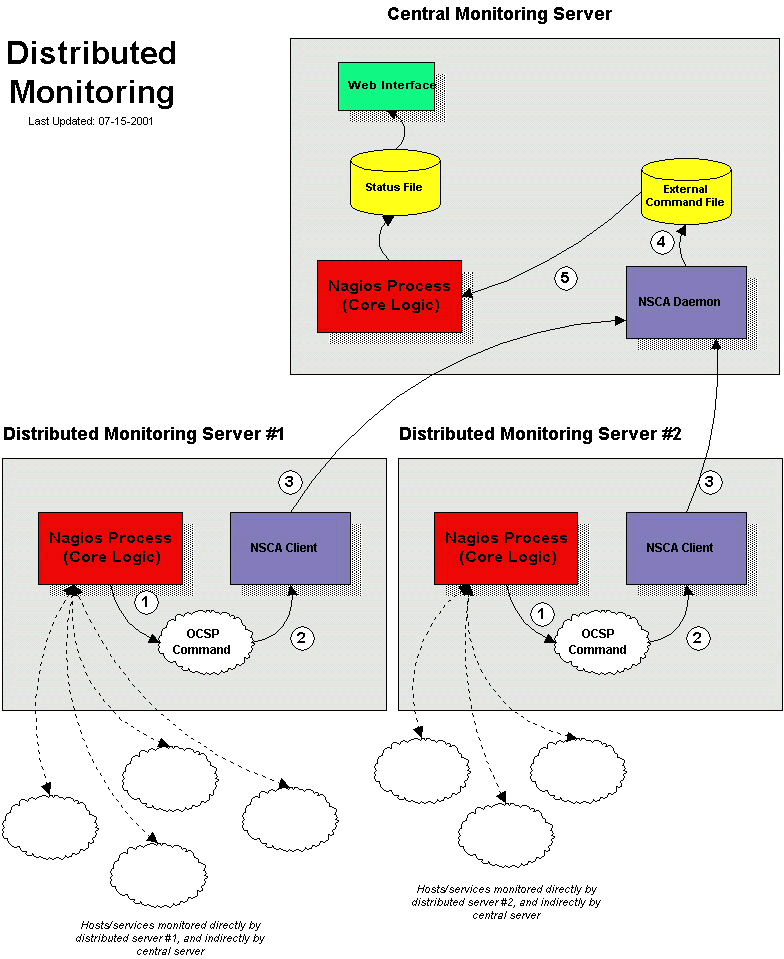
圖2: Nagios 分布監控示意圖
如果要滿足日趨靈活的 Web 監控需要就不得不提 Nagios 靈活的插件機制,最簡單只需要幾行 Shell 代碼就能實現基本的插件功能。多數情況下,腳本捕獲系統日志中的特定事件,通過 NSCA Client 發送給中心監控服務器即可。靈活性是衡量監控軟件的一個重要標准,從這一點說,多數傳統的商業網管軟件怕是都不如 Nagios 這樣勝任現在日趨復雜的網站環境。
提到網管監控,必然要談到 SNMP。跨平台或者針對專有設備的監控離不開SNMP,但有的時候 SNMP 的安全性也的確會帶來嚴重問題。這就需要運維團隊中的安全專家對監控系統機制的安全性做整體評估,或是提升運維團隊的安全意識以避免在監控過程中引入更多 的安全問題。
有些公司的運維團隊喜歡自己寫監控工具而不是利用已有的第三方開源工具。這種重復發明輪子的做法筆者認為是不可取的。這樣做最明顯的一個缺點是軟件本身的維護成本可能會更高,而且團隊人員變動的時候後續代碼維護也是個潛在的問題。至於商業工具的選擇,這裡不作評價。
光有監控而報警機制跟不上,不能及時把緊急情況下的信息傳遞給運維技術人員,那麼監控形同虛設。現在報警信息發送途徑主要有郵件、IM、SMS 三種(過去書籍中提到的傳呼方式已是明日黃花)。
這幾個途徑中,郵件告警可能是最簡單的,實現起來容易,一行命令即可做到,但因為郵件本身的異步屬性和郵件服務器的延時問題,很難讓運維人員及時得知信息。所以,如果比較嚴重的告警信息必須考慮其它實時性比較高的方法。至於發送到 IM,如果 IM 是支持 Jabber 的,實現起來並不難,可靠性也會有一定保障,而如果 IM 比較封閉,那麼可行性就不大了,除非 IM 公司對你開放 API ,否則任何取巧的技巧來發送消息的方法其可信賴性都不強、SMS 是大家都比較傾向的一種方式,只是有很多人不知道具體如何實現,說白了也就是一層窗戶紙。如果有電信服務提供商(SP)能夠提供基於 Web 的調用接口給你,那麼直接利用 Wget 或是 cURL 工具模擬浏覽器處理表單信息即可,幾行命令即可搞定。如果不具備這樣的條件,不妨考慮一下短信 Modem,現在市場上這樣的短信 Modem 很多,價格不貴,大多都提供二次開發的功能,簡單的寫點腳本即可實現目的。至於網上有人推薦的免費短信服務,因為實時性比較差,筆者是不推薦的。天下沒有 免費的午餐,這樣的服務往往信息發送優先級很低,而且,短信到達率很難保障。
值得一提的是,報警服務器本身也需要監控的。建議定期發送測試郵件、測試短信來驗證告警功能處於正常狀態。尤其是在節假日來臨前更要反復確保該功能是正常可用的。
有效的監控能夠避免絕大多數問題的擴大化,但是還是做不到防患於未然。監控告警機制完善後,就需要著手考慮容量規劃(Capacity Planning)的問題。
所謂的容量規劃,也就是一個公司為了滿足商業目標的需求而決定生產能力的過程。俗語說,"人無遠慮,必有近憂",容量規劃,需要的是"遠慮"。對應到運維的工作上來,一方面是商業目標帶來的容量需求,一方面是針對相關歷史數據的分析帶來的預測。這裡的歷史數據,是需要運維團隊采集、整理的。(從這個角度上說),容量規劃是一個長期的過程。
相關的數據保存和圖表生成,基本上都會采用 RRDtool (http://oss.oetiker.ch/rrdtool/)來做。 RRDtool 也已經是業界的事實上的標准,但畢竟 RRDtool 只能算是一套引擎。而規模化的數據管理工作則需要求助其它工具,則不能不提 Cacti (http://www.cacti.net/)這是現在相當通用的做法。老牌的 MRTG 已經很少有人用了。
利用 Cacti,很容易得到一段時間內某項數據指標的變化趨勢(比如網絡流量的增長趨勢、服務器負載的趨勢等)。這是運維過程中最主要的參考數據之一,缺乏此類數據而做決策是不可想象的。
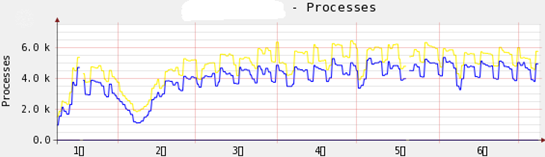
如上圖,可以發現被監控的服務器上進程數量半年內的增長趨勢,在 2 月份間的進程數並不高(春節期間),隨後的幾個月突破 4000 個進程,對於普通的服務器來說,這是比較危險的。盡管當前系統運行可能比較平穩,但運維技術人員絕對有必要考慮中期解決方案。
容量規劃中的另外一個重要參考維度是 Web 訪問日志的趨勢圖。對於中小網站來說,Awstats 足以勝任,更大一點的規模或是對統計要求更高的站點或許只能自己寫統計工具了,還沒聽說有什麼針對大型網站而且性價比好的商業工具。這裡筆者要強調一下的是,商業站點盡量不要用第三方的流量統計工具,這樣很容易洩漏比較關鍵的商業信息。
容量規劃其實遠遠不止這些,比如應用服務器容量規劃方面、數據庫容量規劃,主機容量規劃、存儲容量規劃等等,把整個架構拆成各個組件,每個組件的容量規劃都是值得大書特書的一塊內容。
另外一個關鍵點是團隊的"容量規劃",團隊成長這一方面如果跟不上也很容易成為瓶頸。
對於相對正規的網站維護工作,所有網站的所有變更必須能做到有記錄,可回溯。如果是單槍匹馬作戰,那麼要實現這個目標並不是很難,只需要把好習慣培養起來就成了,可如果要面對一個團隊,那麼就必須要依賴流程規范來進行約束。
所謂"流程規范",在初期也可以拆開來對待:流程 + 規范(廢話!)。
關於流程(Process),直白的說就是"把大象放入冰箱需要幾步?"的問題。比如上線一台服務器,那麼可能要經過至少前期的選型規劃、基准測試、壓力測試......等等諸多步驟。如果跳過某個環節(比如缺少基准測試)而直接上線,遇到問題的時候幾乎就會因為缺乏對比數據而走彎路。
關於規范(Norm),在運維的過程中是個范圍比較大的話題,因為 Web 站點環境因為各種原因而不可復制,在另一個公司可用的規范照搬到另外一家公司未必管用。如果能夠意識到並且盡早抽象出來標准化組件,並著手推進,那麼規范 必然會逐漸豐富起來並完善。比如 Web 服務器配置規范、Linux 主機配置規范、SAN 存儲系統測試規范,都是可以盡早抽象出來並且可具體化的東西。
流程規范建立容易,但是如何確保執行卻是一個很有挑戰性的問題。從這一點來說,對於運維團隊的領導的要求還是比較高的。如果要成功管理一個運維團隊,起碼要有足夠的技術經驗(當然,也容易看到外行領導內行的運維團隊),而且要有足夠強的執行力。
在流程規范的建立過程中,往往容易陷入為了規范而規范的誤區,或是生搬硬套 ITIL(Information Technology Infrastructure Library,"信息技術基礎架構庫") 那一套大而無當的東西進來(這裡不是說 ITIL 不好,但最合適自己的才是最好的),必須明確,規范的最終目的是為了運維團隊更快而不是變成束縛,所以,千萬要避免技術人員對規范的抵觸。
在運維團隊發展的某個階段,推行"流程規范"所引入的 ITIL 等事物是一把雙刃劍,運用得當會很好的促進團隊成長,運用不好則會阻礙一部分激進成員的積極性,這一點需要注意。
補充一點,對於流程規范,不是死的東西,必須具備不斷反饋、改進、進化的能力,運維團隊也應該定期修正流程規范的有關內容。有一句耳熟能詳的話是:遵守流程而不拘泥於流程,這裡的"不拘泥"切不可變成鑽空子的借口,要知道我們生活中很多無形成本就是鑽空子引起的。
原文網址: http://www.dbanotes.net/web/web_operations_availability.html