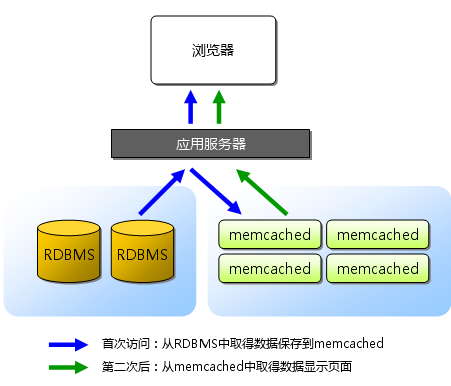
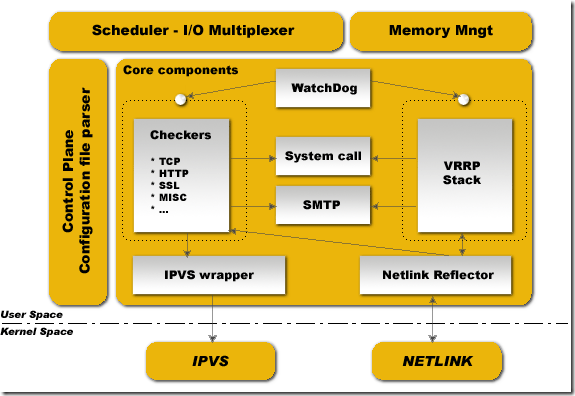
本文的目的不完全在於提供調優信息,而是在於告訴讀者了解Linux kernel如何處理數據包,從而能夠在自己的實踐中發揮Linux 內核協議棧最大的性能
The NIC ring buffer
接收環緩沖區在設備驅動程序和NIC之間共享。 網卡分配發送(TX)和接收(RX)環形緩沖區。 環形緩沖區是一個循環緩沖區,其中溢出只是覆蓋現有數據。 應該注意,有兩種方式將數據從NIC移動到內核,硬件中斷和軟件中斷(也稱為SoftIRQ)。 RX環形緩沖區用於存儲傳入的數據包,直到它們被設備驅動程序處理。 設備驅動程序通常通過SoftIRQ消費RX環,這將進入的數據包放入稱為sk_buff或“skb”的內核數據結構中,以開始其通過內核並到達擁有相關套接字的應用程序。 TX環形緩沖區用於保存發往該線路的輸出數據包。 這些環形緩沖器位於堆棧的底部,並且是可能發生分組丟棄的關鍵點,這又會不利地影響網絡性能。
Interrupts and Interrupt Handlers
來自硬件的中斷稱為“上半部分”中斷。 當NIC接收到傳入數據時,它使用DMA將數據復制到內核緩沖區中。 NIC通過喚醒硬中斷通知內核此數據。 這些中斷由中斷處理程序處理,這些中斷處理程序執行最少的工作,因為它們已經中斷了另一個任務,並且不能自行中斷。 硬中斷在CPU使用方面可能是昂貴的,特別是在持有內核鎖時。 硬中斷處理程序然後將大部分分組接收留給可以更公平地調度的軟件中斷或SoftIRQ處理。
硬中斷可以在/ proc / interrupts中看到,其中每個隊列在分配給它的第一列中有一個中斷向量。 當系統引導或加載NIC設備驅動程序模塊時,這些初始化。 每個RX和TX隊列被分配一個唯一的向量,它通知中斷處理程序該中斷來自哪個NIC /隊列。 列將進入中斷的數量表示為計數器值:
SoftIRQs
也稱為“下半”中斷,軟件中斷請求(SoftIRQ)是內核線程,其被調度為在其他任務不會被中斷的時間運行。 SoftIRQ的目的是消費網絡適配器接收環緩沖區。 這些例程以ksoftirqd / cpu-number進程和調用驅動程序特定的代碼函數的形式運行。 它們可以在過程監控工具(如ps和top)中看到。 以下調用堆棧,從底部向上讀取,是一個SoftIRQ輪詢Mellanox卡的示例。 標記為[mlx4_en]的函數是mlx4_en.ko驅動程序內核模塊中的Mellanox輪詢例程,由內核的通用輪詢例程(如net_rx_action)調用。 從驅動程序移動到內核之後,接收到的流量將移動到套接字,准備應用程序使用:
可以如下監視SoftIRQ。 每列代表一個CPU:
NAPI Polling
NAPI或新的API,以使處理傳入卡的數據包更有效率。 硬中斷是昂貴的,因為它們不能被中斷。 即使中斷聚合(稍後更詳細地描述),中斷處理程序也將完全獨占CPU核心。 NAPI的設計允許驅動程序進入輪詢模式,而不是每次需要的數據包接收都被硬中斷。 在正常操作下,引發初始硬中斷或IRQ,隨後是使用NAPI例程輪詢卡的SoftIRQ處理器。 輪詢例程具有確定允許代碼的CPU時間的預算。 這是防止SoftIRQ獨占CPU的必要條件。 完成後,內核將退出輪詢例程並重新建立,然後整個過程將重復自身。
Network Protocol Stacks
一旦已經從NIC接收到到內核的業務,則其然後由協議處理器(例如以太網,ICMP,IPv4,IPv6,TCP,UDP和SCTP)處理。最後,數據被傳遞到套接字緩沖器, 運行接收函數,將數據從內核空間移動到用戶空間,並結束內核在接收過程中的參與。
Packet egress in the Linux kerne
Linux內核的另一個重要方面是網絡包出口。 雖然比入口邏輯簡單,但出口仍然值得確認。 當skbs從協議層傳遞到核心內核網絡例程時,該過程工作。 每個skb包含一個dev字段,其中包含將通過其傳輸的net_device的地址:
它使用此字段將skb路由到正確的設備:
基於此設備,執行將切換到處理skb的驅動程序,並最終將數據復制到NIC上。 這裡主要需要調優的是TX隊列入隊規則(qdisc)稍後描述。 一些NIC可以有多個TX隊列。
以下是從測試系統獲取的示例堆棧跟蹤。 在這種情況下,流量是通過環回設備,但這可以是任何NIC模塊:
Networking Tools
要正確診斷網絡性能問題,可以使用以下工具:
netstat
一個命令行實用程序,可以打印有關打開網絡連接和協議棧統計信息。 它從/ proc / net /文件系統檢索有關網絡子系統的信息。 這些文件包括:
•/ proc / net / dev(設備信息)
•/ proc / net / tcp(TCP套接字信息)
•/ proc / net / unix(Unix域套接字信息)
有關netstat及其引用文件的更多信息 / proc / net /,請參考netstat手冊頁:man netstat。
dropwatch
監視實用程序,用於監視內核從內存釋放的數據包。 有關更多信息,請參閱dropwatch手冊頁:man dropwatch。
ip
用於管理和監視路由,設備,策略路由和隧道的實用程序。 有關更多信息,請參閱ip手冊頁:man ip
ethtool
用於顯示和更改NIC設置的實用程序。 有關更多信息,請參閱ethtool手冊頁:man ethtool。
各種工具可用於隔離問題區域。
通過調查以下幾點來找到瓶頸:
•適配器固件級別 - 在ethtool -S ethX統計信息中觀察丟棄
•適配器驅動程序級別
•Linux內核,IRQ或SoftIRQs - 檢查/ proc /中斷和/ proc / net / softnet_stat
• 協議層IP,TCP或UDP - 使用netstat -s並查找錯誤計數器
Performance Tuning
如果SoftIRQ沒有運行足夠長的時間,傳入數據的速率可能超過內核足夠快地耗盡緩沖區的能力。 因此,NIC緩沖區將溢出並且流量將丟失。 有時,有必要增加SoftIRQ允許在CPU上運行的時間。 這被稱為netdev_budget。 預算的默認值為300.
# sysctl net.core.netdev_budget
net.core.netdev_budget = 300
Tuned
Tuned是一個自適應系統調優守護程序。 它可以用於將收集在一起的各種系統設置應用到稱為配置文件的集合中。 調整後的配置文件可以包含諸如CPU調度器,IO調度程序和內核可調參數(如CPU調度或虛擬內存管理)的指令。 Tuned還集成了一個監視守護程序,可以控制或禁用CPU,磁盤和網絡設備的節能功能。 性能調整的目的是應用能夠實現最佳性能的設置。 Tuned可以自動化這項工作的很大一部分。 首先,安裝調優,啟動調整守護程序服務,並在啟動時啟用服務:
# yum -y install tuned
# service tuned start
# chkconfig tuned on
列出性能配置文件:
# tuned-adm list
Available profiles:
- throughput-performance
- default
- desktop-powersave
- enterprise-storage
...
可以在/ etc / tune-profiles /目錄中查看每個配置文件的內容。 我們關心的是設置性能配置文件,如吞吐量性能,延遲性能或企業級存儲
設置配置文件:
# tuned-adm profile throughput-performance
Switching to profile 'throughput-performance'
所選配置文件將在每次調諧服務啟動時應用。
The virtualization-related profiles provided as part of tuned-adm include:virtual-guestenterprise-storage profile, virtual-guest also decreases the swappiness of virtual memory. This profile is available in Red Hat Enterprise Linux 6.3 and later, and is the recommended profile for guest machines.
virtual-hostenterprise-storage profile, virtual-host also decreases the swappiness of virtual memory and enables more aggressive writeback of dirty pages. This profile is available in Red Hat Enterprise Linux 6.3 and later, and is the recommended profile for virtualization hosts, including both KVM and Red Hat Enterprise Virtualization hosts.
Numad
與tuned類似,numad是一個守護進程,可以幫助在具有非統一內存訪問(NUMA)架構的系統上的進程和內存管理。 Numad通過監視系統拓撲和資源使用情況來實現這一點,然後嘗試定位進程以實現高效的NUMA局部性和效率,其中進程具有足夠大的內存大小和CPU負載。 numad服務還需要啟用cgroups(Linux內核控制組)。
默認情況下,從Red Hat Enterprise Linux 6.5開始,numad將管理使用超過300Mb內存使用率和50%一個核心CPU使用率的任何進程,並嘗試使用任何給定的NUMA節點高達85%的容量。 Numad可以使用man numad中描述的指令進行更細致的調整。
CPU Power States
ACPI規范定義了各種級別的處理器功率狀態或“C狀態”,其中C0是操作狀態,C1是停止狀態,加上實現各種附加狀態的處理器制造商以提供額外的功率節省和相關優點,例如較低的溫度。不幸的是,在功率狀態之間的轉換在延遲方面是昂貴的。由於我們關注使系統的響應性盡可能高,期望禁用所有處理器“深度睡眠”狀態,僅保留操作和停止。這必須首先在系統BIOS或EFI固件中完成。應禁用任何狀態,如C6,C3,C1E或類似。我們可以通過在GRUB引導加載程序配置中的內核行中添加processor.max_cstate = 1來確保內核從不請求低於C1的C狀態。在某些情況下,內核能夠覆蓋硬件設置,並且必須向具有Intel處理器的系統添加附加參數intel_idle.max_cstate = 0。處理器的睡眠狀態可以通過以下方式確認:
cat /sys/module/intel_idle/parameters/max_cstate
0
較高的值表示可以輸入附加的睡眠狀態。 powertop實用程序的Idle Stats頁面可以顯示每個C狀態花費的時間
使用如下腳本修改各個 CPU 調頻��物理機有 16 個物理 CPU)
#!/bin/bash
for a in {0..15};
do echo $a;
echo 'performance' > /sys/devices/system/cpu/cpu$a/cpufreq/scaling_governor
cat /sys/devices/system/cpu/cpu$a/cpufreq/scaling_governor
done
禁用物理機超線程
TurboBoost Disabled
Power Technology: Performance
Manual balancing of interrupts
對於高性能來說要關閉irqbalance,同時將irq於cpu進行綁定
Ethernet Flow Control (a.k.a. Pause Frames)
暫停幀是適配器和交換機端口之間的以太網級流量控制。當RX或TX緩沖器變滿時,適配器將發送“暫停幀”。開關將以毫秒級或更小的時間間隔停止數據流動。這通常足以允許內核排出接口緩沖區,從而防止緩沖區溢出和隨後的數據包丟棄或超限。理想地,交換機將在暫停時間期間緩沖輸入數據。然而,重要的是認識到這種級別的流控制僅在開關和適配器之間。如果丟棄分組,則較高層(例如TCP)或者在UDP和/或多播的情況下的應用應當啟動恢復。需要在NIC和交換機端口上啟用暫停幀和流控制,以使此功能生效。有關如何在端口上啟用流量控制的說明,請參閱您的網絡設備手冊或供應商。
在此示例中,禁用流量控制:
# ethtool -a eth3 Pause parameters for eth3:
Autonegotiate:off
RX: off
TX: off
開啟流量控制:
# ethtool -A eth3 rx on
# ethtool -A eth3 tx on
要確認流量控制已啟用:
# ethtool -a eth3 Pause parameters for eth3:
Autonegotiate:off
RX: on
TX: on
Interrupt Coalescence (IC)
中斷聚合是指在發出硬中斷之前,網絡接口將接收的流量或接收流量後經過的時間。中斷太快或太頻繁會導致系統性能不佳,因為內核停止(或“中斷”)正在運行的任務以處理來自硬件的中斷請求。中斷太晚可能導致流量沒有足夠快地從NIC中取出。更多的流量可能到達,覆蓋以前的流量仍然等待被接收到內核中,導致流量丟失。大多數現代的NIC和驅動程序支持IC,許多驅動程序允許驅動程序自動調節硬件產生的中斷數。 IC設置通常包括2個主要組件,時間和數據包數量。時間是在中斷內核之前NIC將等待的微秒數(u-sec),並且數字是在中斷內核之前允許在接收緩沖器中等待的最大數據包數。 NIC的中斷聚合可以使用ethtool -c ethX命令查看,並使用ethtool -C ethX命令進行調整。自適應模式使卡能夠自動調節IC。在自適應模式下,驅動程序將檢查流量模式和內核接收模式,並在運行中估計合並設置,以防止數據包丟失。當接收到許多小數據包時,這是有用的。更高的中斷聚結有利於帶寬超過延遲。 VOIP應用(等待時間敏感)可能需要比文件傳輸協議(吞吐量敏感)少的聚結。不同品牌和型號的網絡接口卡具有不同的功能和默認設置,因此請參閱適配器和驅動程序的制造商文檔。
在此系統上,默認啟用自適應RX:
# ethtool -c eth3 Coalesce parameters for eth3:
Adaptive RX: on TX: off
stats-block-usecs: 0
sample-interval: 0
pkt-rate-low: 400000
pkt-rate-high: 450000
rx-usecs: 16
rx-frames:44
rx-usecs-irq: 0
rx-frames-irq: 0
以下命令關閉自適應IC,並通知適配器在接收到任何流量後立即中斷內核:
# ethtool -C eth3 adaptive-rx off rx-usecs 0 rx-frames 0
比較理想的設置是允許至少一些分組在NIC中緩沖,並且在中斷內核之前至少有一些時間通過。 有效范圍可以從1到數百,取決於系統能力和接收的流量
The Adapter Queue
netdev_max_backlog是Linux內核中的隊列,其中流量在從NIC接收之後但在由協議棧(IP,TCP等)處理之前存儲。 每個CPU核心有一個積壓隊列。 給定核心的隊列可以自動增長,包含的數據包數量可達netdev_max_backlog設置指定的最大值。 netif_receive_skb()內核函數將為數據包找到相應的CPU,並將數據包排入該CPU的隊列。 如果該處理器的隊列已滿並且已達到最大大小,則將丟棄數據包。 要調整此設置,首先確定積壓是否需要增加。 / proc / net / softnet_stat文件在第2列中包含一個計數器,該值在netdev backlog隊列溢出時遞增。 如果此值隨時間增加,則需要增加netdev_max_backlog。
softnet_stat文件的每一行代表一個從CPU0開始的CPU內核:
第一列是中斷處理程序接收的幀數。 第2列是由於超過netdev_max_backlog而丟棄的幀數。 第三列是ksoftirqd跑出netdev_budget或CPU時間的次數。
其他列可能會根據版本Red Hat Enterprise Linux而有所不同。 使用以下示例,CPU0和CPU1的以下計數器是前兩行:
# cat softnet_stat
0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000002a 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
對於上面的示例,netdev_max_backlog不需要更改,因為丟棄數量保持在0:For CPU0
Total droppedno_budget lock_contention
0073d76b 00000000 000049ae 00000000
For CPU1
Total droppedno_budget lock_contention
000000d2 00000000 00000000 00000000
每列中的統計信息以十六進制提供。 默認的netdev_max_backlog值為1000.然而,這對於以1Gbps操作的多個接口,或甚至以10Gbps的單個接口來說可能是不夠的。 嘗試將此值加倍並觀察/ proc / net / softnet_stat文件。 如果值加倍,則降低丟包增加的速率,再次加倍並再次測試。 重復此過程,直到建立最佳大小,並且丟包率不增加。 可以使用以下命令更改積壓,其中X是要設置的所需值: # sysctl -w net.core.netdev_max_backlog=X Adapter RX and TX Buffer Tuning 適配器緩沖區默認值通常設置為小於最大值。 通常,增加接收緩沖區大小單獨足以防止數據包丟棄,因為它可以允許內核略微更多的時間來排空緩沖區。 結果,這可以防止可能的分組丟失。 以下接口具有8 KB緩沖區的空間,但僅使用1 KB: # ethtool -g eth3 Ring parameters for eth3: Pre-set maximums: RX: 8192 RX Mini: 0 RX Jumbo: 0 TX: 8192 Current hardware settings: RX: 1024 RX Mini: 0 RX Jumbo: 0 TX: 512 將RX和TX緩沖器增加到最大值: # ethtool -G eth3 rx 8192 tx 8192 Adapter Transmit Queue Length 傳輸隊列長度值確定在傳輸之前可以排隊的數據包數。 默認值1000通常適用於當今的高速10Gbps或甚至40Gbps網絡。 但是,如果適配器上的數字傳輸錯誤正在增加(紅色部分統計),請考慮將其倍增。vpp2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::14f7:b8ff:fe72:a52f prefixlen 64 scopeid 0x20<link>
ether 16:f7:b8:72:a5:2f txqueuelen 1000 (Ethernet)
RX packets 15905 bytes 1534810 (1.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 15905 bytes 1534810 (1.4 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
卸載設置由ethtool -K ethX管理。
常用設置包括:
•GRO:通用接收卸載
•LRO:大型接收卸載
•TSO:TCP分段卸載
•RX校驗和=接收數據完整性處理
•TX校驗和=發送數據完整性處理(TSO所需)
Jumbo Frames
默認802.3以太網幀大小為1518字節,或1522字節帶有VLAN標記。 以太網報頭使用此字節的18個字節(或22個帶VLAN標記的字節),留下1500字節的有效最大有效載荷。 巨型幀是對以太網的非正式擴展,網絡設備供應商已經做出了事實上的標准,將有效載荷從1500增加到9000字節。
對於常規的以太網幀,每個放置在線路上的1500字節數據有18字節的開銷,或者1.2%的開銷。使用巨幀,每個9000字節的數據放置在線上有18字節的開銷,或0.2%的開銷。以上計算假設沒有VLAN標簽,然而這樣的標簽將向開銷增加4個字節,使得效率增益更加理想。當傳輸大量連續數據時,例如在兩個系統之間發送大文件,可以通過使用巨幀獲得上述效率。當傳輸少量數據(例如通常低於1500字節的web請求)時,可能沒有從使用較大幀大小看到的增益,因為通過網絡的數據將被包含在小幀內。對於要配置的巨幀,網絡段(即廣播域)中的所有接口和網絡設備必須支持巨幀並啟用增加的幀大小。
TCP Timestamps
TCP時間戳是TCP協議的擴展,定義在RFC 1323 - TCP Extensions for High Performance - http://tools.ietf.org/html/rfc1323
TCP時間戳提供單調遞增計數器(在Linux上,計數器是自系統引導以來的毫秒),其可以用於更好地估計TCP對話的往返時間,導致更准確的TCP窗口和緩沖器計算。最重要的是,TCP時間戳還提供防止包裝序列號,因為TCP報頭將序列號定義為32位字段。給定足夠快的鏈路,該TCP序列號可以包裝。這導致接收器相信具有包裝數的段實際上比其先前段更早到達,並且不正確地丟棄該段。在1吉比特每秒鏈路上,TCP序列號可以在17秒內換行。在10吉比特每秒的鏈路上,這被減少到少至1.7秒。在快速鏈路上,啟用TCP時間戳應視為強制。 TCP時間戳提供了一種替代的非循環方法來確定段的年齡和順序,防止包裝的TCP序列號成為問題。
Ensure TCP Timestamps are enabled:
# sysctl net.ipv4.tcp_timestamps net.ipv4.tcp_timestamps = 1
If the above command indicates that tcp_timestamps = 0, enable TCP Timestamps:
# sysctl -w net.ipv4.tcp_timestamps=1
TCP SACK
基本TCP確認(ACK)僅允許接收器通知發送器已經接收到哪些字節。 當丟包發生時,這要求發送方從丟失點重傳所有字節,這可能是低效的。 SACK允許發送方指定哪些字節已經丟失以及哪些字節已經被接收,因此發送方只能重傳丟失的字節。 在網絡社區有一些研究表明啟用高帶寬鏈路上的SACK可能導致不必要的CPU周期用於計算SACK值,降低TCP連接的整體效率。 這項研究意味著這些鏈路是如此之快,重傳少量數據的開銷小於作為選擇性確認的一部分計算提供的數據的開銷。 除非有高延遲或高數據包丟失,最有可能更好地保持SACK關閉在高性能網絡。 SACK可以使用內核可調參數關閉:
# sysctl -w net.ipv4.tcp_sack=0
TCP Window Scaling
在原始TCP定義中,TCP段報頭僅包含用於TCP窗口大小的8位值,這對於現代計算的鏈路速度和存儲器能力是不足的。 引入了TCP Window Scaling擴展以允許更大的TCP接收窗口。 這是通過向在TCP報頭之後添加的TCP選項添加縮放值來實現的。 真實的TCP接收窗口向左移位縮放因子值的值,最大大小為1,073,725,440字節,或接近1千兆字節。 TCP窗口縮放是在打開每個TCP對話的三次TCP握手(SYN,SYN + ACK,ACK)期間協商的。 發送方和接收方都必須支持“窗口縮放”窗口縮放選項才能工作。 如果一個或兩個參與者在它們的握手中不公布窗口縮放能力,則會話回退到使用原始的8位TCP窗口大小。
默認情況下,在Red Hat Enterprise Linux上啟用TCP窗口縮放。 窗口縮放的狀態可以使用命令確認:
# sysctl net.ipv4.tcp_window_scaling
net.ipv4.tcp_window_scaling = 1
TCP窗口縮放協商可以通過捕獲打開對話的TCP握手的數據包來查看。 在數據包捕獲中,檢查三個握手數據包的TCP選項字段。 如果任一系統的握手數據包不包含TCP窗口縮放選項,則可能需要在該系統上啟用TCP窗口縮放。
TCP Buffer Tuning
一旦從網絡適配器處理網絡流量,就嘗試直接接收到應用中。 如果不可能,數據在應用程序的套接字緩沖區上排隊。 套接字中有3個隊列結構
sk_rmem_alloc = { counter = 121948 },
sk_wmem_alloc = { counter = 553 },
sk_omem_alloc = { counter = 0
sk_rmem_alloc是接收隊列
sk_wmem_alloc是發送隊列
sk_omem_alloc是無序隊列,不在當前TCP窗口內的skbs被放置在此隊列中
還有sk_rcvbuf變量,它代表scoket可以接受的字節數。
例如:
當sk_rcvbuf = 125336
從上面的輸出可以計算出接收隊列幾乎已滿。 當sk_rmem_alloc> sk_rcvbuf時,TCP棧將調用“收縮”接收隊列的例程。 這是一種管家,內核將通過減少開銷來嘗試釋放接收隊列中的可用空間。 然而,這種操作帶來了CPU成本。 如果崩潰無法釋放足夠的空間用於附加流量,則數據被“修剪”,意味著數據從存儲器丟棄,並且分組丟失。 因此,最好圍繞這個條件,避免緩沖區折疊和修剪。 第一步是識別緩沖區折疊和修剪是否正在發生。# netstat -sn | egrep “prune|collap”; sleep 30; netstat -sn | egrep “prune|collap”
17671 packets pruned from receive queue because of socket buffer overrun
18671 packets pruned from receive queue because of socket buffer overrun
如果在此間隔期間數字增加,則需要調整。 第一步是增加網絡和TCP接收緩沖區設置。 這是檢查應用程序是否調用setsockopt(SO_RCVBUF)的好時機。 如果應用程序調用此函數,這將覆蓋默認設置,並關閉套接字自動調整其大小的能力。 接收緩沖區的大小將是應用程序指定的大小。 考慮從應用程序中刪除setsockopt(SO_RCVBUF)函數調用,並允許緩沖區大小自動調整。
Tuning tcp_rmem
套接字內存可調參數有三個值,描述最小值,默認值和最大值(以字節為單位)。 大多數Red Hat Enterprise Linux版本的默認最大值為4MiB。 要查看這些設置,請將其增加4倍:
# sysctl net.ipv4.tcp_rmem
4096 87380 4194304
# sysctl -w net.ipv4.tcp_rmem=“16384 349520 16777216”
# sysctl net.core.rmem_max 4194304
# sysctl -w net.core.rmem_max=16777216
如果應用程序無法更改為刪除setsockopt(SO_RCVBUF),則增加最大套接字接收緩沖區大小,這可以使用SO_RCVBUF套接字選項設置。 僅當更改tcp_rmem的中間值時,才需要重新啟動應用程序。 更改tcp_rmem的第3個和最大值不需要重新啟動應用程序,因為這些值是通過自動調整動態分配的。
TCP Listen Backlog
當TCP套接字由處於LISTEN狀態的服務器打開時,該套接字具有其可以處理的最大數量的未接受的客戶端連接。 如果應用程序在處理客戶端連接時速度很慢,或者服務器快速獲得許多新連接(通常稱為SYN Flood),則新連接可能丟失,或者可能會發送稱為“SYN cookie”的特制回復包。 如果系統的正常工作負載使得SYN cookie經常被輸入到系統日志中,則應調整系統和應用程序以避免它們。
應用程序可以請求的最大積壓由net.core.somaxconn內核可調參數決定。 應用程序可以總是請求更大的積壓,但它只會得到一個大到這個最大值的積壓。 可以如下檢查和更改此參數
# sysctl net.core.somaxconn net.core.somaxconn = 128
# sysctl -w net.core.somaxconn=2048 net.core.somaxconn = 2048
# sysctl net.core.somaxconn net.core.somaxconn = 2048
更改最大允許積壓量後,必須重新啟動應用程序才能使更改生效。 此外,在更改最大允許積壓之後,必須修改應用程序以在其偵聽套接字上實際設置較大的積壓。 下面是一個在C語言中增加套接字積壓所需的更改的示例:
- rc = listen(sockfd, 128);
+ rc = listen(sockfd, 2048);
if (rc < 0) {
perror("listen() failed");
close(sockfd);
exit(-1);
}
上述更改將需要從源代碼重新編譯應用程序。 如果應用程序設計為積壓是一個可配置的參數,這可以在應用程序的設置中更改,並且不需要重新編譯。
Advanced Window Scaling
您可能會看到“修剪”錯誤繼續增加,無論上述設置如何。在Red Hat Enterprise Linux 6.3和6.4中,有一個提交被添加到收取skb共享結構到套接字的成本,在內核更新日志中描述為[net]更准確的skb truesize。這種改變具有更快地填充TCP接收隊列的效果,因此更快地擊中修剪條件。此更改已在Red Hat Enterprise Linux 6.5中恢復。如果接收緩沖區增加並且修剪仍然發生,則參數net.ipv4.tcp_adv_win_scale決定分配給數據的接收緩沖區與被通告為可用TCP窗口的緩沖區的比率。 Red Hat Enterprise Linux 5和6上的默認值為2,等於分配給應用程序數據的緩沖區的四分之一。在RedHat Enterprise Linux 7版本上,此默認值為1,導致一半的空間被通告為TCP窗口。在Red Hat Enterprise Linux 5和6上將此值設置為1將會減少通告的TCP窗口的影響,可能會阻止接收緩沖區溢出,從而阻止緩沖區修剪。
# sysctl net.ipv4.tcp_adv_win_scale 2
# sysctl -w net.ipv4.tcp_adv_win_scale=1
UDP Buffer Tuning
UDP是一個比TCP簡單得多的協議。 由於UDP不包含會話可靠性,因此應用程序有責任識別和重新傳輸丟棄的數據包。 沒有窗口大小的概念,並且協議不恢復丟失的數據。 唯一可用的調諧包括增加接收緩沖區大小。 但是,如果netstat -us報告錯誤,另一個潛在的問題可能會阻止應用程序排空其接收隊列。 如果netstat -us顯示“數據包接收錯誤”,請嘗試增加接收緩沖區並重新測試。 該統計量還可以由於其他原因而遞增,諸如有效載荷數據小於UDP報頭建議的短分組或者其校驗和計算失敗的損壞分組,因此如果緩沖區調諧不需要,則可能需要更深入的調查 解決UDP接收錯誤。 UDP緩沖區可以以類似於最大TCP緩沖區的方式調整:
# sysctl net.core.rmem_max
124928
# sysctl -w net.core.rmem_max=16777216
更改最大大小後,需要重新啟動應用程序以使新設置生效。
RSS: Receive Side Scaling
RSS由許多常見的網絡接口卡支持。 在接收數據時,NIC可以將數據發送到多個隊列。 每個隊列可以由不同的CPU服務,允許有效的數據檢索。 RSS充當驅動程序和卡固件之間的API,以確定數據包如何跨CPU核心分布,其想法是將流量引導到不同CPU的多個隊列允許更快的吞吐量和更低的延遲。 RSS控制哪些接收隊列獲得任何給定的分組,無論卡是否偵聽特定的單播以太網地址,它偵聽的多播地址,哪個隊列對或以太網隊列獲得多播分組的副本等。
RSS Considerations
驅動程序是否允許配置隊列數量
某些驅動程序將根據硬件資源自動生成引導期間的隊列數。 對於其他,它可以通過ethtool -L進行配置。
•系統有多少個內核應配置RSS,以便每個隊列轉到不同的CPU內核。
RPS: Receive Packet Steering
接收數據包轉向是RSS的內核級軟件實現。 它駐留在驅動程序上方的網絡堆棧的較高層。 RSS或RPS應該是互斥的。 默認情況下禁用RPS。 RPS使用保存在數據包定義的rxhash字段中的2元組或4元組哈希,用於確定應該處理給定數據包的CPU隊列。
RFS: Receive Flow Steering
接收流轉向在引導分組時考慮應用局部性。 這避免了當流量到達運行應用程序的不同CPU核心時的高速緩存未命中。