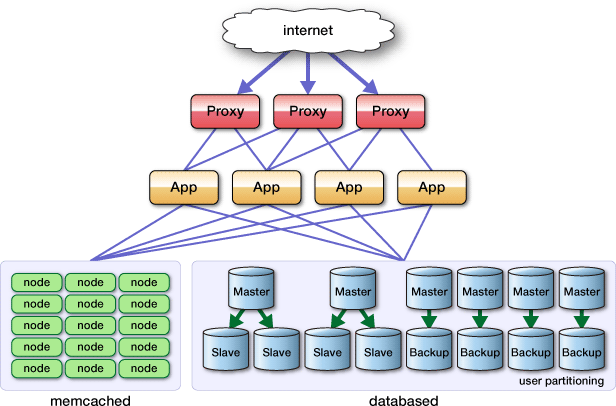
使用storm可以方便的構建一種集群式的數據框架,並通過定義topo來實現業務邏輯。
但使用topo存在一個缺點, topo的處理能力來自於其啟動時設置的worker數目,在很多情況下,我們需要能夠根據業務壓力來調整集群的處理能力,這時候單一的topo就無法解決這個問題了。
為了能夠更加靈活的定義處理能力,可以考慮將原有的topo根據業務域進行拆分,做到互不干擾,靈活控制,而且為了能夠更加經濟的利用處理資源,可以考慮引入worker資源池的概念,達到對資源的充分利用。
但使用這種多topo架構存在一個致命問題,storm中的topo是各自獨立,無法直接通信的,因此在獲取某些關鍵資源時,可能會出現資源爭搶的情況的。面對此種場景,有兩種處理思路:
其一:使用zookeeper等提供的分布式鎖,來實現對關鍵資源的控制,缺點是可靠性及效率存在問題,使用與對處理效率要求不高的場景。
其二:由第三方對關鍵資源進行分配,規避由topo本身對資源的爭搶,這種方案引入了新的構建,提高了系統的復雜度。
集群的優點是處理能力可擴展,但會帶來數據同步、開發維護復雜度以及數據一致性等問題。
我們現在雖然已經有了很多集群處理框架及相應組件用來簡化相應的開發及維護工作量,但從項目開發的實際來看,我們還是需要處理一些沒有被成熟組件包含但又非常棘手的問題。
storm定義的集群可以提供方便的可擴展處理能力,在整個集群中,topo都是等價的,在storm運行環境內部,topo之間也無法交流。
回到上面的問題,通過storm,我們獲得了即時的集群處理能力;通過topo,我們可以自定義業務,並方便的在節點中分發;通過worker數目的變化,可以調整其處理能力。
如果輔以Hadoop等大數據存儲平台及Redis緩存,加以使用zookeeper構成的分布式鎖,已經基本可以構建一套即時的可擴展的大數據處理平台。
下面是一個基於storm的多拓撲初始化的類視圖:
因為是即時的數據處理平台,其存在對效率的要求,而數據庫存儲的訪問通常稱為瓶頸,因此在此設計了緩存,選型Redis是引起使用已經較為廣泛和穩定,業界也存在較為成熟的緩存構建策略。
分布式鎖至關重要,尤其是如果storm集群中存在多個topo的情況下,非常可能存在對關鍵資源的爭奪。
使用zookeeper構建分布式鎖已經存在較為成為的應用,但使用zookeeper構建的分布式鎖必定也存在健壯性不足和鎖的效率問題,需要在設計時加以考慮。
從使用成本和使用場景上,這兩個組件就存在很大不同。
在應用時,Hadoop可以用以存儲非結構化的數據,例如原始結果。由於Oracle在存儲結構化數、可靠性以及易用性上的巨大優勢,可以選擇將最終處理結果存放於Oracle之中,利於維護和展示。
Storm如何分配任務和負載均衡? http://www.linuxidc.com/Linux/2015-07/120466.htm
Storm進程通信機制分析 http://www.linuxidc.com/Linux/2014-12/110158.htm
Apache Storm 的歷史及經驗教訓 http://www.linuxidc.com/Linux/2014-10/108544.htm
Apache Storm 的詳細介紹:請點這裡
Apache Storm 的下載地址:請點這裡