TCP擁塞控制算法縱橫談-Illinois和YeAH。
方法論問題。
這個題目太大以至於內容和題目的關聯看起來有失偏頗,不過也無所謂,既然被人以為“沒有方法論”而鄙視了,這裡也就拋出一些偽方法論,總之,就是一些大而空的東西。我並不是說方法論沒有用,而是說方法論太有用了,以至於絕不能誤解它。難道方法論不是從已經成功的經驗中總結出來的嗎?如果還沒有成功的案例,那麼方法論從何而生呢?
So,我只能從現成的東西入手了...分類學是一個貫通古今的學科,也蘊含在實在太多的方法論中,從中我們可以得出二元論,多元論等等,比如人不是神,神不是人,耶稣既是神,也是人等等,但是總是有另外的聲音,這個聲音一直抵制著分類,說分類只是方便了人們的後天學習,卻阻礙了前瞻。我是贊同的,其實,我也非常抵制分類,我不喜歡把靈活的東西放入人為構建的框架之中。其實消除了分類,我們可以免去很多災難,比方說你我都能理解的那些宗教戰爭,民族自決,仇富導致的犯罪,貪欲帶來的侵犯...同時,消除分類之後,自然科學也會被促進,甚至融合社會學科,比方說量子力學,博弈論,混沌學...如今,跨界正是另一個視角的反分類學案例,事實證明,跨界帶來的成功案例非常多,正是因為跨界讓事情變得簡單了。So,對於TCP而言,也是一樣。
之前的一篇文章《 QVegas-一個升級版的TCP Vegas擁塞算法》中,我給出了QVegas這個非常簡陋但足以表達核心思想的一個TCP擁塞控制算法,本文中,我通過幾個現成的算法來表達相同的思想。
其實這些算法根本就不是什麼新奇的東西,如果不是囿於成見,對待設計擁塞控制算法問題上,每個人的思路幾乎都是一樣的。正是那些成型的模式,那些教科書被奉為金科玉律,才讓我們習慣於將算法分為什麼“基於丟包的”,“基於時延的”,“混合的”...如果你要設計一個東西而不是僅僅學會一樣東西,那麼千萬注意,要避開分類!
為什麼要避開分類,因為但凡分類都會在類別之間樹立屏障,正是這些屏障讓一個算法分屬了不同的類別,這十分突出地表現在民族和政治問題上,阿爾薩斯,洛林,蘇台德區,捷克,希臘,斯拉夫...這都是血的教訓。結論是什麼,結論就是沒有任何屏障可以正確的將事物分類。
正確的做法便是拋棄一切的類別,從本源入手。
正確的做法要麼是自己識別擁塞跡象並懸崖勒馬般地退讓,靠自覺收斂,要麼就是依靠控制論裡的收斂法則來被動收斂,也就是靠懲罰來收斂。無他。但考慮到自覺收斂這件事確實是看人品的,所以為了保證TCP的絕對收斂,懲罰是必須的,是無條件的。怎麼個懲罰法則呢?很簡單,MD(乘性減窗)法則。請注意,Linux直到4.8內核都沒有開放可以逃避懲罰的接口。
是Google在4.9內核引入BBR的時候才破壞了游戲規則!
什麼是AIMD以及Reno/NewReno/BIC/CUBIC
說實話,我並不覺得AIMD是一個設計良好的擁塞控制算法之全部,它甚至沒有經過設計,它只是經過數學精心確認的一個收斂法則,屬於控制論范疇,恰好TCP的首要原則是收斂,那麼“采用AIMD策略就是可行的”,並且在後面的日子裡,事實證明它工作的還算良好,就一直延續了下去。因此,照這個觀點,Reno,NewReno,BIC,CUBIC根本就是非常簡陋的“算法”。它們能保證的只是收斂,而根本就和擁塞控制無關,它們並不識別擁塞,也無力識別擁塞,所以也就根本控制不了擁塞。AIMD的核心公式如下:
cwnd = cwnd + alpha (per RTT)
cwnd = beta*cwnd (at lost)
可見,如何控制alpha,beta的取值是關鍵,正是控制手段的不同,造就了各種算法。有的算法alpha,beta取定值或者固定曲線參數,這就是所謂的“基於丟包的算法”,另外一些則是在計算alpha,beta的時候,引入了更多的信息,比如RTT,這就是“基於時延的算法”,目前更多的則是二者的混合,更讓分類學者摸不著頭腦。
基於AIMD的TCP收斂算法被視為經典的“TCP擁塞控制算法”,幾乎成了一切TCP擁塞控制算法的根基,這也是事實。但是再次重申,以我的觀點來看,簡單的AIMD算法並不能控制擁塞,它只是基本原則。
起初,最簡單的Reno是一切算法的基礎,後來逐步發展進化促成了NewReno,BIC,CUBIC這些變種。但無論哪一個具體的此類算法,都對擁塞沒有任何概念,我之前說過,也正是這個發展進化的過程,在一定程度上促進了路由器的緩存越來越大,形成了網絡界封閉的安迪-比爾定律。但這又說明什麼呢?難道應該把這些算法全部拋棄嗎?
不可能拋棄!但這並不是全部。我們需要AIMD的原因是為了收斂,為了全局的公平性AIMD應該包含在所有的擁塞控制算法中,現在的問題是,如果想形成一個完整的擁塞控制算法,AIMD之外我們還需要加入些什麼呢?
TCP-Illinois的注解
我先展示一個“經過優化”的AIMD算法,即TCP Illinois算法。
盜用Illinois的一個圖,來自其Wiki頁面:https://en.wikipedia.org/wiki/TCP-Illinois
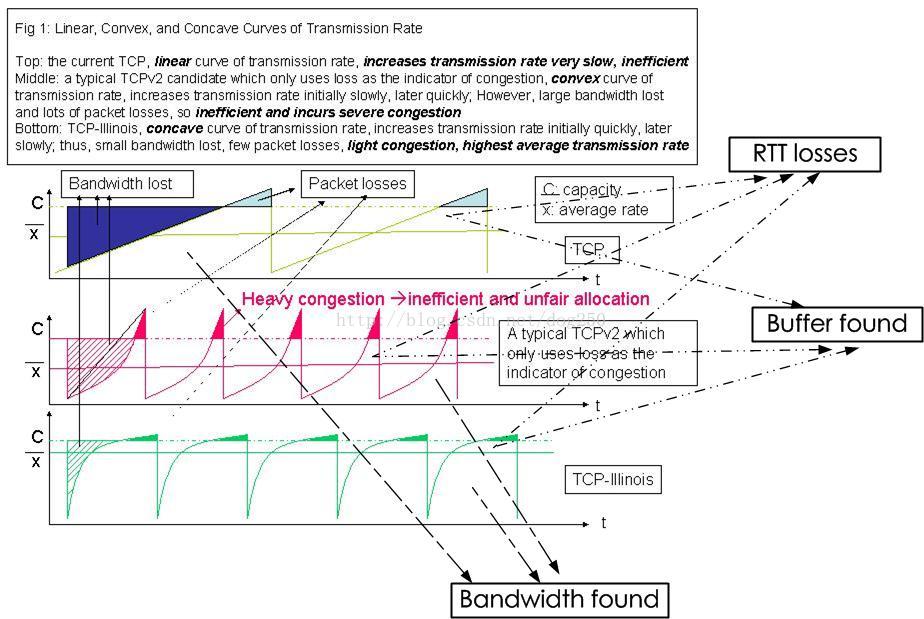
在窗口-時間圖中,坐標系圍成的象限被分成了幾個區域,分別為Bandwidth lost區域,Packet lost區域,其實還有兩個found區域,我已經在圖中添加了。我們仔細觀察這個圖,很明顯的事實是,要想讓帶寬的利用率更高,就需要想辦法擴大found區域而縮小lost區域。另外,我添加了RTT lost區域,表示雖然未丟包,但已經開始排隊了。
按照這個思路,我們可以看到從上到下的三個圖之進化過程。首先,我們可以把第一個圖看成是標准的Reno,這一點沒有異議,中間的那個圖呢,可以看作的畸形版的CUBIC,也還合理,那麼下面的那個圖誰都可以看出是明顯優於上面兩個圖的,它叫什麼?它就是Illinois。
Illinois是怎麼做到的呢?
其實很簡單,Illinois在AIMD之外考慮了擁塞。所以它成了一個完整的擁塞控制算法,感知了擁塞,並主動回避了擁塞。仔細觀察Illinois的窗口-時間曲線,你會發現曲線的斜率在逐漸減小,最終在突破可用BDP的時候越發趨於平緩,這樣做的效益是什麼?說白了就是Illinois通過RTT的變化主動探測了擁塞的發生,當擁塞尚未發生的時候,窗口增長得快些,而在探測到擁塞將要發生或者已經發生的時候,窗口增長得慢些。
從窗口-時間圖上來看,在可用BDP之下,窗口曲線的凹增長向左擠壓了Bandwidth lost的區域,在突破可用BDP之後,窗口曲線的凹增長向下壓縮了Packet lost區域,就好像Illinois知道可用BDP這個位置似的。注意,Illinois和CUBIC完全不同,CUBIC並不控制擁塞,只為收斂,所以它的窗口曲線會呈現對稱的凸凹曲線,CUBIC的曲線在效率明顯低於Illinois,因為它的下半段是凹增長的,和Illinois類似,它擠壓了Bandwidth lost區域,然而它的上半段是凸的,相當於放大了Packet lost區域,這麼做也是無奈之舉,由於CUBIC並不感知擁塞,為了公平收斂,其對稱的三次凸凹曲線是唯一合理的選擇。事實證明,CUBIC的收斂性非常好,雖然它的帶寬利用率比較低。
再回到Illinois,我們發現,即使是Illinois也沒有想辦法減少RTT lost區域,這也無可厚非,畢竟它並不准備主動退避,它依靠的還是被動的懲罰,即MD的過程。So,既然Illinois不會減少RTT lost區域,那麼它也是諸多實時連接的噩夢!好在它也有保證公平性。值得注意的是,Buffer found意味著RTT lost!
既然知道了Illinois的窗口曲線走向的細節,下一個問題就是,Illinois是如何做到的?
也不難,它通過采集RTT的變化情況,不斷地調整Reno曲線的斜率,造就成了一條動態的不斷下凹的曲線(這點是與CUBIC截然不同的,CUBIC僅僅根據AIMD原則來上凸下凹,而Illinois則是通過實際采集的RTT來指導曲線的斜率走向)。
不管怎樣,Illinois和CUBIC的基本原則都是AIMD,只是依托的手段不同,對於Illinois而言,其alpha,beta是動態調整的,調整的具體公式就不復制粘貼了,請看:https://en.wikipedia.org/wiki/TCP-Illinois,至於說為什麼這樣,請更進一步:http://tamerbasar.csl.illinois.edu/LiuBasarSrikantPerfEvalArtJun2008.pdf。
TCP-YeAH注解
和我的QVegas以及微軟的Compount算法類似,Yeah采用幾乎完全相同的思路,相比之下,Yeah和QVegas非常像,所以我說Yeah是QVegas的完善版,而QVegas則是一個小兒科,其MD過程對公平性的影響根本沒有經過數學論證,我也沒那個能力和時間以及精力,所以它只是看上去不錯而已。那麼看一下和QVegas思路一致的算法應該是什麼樣子吧!它就是Yeah。
首先看一下內核的help:
YeAH-TCP is a sender-side high-speed enabled TCP congestion control
algorithm, which uses a mixed loss/delay approach to compute the
congestion window. It's design goals target high efficiency,
internal, RTT and Reno fairness, resilience to link loss while
keeping network elements load as low as possible.
很明顯,它是一個mixed算法。更進一步,Yeah表達了以下的願望:
1.在未檢測到擁塞的時候,窗口快速增長;
2.在檢測到擁塞將要發生或者已經發生的時候,窗口慢速增長;
3.在檢測到擁塞將要發生或者已經發生的時候,排掉自己排隊的數據包。
注意,上述的2和3顯得有點矛盾,其實一點都不矛盾,我的QVegas也是這麼做的,其實在將窗口分離成了“基於丟包的分量”和“基於時延的分量”這兩個分量之後,2和3確實是兩碼事,上述2中窗口的增量針對“基於丟包分量”,而2中的窗口增量則針對“基於時延分量”。
現在,我來展示一下TCP Yeah算法的簡要流程,標准的流程請參考yeah Paper《YeAH-TCP: Yet Another Highspeed TCP》,不標准的實現請參考Linux源碼,tcp_yeah.c,我給出的是基於Linux實現的算法:
首先需要定義變量:
Let reno(慢速增窗的大小), fast(快速增窗的大小),slow_cnt(連續處在排隊【擁塞】狀態的次數)
Let cwnd(當前窗口大小),queue(當前隊列的大小)
先來看一下AI的過程:
if slow_cnt > 0
slow AI
else
fast AI
if (未到一個非Delay RTT)
return
queue = cwnd*(RTT_now - RTT_min)/RTT_now
if (queue is very long) or (RTT_now is very long)
if (queue is very long) && (cwnd > reno)
reduction = queue/parameter_A
cwnd = cwnd - reduction
reno++
slow_cnt = 0
else
fast++
slow_cnt++
if fast > parameter_B
fast = 0
reno = 2
以上就是AI過程。根據AIMD原則,只要發現擁塞就要執行MD,問題是如何發現擁塞!Yeah算法中,MD並非僅僅在“發現丟包”的時候執行,而是平鋪到整個過程中,只要發現有擁塞跡象,就馬上降窗。問題的關鍵是,MD一定要比AI猛,這就是罪與罰的原則,如果不懂,建議看看小說《罪與罰》。
另外值得注意的是,注意到AI過程中reno,fast計數器的增加過程,其實reno這個計數器表示的就是reno窗口分量的大小,因為在標准的Reno AIMD中,每一個RTT窗口就會增加1,而Yeah的Update動作也是按照RTT驅動的,即每一個RTT完成一次Update。
再來看一下MD的過程:
if slow_cnt < parameter_C
reduction = queue
else
reduction = normal MD
ssthresh = cwnd - reduction
針對於Linux的實現,這個MD過程是“萬不得已”的時候才執行的,只要是丟包,哪怕是由於線路噪聲造成的丟包,也會執行,這是Linux擁塞控制的框架所決定的,罪與罰,誰也逃不離。問題是,怎麼罰。Yeah的答案很簡單,如果不是過度擁塞造成的丟包,就減窗少一點,否則就按照標准Reno執行折半減窗。當然在實現細節上,還可以有更多的靈活空間。
...
是不是跟QVegas很像呢?其實啊,正確的方法並不多,只要懂原理,大家最終踏上的都是同一條路,所以說我不得不鄙視一下那些只破不立的家伙了。
TCP協議的學習
TCP協議分為兩個層面,一個是協議的本身語義,這個非常簡單,一般經歷幾場面試你就都懂了,無外乎協議頭的格式,三次握手的過程,socket API等等這些,我現在還記得2010年面試的那段時間,最後一家公司的筆試題目有一道簡述三次握手過程的題目,我字寫的不好,所以就寫了兩個字,口述,而這家公司最終錄用了我,我在那裡干了5年半...我並不知道是不是由於我精通TCP的三次握手而加了分,但至少如果我不懂這個三次握手的過程,我肯定會被拒絕。
那麼,怎麼樣證明你已經精通了TCP的協議頭格式或者握手揮手的過程,答案很簡單,那就是寫下來或者說出來,錯與對聽聞間便知。
TCP的另外一個層面就沒有這麼好考核了。那就是TCP的擁塞控制算法方面。為什麼我這麼說呢?
因為TCP擁塞控制算法它“太簡單了”,毫無量化的確定的東西,如果一個人來面試,他可以隨便怎麼說都行,只要不犯原則性錯誤,比如說成MIAD,一般都能侃侃而談好幾個小時。所有人都能理解的是網絡是大家共享的,難免會擁塞,然後圍繞這個話題五花八門的點子就蹦出來了,任何人都不能說這些點子完全正確,卻也不能否定它們...我趁著周末的空閒時間,我給我老婆講半個小時的擁塞控制原理,我相信她馬上就能“上手”提出各種“算法”,如果說我老婆學歷過高更有文化乃至悟性好的話,我換成我丈母娘或者我媽,我打賭結果完全一樣,當然,我並非在否定老年人的智商,我只是說,老年人難免思考能力會退化,精力會不足等等,但也能聰明到理解擁塞控制算法。
那難道TCP擁塞控制算法是一個如此簡單的東西嗎?不!相反,它是非常難的。
能讓一個人侃侃而談好幾個小時不喘氣的最著名的例子是什麼?是演講或者傳銷課,要麼就是布道。能讓一群人在一起折騰好幾個小時不喘氣的典型例子是什麼?是議會討論,是選舉,是打官司...總之,這些都不是自然科學。TCP的擁塞控制實際上就不是自然科學,而是社會科學。你把一個好的算法交給交管局,讓它治理交通同樣合適,同時,讓一個交警來寫擁塞控制算法,那應該可是秒殺格子間的程序員的。所以說它本身就是一個跨學科的范疇,並不僅僅屬於程序員。和直覺有點不一致的是,程序員在擁塞控制領域反而處於劣勢,因為他們根本就沒有機會,時間,精力來探知TCP/IP網絡或者交通網絡中到底發生了什麼以及如何發生的,即便了解到這些,背後那些超級復雜的數學理論也是程序員完全無力企及的,相反,那些運籌學,博弈論,統計學領域內的專家,可能更加適合這個領域。
最近在看《大秦帝國》,裡面的一個故事所有人都知道,在趙括面對白起之前,他可是響當當的專家,然而怎麼就敗了呢?這其中端倪我想不是秦國挑撥離間這麼簡單。兩軍打仗跟打架一樣,總要至少有一個失敗者,這是必然的,如果趙括真的只會紙上談兵,難道趙國人就是傻逼看不出來嗎?其實,我覺得非常簡單,就算換成廉頗,說不定也得輸,並不是說如果趙國不用趙括的話好像就能贏似的。為什麼會輸,原因就是因為事實上他輸了。打仗之前,要是誰能確定輸贏,那就不用打了,直接簽條約就好了!同樣的,甲午戰爭,輿論一邊倒地傾向於清朝秒殺日本,可是結果呢?
趙括並非弱者,也不是只會紙上談兵,事實上所有的將軍都一樣,他只是綜合國力的代表罷了,在結局勝負之前,大家都是紙上談兵,這一點跟TCP擁塞控制領域是完全一樣的。


