1,Linux系統的平均負載是什麼?
特定時間間隔內運行隊列中的平均進程數,好象還不夠明白:就是進程隊列的長度,有多少個進程在排隊等待運行
2,什麼是"進程隊列"?
一個進程滿足以下條件就會位於進程隊列中
1,它沒有在等待I/O操作的結果
2,它沒有主動進入等待狀態(即沒有調用wait)
3,它沒有被停止
3,如何查看平均負載?
最簡單的命令是uptime
例子:
[www.linuxidc.com @localhost ~]$ uptime
00:44:22 up 1:17, 3 users, load average: 8.13, 5.90, 4,94
4,顯示的內容是什麼意思?
load average: 8.13,5.90,4,94
顯示的是過去的1,5,15分鐘內進程隊列中的平均進程數量
5,如何衡量當前系統是否負載過高?
如果每個cpu(可以按CPU核心的數量計算)上當前活動進程數不大於3,則系統性能良好,
不大於4,表示可以接受
如大於5,則系統性能問題嚴重
上面例中的8.13,如果有2個cpu核心,則8.13/2=4.065, 此系統性能可以接受
建議設置嚴格的報警值為: CPU核心的數量
比如:CPU核心數量為2,則設置報警值為2
(這樣設置是合理的,因為畢竟不是每個應用都支持多CPU及多核心)
6,查看平均負載的命令
有5個可用:
tload 能夠繪制出負載變化的圖形
uptime 同時顯示開機以來的時間
w 同時顯示出已登錄的用戶
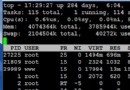
top 這個對資源占用太高,不建議使用
cat /proc/loadavg 通過/proc系統信息得到平均負載
注意:如果你要持續的觀察平均負載,建議用 watch uptime 或 watch cat /proc/loadavg
備注:關於watch:每隔一定時間執行指定的程序,並全屏顯示結果。時間默認是2秒。