Linux Netfilter實現機制和擴展技術
楊沙洲 (pubb@163.net)國防科技大學計算機學院
簡介: 本文從Linux網絡協議棧中報文的流動過程分析開始,對Linux 2.4.x內核中最流行的防火牆構建平台Netfilter進行了深入分析,著重介紹了如何在Netfilter-iptables機制中進行應用擴展,並在文末給出了一個利用擴展Netfilter-iptables實現VPN的方案。
2.4.x的內核相對於2.2.x在IP協議棧部分有比較大的改動, Netfilter-iptables更是其一大特色,由於它功能強大,並且與內核完美結合,因此迅速成為Linux平台下進行網絡應用擴展的主要利器,這些擴展不僅包括防火牆的實現--這只是Netfilter-iptables的基本功能--還包括各種報文處理工作(如報文加密、報文分類統計等),甚至還可以借助Netfilter-iptables機制來實現虛擬專用網(VPN)。本文將致力於深入剖析Netfilter-iptables的組織結構,並詳細介紹如何對其進行擴展。Netfilter目前已在ARP、IPv4和IPv6中實現,考慮到IPv4是目前網絡應用的主流,本文僅就IPv4的Netfilter實現進行分析。
要想理解Netfilter的工作原理,必須從對Linux IP報文處理流程的分析開始,Netfilter正是將自己緊密地構建在這一流程之中的。
1. IP Packet Flowing
IP協議棧是Linux操作系統的主要組成部分,也是Linux的特色之一,素以高效穩定著稱。Netfilter與IP協議棧是密切結合在一起的,要想理解Netfilter的工作方式,必須理解IP協議棧是如何對報文進行處理的。下面將通過一個經由IP Tunnel傳輸的TCP報文的流動路徑,簡要介紹一下IPv4協議棧(IP層)的結構和報文處理過程。
IP Tunnel是2.0.x內核就已經提供了的虛擬局域網技術,它在內核中建立一個虛擬的網絡設備,將正常的報文(第二層)封裝在IP報文中,再通過TCP/IP網絡進行傳送。如果在網關之間建立IP Tunnel,並配合ARP報文的解析,就可以實現虛擬局域網。
我們從報文進入IP Tunnel設備准備發送開始。
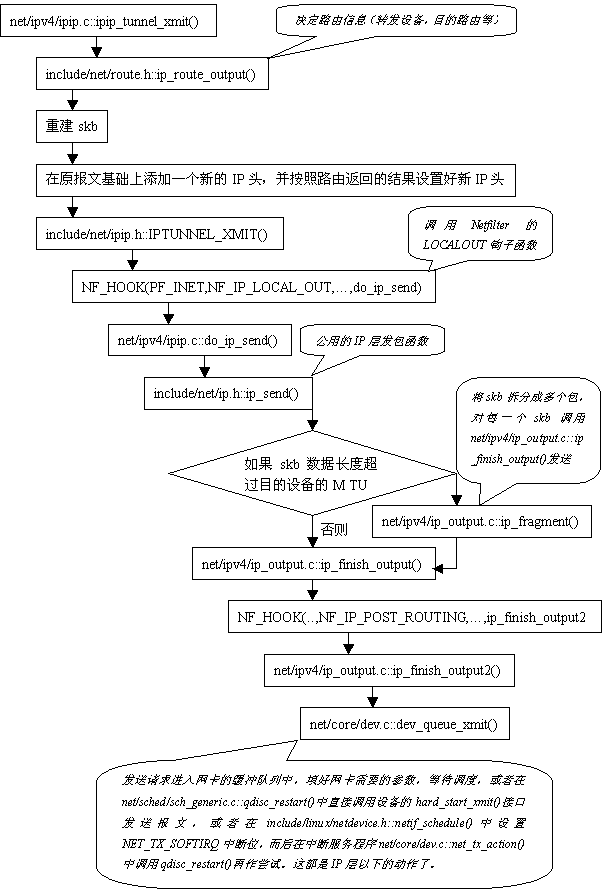
1.1報文發送
ipip模塊創建tunnel設備(設備名為tunl0~tunlx)時,設置報文發送接口(hard_start_xmit)為ipip_tunnel_xmit(),流程見下圖:
圖1 報文發送流程
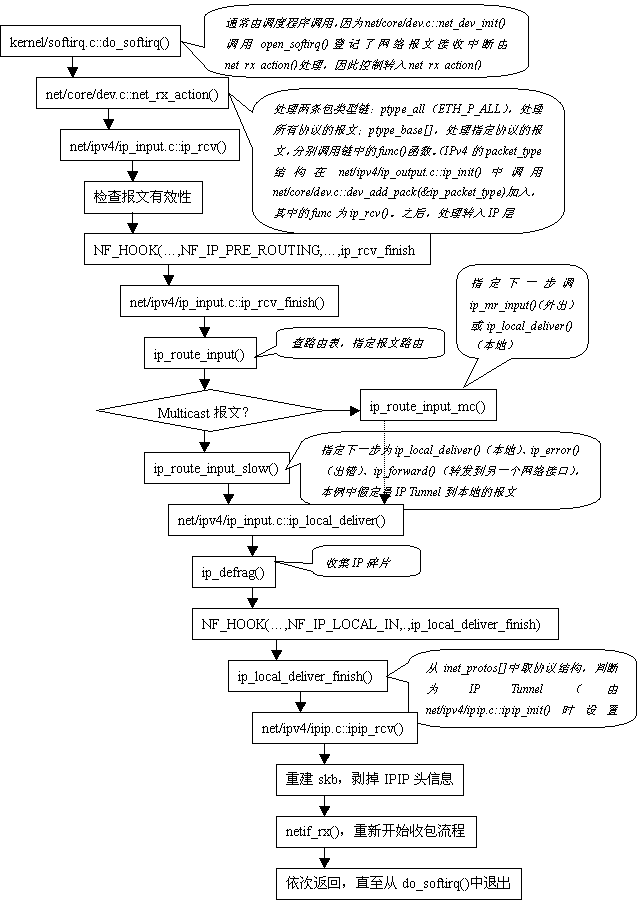
1.2 報文接收
報文接收從網卡驅動程序開始,當網卡收到一個報文時,會產生一個中斷,其驅動程序中的中斷服務程序將調用確定的接收函數來處理。以下仍以IP Tunnel報文為例,網卡驅動程序為de4x5。流程分成兩個階段:驅動程序中斷服務程序階段和IP協議棧處理階段,見下圖:
圖2 報文接收流程之驅動程序階段

圖3 報文接收流程之協議棧階段
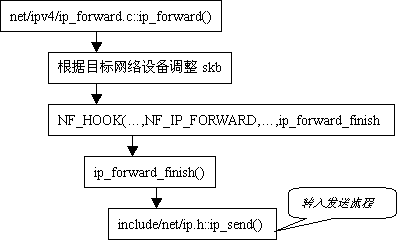
如果報文需要轉發,則在上圖紅箭頭所指處調用ip_forward():
圖4 報文轉發流程
從上面的流程可以看出,Netfilter以NF_HOOK()的形式出現在報文處理的過程之中。
回頁首
2. Netfilter Frame
Netfilter是2.4.x內核引入的,盡管它提供了對2.0.x內核中的ipfw以及2.2.x內核中的ipchains的兼容,但實際上它的工作和意義遠不止於此。從上面對IP報文的流程分析中可以看出,Netfilter和IP報文的處理是完全結合在一起的,同時由於其結構相對獨立,又是可以完全剝離的。這種機制也是Netfilter-iptables既高效又靈活的保證之一。
在剖析Netfilter機制之前,我們還是由淺入深的從Netfilter的使用開始。
2.1 編譯
在Networking Options中選定Network packet filtering項,並將其下的IP:Netfilter Configurations小節的所有選項設為Module模式。編譯並安裝新內核,然後重啟,系統的核內Netfilter就配置好了。以下對相關的內核配置選項稍作解釋,也可以參閱編譯系統自帶的Help:
【Kernel/User netlink socket】建立一類PF_NETLINK套接字族,用於核心與用戶進程通信。當Netfilter需要使用用戶隊列來管理某些報文時就要使用這一機制;
【Network packet filtering (replaces ipchains)】Netfilter主選項,提供Netfilter框架;
【Network packet filtering debugging】Netfilter主選項的分支,支持更詳細的Netfilter報告;
【IP: Netfilter Configuration】此節下是netfilter的各種選項的集合:
【Connection tracking (required for masq/NAT)】連接跟蹤,用於基於連接的報文處理,比如NAT;
【IP tables support (required for filtering/masq/NAT)】這是Netfilter的框架,NAT等應用的容器;
【ipchains (2.2-style) support】ipchains機制的兼容代碼,在新的Netfilter結構上實現了ipchains接口;
【ipfwadm (2.0-style) support】2.0內核防火牆ipfwadm兼容代碼,基於新的Netfilter實現。
2.2 總體結構
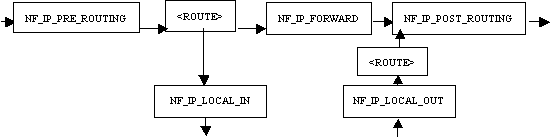
Netfilter是嵌入內核IP協議棧的一系列調用入口,設置在報文處理的路徑上。網絡報文按照來源和去向,可以分為三類:流入的、流經的和流出的,其中流入和流經的報文需要經過路由才能區分,而流經和流出的報文則需要經過投遞,此外,流經的報文還有一個FORWARD的過程,即從一個NIC轉到另一個NIC。Netfilter就是根據網絡報文的流向,在以下幾個點插入處理過程:
NF_IP_PRE_ROUTING,在報文作路由以前執行;
NF_IP_FORWARD,在報文轉向另一個NIC以前執行;
NF_IP_POST_ROUTING,在報文流出以前執行;
NF_IP_LOCAL_IN,在流入本地的報文作路由以後執行;
NF_IP_LOCAL_OUT,在本地報文做流出路由前執行。
如圖所示:
圖5 Netfilter HOOK位置
Netfilter框架為多種協議提供了一套類似的鉤子(HOOK),用一個struct list_head nf_hooks[NPROTO][NF_MAX_HOOKS]二維數組結構存儲,一維為協議族,二維為上面提到的各個調用入口。每個希望嵌入Netfilter中的模塊都可以為多個協議族的多個調用點注冊多個鉤子函數(HOOK),這些鉤子函數將形成一條函數指針鏈,每次協議棧代碼執行到NF_HOOK()函數時(有多個時機),都會依次啟動所有這些函數,處理參數所指定的協議棧內容。
每個注冊的鉤子函數經過處理後都將返回下列值之一,告知Netfilter核心代碼處理結果,以便對報文采取相應的動作:
NF_ACCEPT:繼續正常的報文處理;
NF_DROP:將報文丟棄;
NF_STOLEN:由鉤子函數處理了該報文,不要再繼續傳送;
NF_QUEUE:將報文入隊,通常交由用戶程序處理;
NF_REPEAT:再次調用該鉤子函數。
2.3 IPTables
Netfilter-iptables由兩部分組成,一部分是Netfilter的"鉤子",另一部分則是知道這些鉤子函數如何工作的一套規則--這些規則存儲在被稱為iptables的數據結構之中。鉤子函數通過訪問iptables來判斷應該返回什麼值給Netfilter框架。
在現有(kernel 2.4.21)中已內建了三個iptables:filter、nat和mangle,絕大部分報文處理功能都可以通過在這些內建(built-in)的表格中填入規則完成:
filter,該模塊的功能是過濾報文,不作任何修改,或者接受,或者拒絕。它在NF_IP_LOCAL_IN、NF_IP_FORWARD和NF_IP_LOCAL_OUT三處注冊了鉤子函數,也就是說,所有報文都將經過filter模塊的處理。
nat,網絡地址轉換(Network Address Translation),該模塊以Connection Tracking模塊為基礎,僅對每個連接的第一個報文進行匹配和處理,然後交由Connection Tracking模塊將處理結果應用到該連接之後的所有報文。nat在NF_IP_PRE_ROUTING、NF_IP_POST_ROUTING注冊了鉤子函數,如果需要,還可以在NF_IP_LOCAL_IN和NF_IP_LOCAL_OUT兩處注冊鉤子,提供對本地報文(出/入)的地址轉換。nat僅對報文頭的地址信息進行修改,而不修改報文內容,按所修改的部分,nat可分為源NAT(SNAT)和目的NAT(DNAT)兩類,前者修改第一個報文的源地址部分,而後者則修改第一個報文的目的地址部分。SNAT可用來實現IP偽裝,而DNAT則是透明代理的實現基礎。
mangle,屬於可以進行報文內容修改的IP Tables,可供修改的報文內容包括MARK、TOS、TTL等,mangle表的操作函數嵌入在Netfilter的NF_IP_PRE_ROUTING和NF_IP_LOCAL_OUT兩處。
內核編程人員還可以通過注入模塊,調用Netfilter的接口函數創建新的iptables。在下面的Netfilter-iptables應用中我們將進一步接觸Netfilter的結構和使用方式。
2.4 Netfilter配置工具
iptables是專門針對2.4.x內核的Netfilter制作的核外配置工具,通過socket接口對Netfilter進行操作,創建socket的方式如下:
socket(TC_AF, SOCK_RAW, IPPROTO_RAW)
其中TC_AF就是AF_INET。核外程序可以通過創建一個"原始IP套接字"獲得訪問Netfilter的句柄,然後通過getsockopt()和setsockopt()系統調用來讀取、更改Netfilter設置,詳情見下。
iptables功能強大,可以對核內的表進行操作,這些操作主要指對其中規則鏈的添加、修改、清除,它的命令行參數主要可分為四類:指定所操作的IP Tables(-t);指定對該表所進行的操作(-A、-D等);規則描述和匹配;對iptables命令本身的指令(-n等)。在下面的例子中,我們通過iptables將訪問10.0.0.1的53端口(DNS)的TCP連接引導到192.168.0.1地址上。
iptables -t nat -A PREROUTING -p TCP -i eth0 -d 10.0.0.1 --dport 53 -j DNAT --to-destination 192.168.0.1
由於iptables是操作核內Netfilter的用戶界面,有時也把Netfilter-iptables簡稱為iptables,以便與ipchains、ipfwadm等老版本的防火牆並列。
2.5 iptables核心數據結構
2.5.1 表
在Linux內核裡,iptables用struct ipt_table表示,定義如下(include/linux/netfilter_ipv4/ip_tables.h):
struct ipt_table
{
struct list_head list;
/* 表鏈 */
char name[IPT_TABLE_MAXNAMELEN];
/* 表名,如"filter"、"nat"等,為了滿足自動模塊加載的設計,
/* 包含該表的模塊應命名為iptable_'name'.o */
struct ipt_replace *table;
/* 表模子,初始為initial_table.repl */
unsigned int valid_hooks;
/* 位向量,標示本表所影響的HOOK */
rwlock_t lock;
/* 讀寫鎖,初始為打開狀態 */
struct ipt_table_info *private;
/* iptable的數據區,見下 */
struct module *me;
/* 是否在模塊中定義 */
};
struct ipt_table_info是實際描述表的數據結構(net/ipv4/netfilter/ip_tables.c):
struct ipt_table_info
{
unsigned int size;
/* 表大小 */
unsigned int number;
/* 表中的規則數 */
unsigned int initial_entries;
/* 初始的規則數,用於模塊計數 */
unsigned int hook_entry[NF_IP_NUMHOOKS];
/* 記錄所影響的HOOK的規則入口相對於下面的entries變量的偏移量 */
unsigned int underflow[NF_IP_NUMHOOKS];
/* 與hook_entry相對應的規則表上限偏移量,當無規則錄入時,
/* 相應的hook_entry和underflow均為0 */
char entries[0] ____cacheline_aligned;
/* 規則表入口 */
};例如內建的filter表初始定義如下(net/ipv4/netfilter/iptable_filter.c):
static struct ipt_table packet_filter
= { { NULL, NULL }, // 鏈表
"filter", // 表名
&initial_table.repl, // 初始的表模板
FILTER_VALID_HOOKS,// 定義為((1 << NF_IP6_LOCAL_IN) |
(1 << NF_IP6_FORWARD) | (1 << NF_IP6_LOCAL_OUT)),
即關心INPUT、FORWARD、OUTPUT三點
RW_LOCK_UNLOCKED,// 鎖
NULL, // 初始的表數據為空
THIS_MODULE // 模塊標示
};經過調用ipt_register_table(&packet_filter)後,filter表的private數據區即參照模板填好了。
2.5.2 規則
規則用struct ipt_entry結構表示,包含匹配用的IP頭部分、一個Target和0個或多個Match。由於Match數不定,所以一條規則實際的占用空間是可變的。結構定義如下(include/linux/netfilter_ipv4):
struct ipt_entry
{
struct ipt_ip ip;
/* 所要匹配的報文的IP頭信息 */
unsigned int nfcache;
/* 位向量,標示本規則關心報文的什麼部分,暫未使用 */
u_int16_t target_offset;
/* target區的偏移,通常target區位於match區之後,而match區則在ipt_entry的末尾;
初始化為sizeof(struct ipt_entry),即假定沒有match */
u_int16_t next_offset;
/* 下一條規則相對於本規則的偏移,也即本規則所用空間的總和,
初始化為sizeof(struct ipt_entry)+sizeof(struct ipt_target),即沒有match */
unsigned int comefrom;
/* 位向量,標記調用本規則的HOOK號,可用於檢查規則的有效性 */
struct ipt_counters counters;
/* 記錄該規則處理過的報文數和報文總字節數 */
unsigned char elems[0];
/*target或者是match的起始位置 */
}規則按照所關注的HOOK點,被放置在struct ipt_table::private->entries之後的區域,比鄰排列。
2.5.3 規則填寫過程
在了解了iptables在核心中的數據結構之後,我們再通過遍歷一次用戶通過iptables配置程序填寫規則的過程,來了解這些數據結構是如何工作的了。
一個最簡單的規則可以描述為拒絕所有轉發報文,用iptables命令表示就是:
iptables -A FORWARD -j DROP;
iptables應用程序將命令行輸入轉換為程序可讀的格式(iptables-standalone.c::main()::do_command(),然後再調用libiptc庫提供的iptc_commit()函數向核心提交該操作請求。在libiptc/libiptc.c中定義了iptc_commit()(即TC_COMMIT()),它根據請求設置了一個struct ipt_replace結構,用來描述規則所涉及的表(filter)和HOOK點(FORWARD)等信息,並在其後附接當前這條規則--一個struct
ipt_entry結構(實際上也可以是多個規則entry)。組織好這些數據後,iptc_commit()調用setsockopt()系統調用來啟動核心處理這一請求:
setsockopt(
sockfd,
//通過socket(TC_AF, SOCK_RAW, IPPROTO_RAW)創建的套接字,
//其中TC_AF即AF_INET
TC_IPPROTO, //即IPPROTO_IP
SO_SET_REPLACE, //即IPT_SO_SET_REPLACE
repl, //struct ipt_replace結構
sizeof(*repl) + (*handle)->entries.size) //ipt_replace加上後面的ipt_entry
核心對於setsockopt()的處理是從協議棧中一層層傳遞上來的,調用過程如下圖所示:
圖6 規則填寫過程
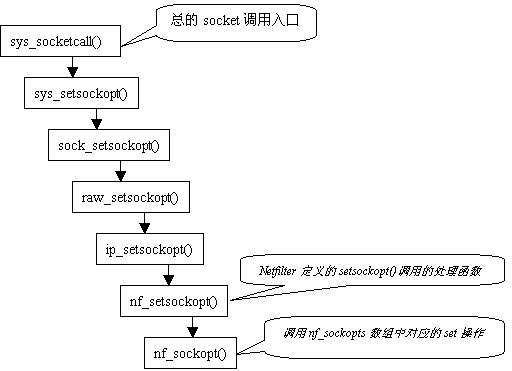
nf_sockopts是在iptables進行初始化時通過nf_register_sockopt()函數生成的一個struct nf_sockopt_ops結構,對於ipv4來說,在net/ipv4/netfilter/ip_tables.c中定義了一個ipt_sockopts變量(struct nf_sockopt_ops),其中的set操作指定為do_ipt_set_ctl(),因此,當nf_sockopt()調用對應的set操作時,控制將轉入net/ipv4/netfilter/ip_tables.c::do_ipt_set_ctl()中。
對於IPT_SO_SET_REPLACE命令,do_ipt_set_ctl()調用do_replace()來處理,該函數將用戶層傳入的struct ipt_replace和struct ipt_entry組織到filter(根據struct ipt_replace::name項)表的hook_entry[NF_IP_FORWARD]所指向的區域,如果是添加規則,結果將是filter表的private(struct ipt_table_info)項的hook_entry[NF_IP_FORWARD]和underflow[NF_IP_FORWARD]的差值擴大(用於容納該規則),private->number加1。
2.5.4 規則應用過程
以上描述了規則注入核內iptables的過程,這些規則都掛接在各自的表的相應HOOK入口處,當報文流經該HOOK時進行匹配,對於與規則匹配成功的報文,調用規則對應的Target來處理。仍以轉發的報文為例,假定filter表中添加了如上所述的規則:拒絕所有轉發報文。
如1.2節所示,經由本地轉發的報文經過路由以後將調用ip_forward()來處理,在ip_forward()返回前,將調用如下代碼:
NF_HOOK(PF_INET, NF_IP_FORWARD, skb, skb->dev, dev2, ip_forward_finish)
NF_HOOK是這樣一個宏(include/linux/netfilter.h):
#define NF_HOOK(pf, hook, skb, indev, outdev, okfn) \
(list_empty(&nf_hooks[(pf)][(hook)]) \
? (okfn)(skb) \
: nf_hook_slow((pf), (hook), (skb), (indev), (outdev), (okfn)))
也就是說,如果nf_hooks[PF_INET][NF_IP_FORWARD]所指向的鏈表為空(即該鉤子上沒有掛處理函數),則直接調用ip_forward_finish(skb)完成ip_forward()的操作;否則,則調用net/core/netfilter.c::nf_hook_slow()轉入Netfilter的處理。
這裡引入了一個nf_hooks鏈表二維數組:
struct list_head nf_hooks[NPROTO][NF_MAX_HOOKS];
每一個希望使用Netfilter掛鉤的表都需要將表處理函數在nf_hooks數組的相應鏈表上進行注冊。對於filter表來說,在其初始化(net/ipv4/netfilter/iptable_filter.c::init())時,調用了net/core/netfilter.c::nf_register_hook(),將預定義的三個struct nf_hook_ops結構(分別對應INPUT、FORWARD、OUTPUT鏈)連入鏈表中:
struct nf_hook_ops
{
struct list_head list;
//鏈表
nf_hookfn *hook;
//處理函數指針
int pf;
//協議號
int hooknum;
//HOOK號
int priority;
//優先級,在nf_hooks鏈表中各處理函數按優先級排序
};對於filter表來說,FORWARD點的hook設置成ipt_hook(),它將直接調用ipt_do_table()。幾乎所有處理函數最終都將調用ipt_do_table()來查詢表中的規則,以調用對應的target。下圖所示即為在FORWARD點上調用nf_hook_slow()的過程:
圖7 規則應用流程
2.5.5 Netfilter的結構特點
由上可見,nf_hooks鏈表數組是聯系報文處理流程和iptables的紐帶,在iptables初始化(各自的init()函數)時,一方面調用nf_register_table()建立規則容器,另一方面還要調用nf_register_hook()將自己的掛鉤願望表達給Netfilter框架。初始化完成之後,用戶只需要通過用戶級的iptables命令操作規則容器(添加規則、刪除規則、修改規則等),而對規則的使用則完全不用操心。如果一個容器內沒有規則,或者nf_hooks上沒有需要表達的願望,則報文處理照常進行,絲毫不受Netfilter-iptables的影響;即使報文經過了過濾規則的處理,它也會如同平時一樣重新回到報文處理流程上來,因此從宏觀上看,就像在行車過程中去了一趟加油站。
Netfilter不僅僅有此高效的設計,同時還具備很大的靈活性,這主要表現在Netfilter-iptables中的很多部分都是可擴充的,包括Table、Match、Target以及Connection Track Protocol Helper,下面一節將介紹這方面的內容。
回頁首
3. Netfilter-iptables Extensions
Netfilter提供的是一套HOOK框架,其優勢是就是易於擴充。可供擴充的Netfilter構件主要包括Table、Match、Target和Connection Track Protocol Helper四類,分別對應四套擴展函數。所有擴展都包括核內、核外兩個部分,核內部分置於<kernel-root>/net/ipv4/netfilter/下,模塊名為ipt_'name'.o;核外部分置於<iptables-root>/extensions/下,動態鏈接庫名為libipt_'name'.so。
3.1 Table
Table在以上章節中已經做過介紹了,它作為規則存儲的媒介,決定了該規則何時能起作用。系統提供的filter、nat、mangle涵蓋了所有的HOOK點,因此,大部分應用都可以圍繞這三個已存在的表進行,但也允許編程者定義自己的擁有特殊目的的表,這時需要參考已有表的struct ipt_table定義創建新的ipt_table數據結構,然後調用ipt_register_table()注冊該新表,並調用ipt_register_hook()將新表與Netfilter HOOK相關聯。
對表進行擴展的情形並不多見,因此這裡也不詳述。
3.2 Match & Target
Match和Target是Netfilter-iptables中最常使用的功能,靈活使用Match和Target,可以完成絕大多數報文處理功能。
3.2.1 Match數據結構
核心用struct ipt_match表征一個Match數據結構:
struct ipt_match
{
struct list_head list;
/* 通常初始化成{NULL,NULL},由核心使用 */
const char name[IPT_FUNCTION_MAXNAMELEN];
/* Match的名字,同時也要求包含該Match的模塊文件名為ipt_'name'.o */
int (*match)(const struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
const void *matchinfo,
int offset,
const void *hdr,
u_int16_t datalen,
int *hotdrop);
/* 返回非0表示匹配成功,如果返回0且hotdrop設為1,
則表示該報文應當立刻丟棄 */
int (*checkentry)(const char *tablename,
const struct ipt_ip *ip,
void *matchinfo,
unsigned int matchinfosize,
unsigned int hook_mask);
/* 在使用本Match的規則注入表中之前調用,進行有效性檢查,
/* 如果返回0,規則就不會加入iptables中 */
void (*destroy)(void *matchinfo, unsigned int matchinfosize);
/* 在包含本Match的規則從表中刪除時調用,
與checkentry配合可用於動態內存分配和釋放 */
struct module *me;
/* 表示當前Match是否為模塊(NULL為否) */
};定義好一個ipt_match結構後,可調用ipt_register_match()將本Match注冊到ipt_match鏈表中備用,在模塊方式下,該函數通常在init_module()中執行。
3.2.2 Match的用戶級設置
要使用核心定義的Match(包括已有的和自定義的),必須在用戶級的iptables程序中有所說明,iptables源代碼也提供了已知的核心Match,但未知的Match則需要自行添加說明。
在iptables中,一個Match用struct iptables_match表示:
struct iptables_match
{
struct iptables_match *next;
/* Match鏈,初始為NULL */
ipt_chainlabel name;
/* Match名,和核心模塊加載類似,作為動態鏈接庫存在的
Iptables Extension的命名規則為libipt_'name'.so(對於ipv6為libip6t_'name'.so),
以便於iptables主程序根據Match名加載相應的動態鏈接庫 */
const char *version;
/* 版本信息,一般設為NETFILTER_VERSION */
size_t size;
/* Match數據的大小,必須用IPT_ALIGN()宏指定對界 */
size_t userspacesize;
/*由於內核可能修改某些域,因此size可能與確切的用戶數據不同,
這時就應該把不會被改變的數據放在數據區的前面部分,
而這裡就應該填寫被改變的數據區大小;一般來說,這個值和size相同 */
void (*help)(void);
/* 當iptables要求顯示當前match的信息時(比如iptables -m ip_ext -h),
就會調用這個函數,輸出在iptables程序的通用信息之後 */
void (*init)(struct ipt_entry_match *m, unsigned int *nfcache);
/* 初始化,在parse之前調用 */
int (*parse)(int c, char **argv, int invert, unsigned int *flags,
const struct ipt_entry *entry,
unsigned int *nfcache,
struct ipt_entry_match **match);
/* 掃描並接收本match的命令行參數,正確接收時返回非0,flags用於保存狀態信息 */
void (*final_check)(unsigned int flags);
/* 當命令行參數全部處理完畢以後調用,如果不正確,應該退出(exit_error()) */
void (*print)(const struct ipt_ip *ip,
const struct ipt_entry_match *match, int numeric);
/* 當查詢當前表中的規則時,顯示使用了當前match的規則的額外的信息 */
void (*save)(const struct ipt_ip *ip,
const struct ipt_entry_match *match);
/* 按照parse允許的格式將本match的命令行參數輸出到標准輸出,
用於iptables-save命令 */
const struct option *extra_opts;
/* NULL結尾的參數列表,struct option與getopt(3)使用的結構相同 */
/* 以下參數由iptables內部使用,用戶不用關心 */
unsigned int option_offset;
struct ipt_entry_match *m;
unsigned int mflags;
unsigned int used;
}
struct option {
const char *name;
/* 參數名稱,用於匹配命令行輸入 */
int has_arg;
/* 本參數項是否允許帶參數,0表示沒有,1表示有,2表示可有可無 */
int *flag;
/* 指定返回的參數值內容,如果為NULL,則直接返回下面的val值,
否則返回0,val存於flag所指向的位置 */
int val;
/* 缺省的參數值 */
}如對於--opt <value>參數來講,在struct option中定義為{"opt",1,0,'1'},表示opt帶參數值,如果出現-opt <value>參數,則返回'1'用於parse()中的int c參數。
實際使用時,各個函數都可以為空,只要保證name項與核心的對應Match名字相同就可以了。在定義了iptables_match之後,可以調用register_match()讓iptables主體識別這個新Match。當iptables命令中第一次指定使用名為ip_ext的Match時,iptables主程序會自動加載libipt_ip_ext.so,並執行其中的_init()接口,所以register_match()操作應該放在_init()中執行。
3.2.3 Target數據結構
Target數據結構struct ipt_target和struct ipt_match基本相同,不同之處只是用target函數指針代替match函數指針:
struct ipt_target
{
……
unsigned int (*target)(struct sk_buff **pskb,
unsigned int hooknum,
const struct net_device *in,
const struct net_device *out,
const void *targinfo,
void *userdata);
/* 如果需要繼續處理則返回IPT_CONTINUE(-1),
否則返回NF_ACCEPT、NF_DROP等值,
它的調用者根據它的返回值來判斷如何處理它處理過的報文*/
……
}與ipt_register_match()對應,Target使用ipt_register_target()來進行注冊,但文件命名、使用方法等均與Match相同。
3.2.4 Target的用戶級設置
Target的用戶級設置使用struct iptables_target結構,與struct iptables_match完全相同。register_target()用於注冊新Target,方法也與Match相同。
3.3 Connection Track Protocol Helper
前面提到,NAT僅對一個連接(TCP或UDP)的第一個報文進行處理,之後就依靠Connection Track機制來完成對後續報文的處理。Connection Track是一套可以和NAT配合使用的機制,用於在傳輸層(甚至應用層)處理與更高層協議相關的動作。
關於Connection Track,Netfilter中的實現比較復雜,而且實際應用頻率不高,因此這裡就不展開了,以後專文介紹。
3.4 iptables patch機制
對於Netfilter-iptables擴展工作,用戶當然可以直接修改源代碼並編譯安裝,但為了標准化和簡便起見,在iptables源碼包提供了一套patch機制,希望用戶按照其格式要求進行擴展,而不必分別修改內核和iptables代碼。
和Netfilter-iptables的結構特點相適應,對iptables進行擴展也需要同時修改內核和iptables程序代碼,因此patch也分為兩個部分。在iptables-1.2.8中,核內補丁由patch-o-matic包提供,iptables-1.2.8的源碼中的extensions目錄則為iptables程序本身的補丁。
patch-o-matic提供了一個'runme'腳本來給核心打patch,按照它的規范,核內補丁應該包括五個部分,且命名有一定的規范,例如,如果Target名為ip_ext,那麼這五個部分的文件名和功能分別為:
ip_ext.patch
主文件,內容為diff格式的核心.c、.h源文件補丁,實際使用時類似給內核打patch(patch -p0 <ip_ext.patch);
ip_ext.patch.config.in
對<kernel-root>/net/ipv4/netfilter/Config.in文件的修改,第一行是原Config.in中的一行,以指示補丁添加的位置,後面則是添加在以上匹配行之後的內容。這個補丁的作用是使核心的配置界面中支持新增加的補丁選項;
ip_ext.patch.configure.help
對<kernel-root>/Documentation/Configure.help的修改,第一行為原Configure.help中的一行幫助索引,以下幾行的內容添加在這一行相關的幫助之後。這個補丁的作用是補充內核配置時對新增加的選項的說明;
ip_ext.patch.help
用於runme腳本顯示本patch的幫助信息;
ip_ext.patch.makefile
對<kernel-root>/net/ipv4/netfilter/Makefile的修改,和前兩個文件的格式相同,用於在指定的位置上添加用於生成ipt_ip_ext.o的make指令。
示例可以參看patch-o-matic下的源文件。
iptables本身的擴展稍微簡單一些,那就是在extensions目錄下增加一個libipt_ip_ext.c的文件,然後在本子目錄的Makefile的PF_EXT_SLIB宏中附加一個ip_ext字符串。
第一次安裝時,可以在iptables的根目錄下運行make pending-patches命令,此命令會自動調用runme腳本,將所有patch-o-matic下的patch文件打到內核中,之後需要重新配置和編譯內核。
如果只需要安裝所要求的patch,可以在patch-o-matic目錄下直接運行runme ip_ext,它會完成ip_ext patch的安裝。之後,仍然要重編內核以使patch生效。
iptables本身的make/make install過程可以編譯並安裝好libipt_ip_ext.so,之後,新的iptables命令就可以通過加載libipt_ip_ext.so來識別ip_ext target了。
Extensions還可以定義頭文件,一般這個頭文件核內核外都要用,因此,通常將其放置在<kernel-root>/include/linux/netfilter_ipv4/目錄下,在.c文件裡指定頭文件目錄為linux/netfilter_ipv4/。
靈活性是Netfilter-iptables機制的一大特色,因此,擴展Netfilter-iptables也是它的應用的關鍵。為了與此目標相適應,Netfilter-iptables在結構上便於擴展,同時也提供了一套擴展的方案,並有大量擴展樣例可供參考。
回頁首
4. 案例:用Netfilter實現VPN
虛擬專用網的關鍵就是隧道(Tunnel)技術,即將報文封裝起來通過公用網絡。利用Netfilter-iptables對報文的強大處理能力,完全可以以最小的開發成本實現一個高可配置的VPN。
本文第一部分即描述了IP Tunnel技術中報文的流動過程,從中可見,IP Tunnel技術的特殊之處有兩點:
一個特殊的網絡設備tunl0~tunlx--發送時,用指定路由的辦法將需要封裝的內網報文交給該網絡設備來處理,在"網卡驅動程序"中作封裝,然後再作為正常的IP報文交給真正的網絡設備發送出去;
一個特殊的IP層協議IPIP--從外網傳來的封裝報文擁有一個特殊的協議號(IPIP),報文最終在該協議的處理程序(ipip_rcv())中解封,恢復內網IP頭後,將報文注入IP協議棧底層(netif_rx())重新開始收包流程。
從中不難看出,在報文流出tunlx設備之後(即完成封裝之後)需要經過OUTPUT的Netfilter HOOK點,而在報文解封之前(ipip_rcv()得到報文之前),也要經過Netfilter的INPUT HOOK點,因此,完全有可能在這兩個HOOK上做文章,完成報文的封裝和解封過程。報文的接收過程可以直接沿用IPIP的處理方法,即自定義一個專門的協議,問題的關鍵即在於如何獲得需要封裝的外發報文,從而與正常的非VPN報文相區別。我們的做法是利用Netfilter-iptables對IP頭信息的敏感程度,在內網中使用標准的內網專用IP段(如192.168.xxx.xxx),從而通過IP地址將其區分開。基於IP地址的VPN配置既方便現有系統管理、又便於今後VPN系統升級後的擴充,而且可以結合Netfilter-iptables的防火牆設置,將VPN和防火牆有機地結合起來,共同維護一個安全的專用網絡。
在我們的方案中,VPN采用LAN-LAN方式(當然,Dial-in方式在技術上並沒有什麼區別),在LAN網關處設置我們的VPN管理組件,從而構成一個安全網關。LAN內部的節點既可以正常訪問防火牆限制以外非敏感的外網(如Internet的大部分站點),又可以通過安全網關的甄別,利用VPN訪問其他的專用網LAN。
由於本應用與原有的三個表在功能和所關心的HOOK點上有所不同,因此我們仿照filter表新建了一個vpn表,VPN功能分布在以下四個部分中:
iptables ENCRYPT Target:對於發往安全子網的報文,要求經過ENCRYPT target處理,加密原報文,產生認證碼,並將報文封裝在公網IPIP_EXT報文頭中。ENCRYPT Target配置在vpn表的OUTPUT和FORWARD HOOK點上,根據目的方IP地址來區分是否需要經過ENCRYPT target加密處理。
IPIP_EXT協議:在接收該協議報文的處理函數IPIP_EXT_rcv()中用安全子網的IP地址信息代替公網間傳輸的隧道報文頭中的IP地址,然後重新注入IP協議棧底層。
iptables IPIP_EXT Match:匹配報文頭的協議標識是否為自定義的IPIP_EXT。經過IPIP_EXT_rcv()處理之後的報文必須是IPIP_EXT協議類型的,否則應丟棄。
iptables DECRYPT Target:對於接收到的來自安全子網的報文,經過IPIP_EXT協議處理之後,將IP頭恢復為安全子網之間通信的IP頭,再進入DECRYPT target處理,對報文進行完全解密和解封。
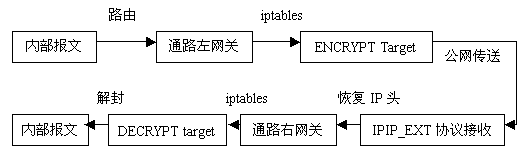
整個報文傳輸的流程可以用下圖表示:
圖8 VPN報文流動過程
對於外出報文(源於本地或內網),使用內部地址在FORWARD/OUTPUT點匹配成功,執行ENCRYPT,從Netfilter中返回後作為本地IPIP_EXT協議的報文繼續往外發送。
對於接收到的報文,如果協議號為IPPROTO_IPIP_EXT,則匹配IPIP_EXT的Match成功,否則將在INPUT點被丟棄;繼續傳送的報文從IP層傳給IPIP_EXT的協議處理代碼接收,在其中恢復內網IP的報文頭後調用netif_rx()重新流入協議棧。此時的報文將在INPUT/FORWARD點匹配規則,並執行DECRYPT,只有通過了DECRYPT的報文才能繼續傳送到本機的上層協議或者內網。
附:iptables設置指令(樣例):
iptables -t vpn -P FORWARD DROP
iptables -t vpn -A OUTPUT -d 192.168.0.0/24 -j ENCRYPT
iptables -t vpn -A INPUT -s 192.168.0.0/24 -m ipip_ah -j DECRYPT
iptables -t vpn -A FORWARD -s 192.168.0.0/24 -d 192.168.1.0 -j DECRYPT
iptables -t vpn -A FORWARD -s 192.168.1.0/24 -d 192.168.0.0/24 -j ENCRYPT
其中192.168.0.0/24是目的子網,192.168.1.0/24是本地子網
參考資料
[Linus Torvalds,2003] Linux內核源碼v2.4.21
[Paul Russell,2002] Linux netfilter Hacking HOWTO v1.2
[Paul Russell,2002] iptables源碼v1.2.1a
[Paul Russell,2000] LinuxWorld: San Jose August 2000,Netfilter Tutorial
[Oskar Andreasson,2001] iptables Tutorial 1.0.9


