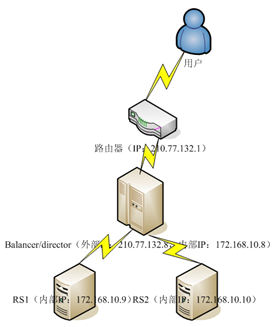
監控是集群管理的核心任務。監控數據可用於調度任務、負載平衡、向管理員報告軟硬件故障,並廣泛地控制系統使用情況。監控信息必須在不影響集群性能的情況下獲得。本文將討論使用/proc文件系統和Java來獲得監控數據的方法。
Java在Linux集群中的應用
Java技術為集群管理開發者提供了許多解決問題的辦法。Java是動態、靈活、可移植的,這些不尋常的特征使得它成為了在異構網絡及平台上構造集群管理的理想基礎。
Java具有廣泛的例程庫,很容易處理IP協議,如TCP、UDP,並可在multi-homed主機上進行網絡程序設計,用它創建網絡連接比用C或C++更容易。通過Java本地接口(JNI),運行在Java 虛擬機(JVM)內的Java代碼能夠與用其它語言編寫的應用及庫文件相互操作並匯編。
在構造集群監控和管理時,Java早已是一個可選的語言。然而,Java語言通常只被用於系統的前端或集群主機部分,而將用C 語言編寫的守護進程安裝在集群結點上。盡管Java程序設計語言提供了許多優點,但是,對於高性能集群監控,Java能夠有效地替換運行在每個結點上的C 語言守護進程嗎?這將是本文討論的重點。
高性能監控
監控Linux集群工具傳統上以秒為測量頻率來提供有限量的數據。而高性能集群監控被定義為“以intrasecond為測量頻率,從結點有效地采集數據的能力”。當涉及較大集群時,監控軟件的低效率問題就變得更加嚴重,這是因為所運行的應用軟件必須互相協調或共享全局資源。
在一個結點上的阻隔沖突(Interference)能影響其它結點上作業的運行。例如,一個MPI作用需要與所有參與的結點同步。一種解決辦法是收集少量的數據,並以小頻率傳輸。然而,如果是高性能監控,這種解決辦法是不可接受的,因為有較重利用率的集群應該被頻繁持續地監控。本地作業調度器必須能夠基於資源使用情況做快速決策。管理員經常希望收到緊急事件的立即通知,並希望觀察到歷史趨勢數據,如果集群不能被頻繁持續地監控,那麼這些要求是不可能實現的。因此,必須采取一些措施,如使用更有效的算法、增加傳輸的並行性、提高傳輸協議及數據格式的效率、減少冗余等。
在跟蹤運行中的資源使用情況時,壓縮Profiling應用有助於調試程序或優化程序。對一個給定的應用而言,像存儲器、網絡、CPU這樣動態資源的使用可能快速地改變著,為了能夠觀察應用是怎樣使用這些資源的,一種可能的辦法是使用高頻率的監控。
即使用戶對高頻率監控沒有興趣,如果算法是有效的,不管監控頻率是多少,它也將消費很少的資源。在異構集群中這種效率將更重要,用戶的作業可以被分散到較快的及較慢的結點上,慢的結點需要全部CPU來跟上較快的結點並與之同步。一個監控程序花費在較慢結點上的CPU時間是作業的關鍵路徑。
監控階段
集群監控主要消耗CPU周期與網絡帶寬這兩個重要資源。然而,資源消費問題與這兩個資源是根本不同的。CPU利用問題對結點而言是完全本地化的問題,可通過創建有效的收集與合並算法來解決。網絡帶寬是共享資源,是規模問題,可以通過最小化網絡上傳輸的數據量來解決。
為了解決這兩個問題,我們將集群監控分為三個階段:收集、合並、傳輸。收集階段負責從操作系統裝載數據、分析數據值,並存儲數據。合並階段負責將來自多個數據源的數據合在一起,決定數據值是否改變並過濾它們。傳輸階段負責壓縮並傳輸數據。本文集中討論Linux集群監控的收集階段。
1.收集階段 Linux有幾種方法來進行系統統計,每種方法都各有其優缺點。 ◆ 使用現有的工具 標准及非標准工具能執行一個或多個收集、合並及傳輸階段,如rstatd或SNMP工具,然而標准的rstat後台程序提供的信息是有限的,速度慢而且效率低。 ◆ 內核模塊 幾個系統監控工程利用內核模塊來存取監控數據。一般情況下,這是很有效的收集系統數據的方法。然而這種方法存在的問題是,當主內核源內有其它改變時,必須保持代碼一致性。一個內核模塊可能與用戶想使用的其它內核模塊相沖突。此外,在使用監控系統之前,用戶必須獲得或申請模塊。 ◆ /proc虛擬文件系統 /proc 虛擬文件系統是一個較快的、高效率執行系統監控的方法。使用/proc的主要缺點是必須保持代碼分析與/proc 文件格式改變的同步。事實表明,Linux內核的改變比/proc 文件格式的改變要更頻繁,所以,用/proc虛擬文件系統比用內核模塊存在的問題要少。 ◆ 混合系統 某些監控系統采用混合方式,用內核模塊收集數據,用/proc虛擬文件系統作為數據接口。
2.合並階段 合並階段的實現可以在結點上、集群管理的主機上,或者分布在兩者上。考慮到效率,我們只采用在結點上的合並。原因在於結點是監控數據的收集器與提供者。兩個或多個同時的數據請求不會引起兩次操作系統調用來收集數據,而是將第一次請求獲得的數據緩存,並可以提供給第二次請求調用。這種方法減少了操作系統的負擔,提高了監控系統的響應性。合並階段也可以用於將多個數據源的數據以相互獨立的收集速率結合,因為並不是所有的數據都以同樣的速度改變,或者需要以同樣的速率收集。
使用在結點層上合並的另一個原因是,減少了包括傳輸在內的信息量。許多/proc文件既包含動態數據也包含靜態數據。刪除最近一次傳輸後沒有改變的值,一個結點發送的數據量可以大大地減少。合並不僅除去了不經常改變的動態值的傳輸,也解決了從不改變的靜態值的傳輸。
3.傳輸階段 監控數據幾乎總是按一個層次結構組織起來。傳輸階段的任務就是將層次數據進行有效的編碼,形成一種能高效傳輸的數據格式。Java擁有的文件格式是存儲層次數據的有效方法,並且用提供的Java APIs很容易完成。S-EXPressions已經被認為是傳輸這種數據的另一個有效的方法。
關於傳輸監控數據普遍討論的問題是,數據應該按二進制編碼還是按文本格式編碼。二進制數據更容易壓縮,因此也能更有效地傳輸。但是,當采用/proc文件系統時,監控數據通常以人們易讀的格式存儲。在傳輸之前,將數據轉換為二進制格式將需要更多的處理資源與時間。以文本格式保留收集的數據,結點資源能被用於更多非監控性的相關工作。
采用文本格式的數據將提供如下額外的益處: ◆ 平台獨立性 當監控異構集群時,機器之間數據字節指令的配置不是永遠相同的。文本格式的使用在代碼方面解決了這個問題,而且體系結構獨立不會影響更多的處理需求。 ◆ 易讀的格式 文本數據能以人們易讀的格式進行組織。如果需要的話,這種特征能容易地進行程序調試或允許用戶觀看數據流。 ◆ 有效壓縮 數值數據的文本表示由來自10個字節集中的字符組成,而不是二進制下的256個字節集。它們產生的數字及模式的相對頻率允許有效地使用基於壓縮算法的字典及熵(平均信息量)。
/proc虛擬文件系統
/proc虛擬文件系統(也叫procfs)是Unix操作系統所使用的虛擬文件系統的Linux實現,包括Sun Solaris、LinuxBSD。在/proc開始時,它以一個標准文件系統出現,並包含與正在運行的進程IDs同樣名字的文件。然而,在/proc中的文件不占用磁盤空間,它們存在於工作存儲器(內存)中。/proc最初的目的是便於進程信息的存取,但是現在,在Linux中,它可被內核的每一部分使用來報告某些事情。
在/proc文件系統提供的成百上千的值當中,我們將集中考慮集群監控所需的最小集,它們包括: ◆ /proc/loadavg:包含系統負載平均值; ◆ /proc/meminfo:包含存儲管理統計量; ◆ /proc/net/dev:包含網卡度量; ◆ /proc/stat:包含內核統計量; ◆ /proc/uptime:包含總的系統正常工作時間及空閒時間。
每個文件提供的值的數量是不同的。這些文件的完整有效值列表如下。 ◆ /proc/loadavg提供以下數據:
1秒鐘平均負載; 5秒鐘平均負載; 15秒鐘平均負載; 總作業數; 正在運行的作業總數。
◆ /proc/meminfo提供的存儲器信息包括:
活動存儲器; 不活動存儲器; 緩沖存儲器; 高速緩沖存儲器; 總的自由存儲器; 總的高位存儲器; 自由高位存儲器; 總的低位存儲器; 自由低位存儲器; 共享存儲器; 交換存儲器; 交換高速緩沖存儲器; 交換自由存儲器; 總存儲器。
◆ /proc/net/dev中包括每個網卡的如下數據:
接收到的字節; 接收到的壓縮字節; 收到的誤碼數; 收到的漏失誤碼; 收到的FIFO誤碼; 收到的幀誤碼; 收到的多播誤碼; 收到的總包數; 已傳輸的字節; 已傳輸的壓縮字節; 傳輸誤碼總數; 傳輸載波誤碼; 傳輸沖突誤碼; 傳輸漏失誤碼; 傳輸FIFO誤碼; 傳輸的總包數。
◆ /proc/stat提供:
引導時間; 上下文切換數量; 中斷總量; 進頁面總數; 出頁面總數; 進程總數; 換入總數; 換出總數; 合計CPU空閒時間; 合計CPU nice時間; 合計CPU系統時間; 合計CPU用戶時間。 同時提供對每個CPU的: 單個CPU空閒時間; 單個CPU nice時間; 單個CPU系統時間; 單個CPU用戶時間。 以及對每個磁盤驅動器的如下數據: 單個磁盤塊讀; 單個磁盤塊寫; 單個磁盤I/O總數; 單個磁盤I/O讀; 單個磁盤I/O寫。
◆ /proc/uptime中包括:
系統總工作時間; 系統總空閒時間。
值得注意的是,每次某個/proc被讀時,一個句柄函數都被內核或特有模塊調用,來產生數據。數據在運行中產生,不管是讀一個字符還是一個大的字塊,整個文件都將被重建。這對效率是至關重要的一點,因為使用/proc的任何系統監控器將吞下整個文件,而不是一點一點地處理它。
Java提供了豐富的文件I/O類集,包括基於類的流、基於類的塊設備,以及J2SDK 1.4提供的新的I/O庫。實驗表明,一般而言,對基本的塊讀寫文件操作,用RandomAccessFile類進行I/O是最佳的。例如,塊讀文件操作如下:
mFile = new RandomAccessFile( "/proc/meminfo", "r" ); //以讀方式打開文件 mFile.read( mBuffer ); //讀文件塊
結論
本文討論了如何將Java語言有效地用於Linux集群結點上的高性能監控。在程序設計中,要注意以下方面: ◆ 采用/proc文件系統; ◆ 以塊形式讀/proc文件,而不是以行或字符形式; ◆ 在讀文件期間保持文件打開; ◆ 消除不必要的數據轉換; ◆ 在結點上合並數據; ◆ 以壓縮形式傳輸數據; ◆ 注意與性能問題相關的語言或庫。
對高性能監控而言,內核模塊不是必要條件,這點很重要,因為它在Linux版本和分類之間提供了很大程度的可移植性,在監控器實現語言上有很多的選擇。但是,/proc文件系統的性能卻很依賴內核代碼的效率,因此,適當地理解有關的機制將對以任何語言編寫的監控器性能有非常大的影響。
結論
本文討論了如何將Java語言有效地用於Linux集群結點上的高性能監控。在程序設計中,要注意以下方面: ◆ 采用/proc文件系統; ◆ 以塊形式讀/proc文件,而不是以行或字符形式; ◆ 在讀文件期間保持文件打開; ◆ 消除不必要的數據轉換; ◆ 在結點上合並數據; ◆ 以壓縮形式傳輸數據; ◆ 注意與性能問題相關的語言或庫。
對高性能監控而言,內核模塊不是必要條件,這點很重要,因為它在Linux版本和分類之間提供了很大程度的可移植性,在監控器實現語言上有很多的選擇。但是,/proc文件系統的性能卻很依賴內核代碼的效率,因此,適當地理解有關的機制將對以任何語言編寫的監控器性能有非常大的影響。