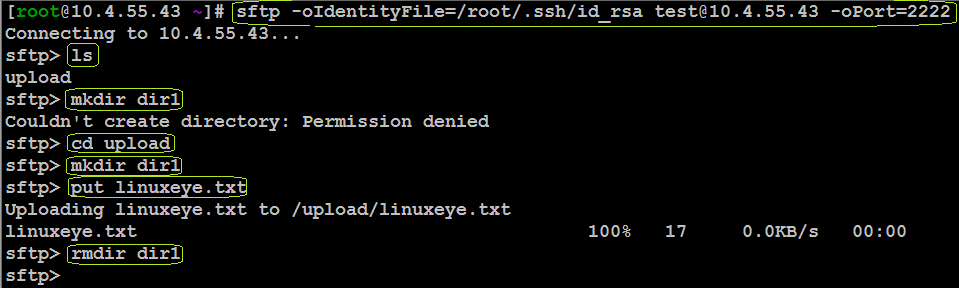
這是一款提取網站數據的開源工具。Scrapy框架用Python開發而成,它使抓取工作又快又簡單,且可擴展。我們已經在virtual box中創建一台虛擬機(VM)並且在上面安裝了Ubuntu 14.04 LTS。
Scrapy依賴於Python、開發庫和pip。Python最新的版本已經在Ubuntu上預裝了。因此我們在安裝Scrapy之前只需安裝pip和python開發庫就可以了。
pip是作為python包索引器easy_install的替代品,用於安裝和管理Python包。pip包的安裝可見圖 1。
sudo apt-get install python-pip圖:1 pip安裝
我們必須要用下面的命令安裝python開發庫。如果包沒有安裝那麼就會在安裝scrapy框架的時候報關於python.h頭文件的錯誤。
sudo apt-get install python-dev圖:2 Python 開發庫
scrapy框架既可從deb包安裝也可以從源碼安裝。在圖3中我們用pip(Python 包管理器)安裝了deb包了。
sudo pip install scrapy 圖:3 Scrapy 安裝
圖4中scrapy的成功安裝需要一些時間。
圖:4 成功安裝Scrapy框架
我們將用scrapy從fatwallet.com上提取商店名稱(賣卡的店)。首先,我們使用下面的命令新建一個scrapy項目“store name”, 見圖5。
$sudo scrapy startproject store_name圖:5 Scrapy框架新建項目
上面的命令在當前路徑創建了一個“store_name”的目錄。項目主目錄下包含的文件/文件夾見圖6。
$sudo ls –lR store_name圖:6 store_name項目的內容
每個文件/文件夾的概要如下:
由於我們要從fatwallet.com上如提取店名,因此我們如下修改文件(LCTT 譯注:這裡沒說明是哪個文件,譯者認為應該是 items.py)。
import scrapyclassStoreNameItem(scrapy.Item):name = scrapy.Field()# 取出卡片商店的名稱之後我們要在項目的store_name/spiders/文件夾下寫一個新的蜘蛛。蜘蛛是一個python類,它包含了下面幾個必須的屬性:
我們在storename/spiders/目錄下創建了“storename.py”爬蟲,並添加如下的代碼來從fatwallet.com上提取店名。爬蟲的輸出寫到文件(StoreName.txt)中,見圖7。
from scrapy.selector importSelectorfrom scrapy.spider importBaseSpiderfrom scrapy.http importRequestfrom scrapy.http importFormRequestimport reclassStoreNameItem(BaseSpider):name ="storename"allowed_domains =["fatwallet.com"]start_urls =["http://fatwallet.com/cash-back-shopping/"]def parse(self,response):output = open('StoreName.txt','w')resp =Selector(response)tags = resp.xpath('//tr[@class="storeListRow"]|\//tr[@class="storeListRow even"]|\//tr[@class="storeListRow even last"]|\//tr[@class="storeListRow last"]').extract()for i in tags:i = i.encode('utf-8','ignore').strip()store_name =''if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()store_name = re.search(r">.*?<",store_name,re.I|re.S).group()store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))#print store_nameoutput.write(store_name+""+"\n")圖:7 爬蟲的輸出
注意: 本教程的目的僅用於理解scrapy框架
更多Ubuntu相關信息見Ubuntu 專題頁面 http://www.linuxidc.com/topicnews.aspx?tid=2