


TCP在發現丟包的時候,會采取一定的措施,至於如何發現丟包不是本文的內容,本文主要描述發現丟包以後TCP采取什麼措施。
以Linux為例,降窗發生在進入快速恢復的當時(暫時不考慮RTO以及本地擁塞),在降窗之前是一個Disorder的狀態,指的是系統發現了異常,比如收到了重復ACK或者說收到一個推進的ACK攜帶了SACK信息,然而還不至於到重傳的地步,比如還沒有達到亂序度的門限值,在門限值之下,系統會假設這只是一次亂序,馬上就會好的,在Disorder狀態,TCP的擁塞窗口是僵住的,即既不增加也不減少,此時會有兩種結果,一個是在亂序度被超越前系統恢復了正常,那麼將會進入擁塞避免狀態,窗口執行AI,另一方面如果亂序度被超越,那麼就會進入快速恢復狀態,窗口執行MD,在這個狀態中,擁塞窗口會持續降低,下面的篇幅就是來描述這個降窗過程的。
TCP會進入一個叫做“快速恢復”的狀態,恢復什麼呢?恢復到正常狀態!在快速恢復中,主要要做的任務就是重傳“被認為”是丟失的數據包。“被認為”之所以要加上引號是因為一切都是猜測!在這個過程中,TCP會認為網絡發生了擁塞,既然發生了擁塞,再發多少數據包也沒有用。TCP被設計為一個君子協議,那就是自己發現丟包的時候,自己會主動降低窗口,大家都這麼做,以期望網絡迅速恢復正常,這也就是為什麼像華夏創新的那種算法永遠都進不了標准,永遠都寫不成paper的原因吧。
現在的問題是,如何進行窗口的降低。
就目前看來,主要有4中方式降低窗口:
1.BSD原始方式:這也是《TCP/IP詳解》(不是第二版啊)中描述的方式,像心電圖一樣,在降窗之前會有一個毛刺。目前早就已經棄用,想看究竟的話請看steven的書。
2.RFC3517方式:這是典型的NewReno方式,RFC3517中有詳細的描述,比較短也不復雜,10分鐘就能看完,就像看歷史書一樣,理解其基本思想即可,來龍去脈,引啟未來。
3.Linux rate halving方式:這是一種非標准的方式,但卻是一種創新的方式,它“承若”不再陡降窗口,它將窗口緩慢降到原來的一半,然後在進入正常狀態後再緩慢上升。
4.Linux PRR方式:基於rate halving,它不僅僅只是“承若”,而是保證!並且更加靈活了,降窗由ACK來驅動,具體降窗到哪裡,取決於ssthresh,而後者是由具體的擁塞算法決定的。
以上就是典型的4中方式,教科書上的學院派方式基本都是1和2,這也是為什麼隨便問一個學生,他們都能答出1或2一樣,而且1和2之間還會有沒有休止符的爭論。3和4屬於內核社區,即便懂Linux內核的家伙們也沒幾個知道其細節,問起他們細節,他們大多數人的回答還是1或2...這倒也說明不了什麼,只是說有些非標准實現不拘一格罷了。啟自這種不拘一格,我自己也有一種天真的想法,那就是讓快速恢復階段的窗口走一個弧形,開始於原始窗口,結束於當前帶寬允許的窗口。這也就是傳說中的5。
本文就不再細說1和2了,畢竟我不是偉大的人民教師,也是個編程人員,沒有那麼多時間闡釋大家都懂的東西,然而我擅長闡述大多數人不懂的東西。掠過1和2之前,說一下它們的缺點:
1).half silence
2).burst failed
千萬不要覺得突發是優點或者缺點,如果將它們作為優點,那麼當發出大量包時,會造成或加重網絡擁塞,當沒有這種突發時,又會造成保守的傳輸!不管怎樣,這不是眾口難調,而是算法本身的固有缺陷!
在除了1和2之外,我們來一個一個說吧。
Linux rate halving算法
Linux的TCP協議的實現中,采用了一種非標准化的降窗算法,即rate halving算法,顧名思義,它旨在將窗口降低到原有窗口的一半!目標和RFC3517是完全一致的,區別在於執行的過程。
Linux rate halving算法對待擁塞窗口的方式是執行一個緩慢下降的過程,而不像RFC3517那樣一下子陡降到一半,然後在整個快速恢復過程中執行窗口線性緩慢上升的過程。恰恰相反,Linux rate halving算法是一個相反的過程,它一開始並不陡降窗口,在快速恢復的最後,它的目標是將窗口緩慢降到原來的一半,進入正常狀態後,才從原有窗口的一半開始執行擁塞避免,線性緩慢增加窗口。
然而,實際情況往往不想願景所希望的那樣,我們會慢慢地理清頭緒。首先,Linux rate halving的算法如下:
初始狀態:
CWND=進入快速恢復前的擁塞窗口大小
dec=0
在恢復正常前,對於每一個ACK,執行cwnd_down:
cwnd_down()
{
dec = dec + 1;
dec = decr&1;
CWND = CWND - dec;
CWND = min(CWND, in_flight+1);
}
為了幫助理解,下面首先給出一個常規理想化的實例,演示算法的執行過程,然後給出一個稍微變態點的例子,演示這個算法的問題:
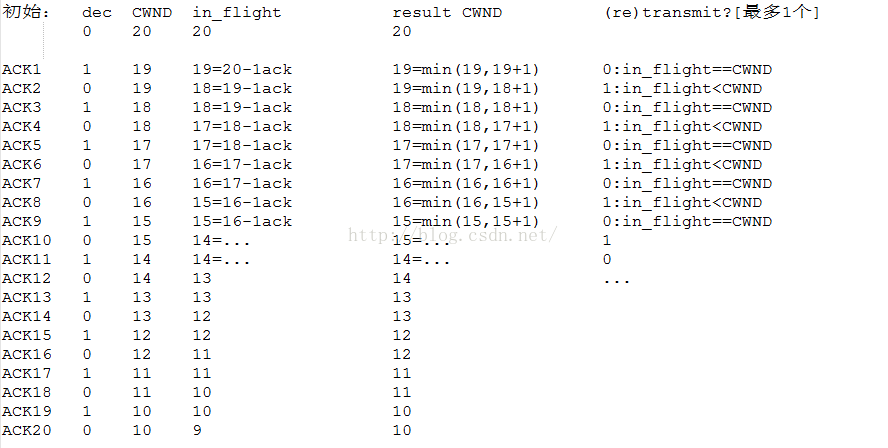
很完美!一共20個ACK,減掉一半的窗口(從20到10),20個ACK意味著在進入快速恢復的時刻一窗數據在一個RTT內被確認,但請注意,以上的例子是在理想情況下的降窗過程!仔細看的話就會發現,它嚴重依賴與in_flight這個變量,即“目前發出的,未被確認,未標記為LOST”的數據包的數量。理想情況下,in_flight的值就是一窗的數據,即一個窗口的大小,但是事實上是那樣嗎?我們知道,數據包的發送,確認,標記丟失三者之間是解耦合的:
1.你無法保證發送路徑或者重傳路徑一定會發送一個窗口那麼多的包
2.你無法保證即便發出了一個窗口的包,update計分板(詳見RFC3517的Update例程)的時候不會有大量數據包被標記為LOST
因此,在rate halving算法中,in_flight值可能會陡降,帶來的效果就是CWND陡降,然而卻沒有補償,比如下面這個稍微變態些的例子:

如果發生了大量的數據包被標記為LOST,情形如上,事實上降窗過程對此事毫不知情,FACK模式下一個攜帶SACK的包就可能標記很多包為LOST!除此之外,rate halving降窗算法中,以ACK數量而不是ACKed的字節數來作為標尺,這看似是一件好事,但是由於ACKed的字節數會直接體現在in_flight變量中,結果就是,如果一個ACK確認大量的字節,in_flight會變小,最終取min的時候,還是會造成窗口陡降!不過這也倒是迎合了RFC2582的建議:
Deflate the congestion window by the amount of new data acknowledged, then add back one MSS and send a new
segment if permitted by the new value of cwnd. This "partial window deflation" attempts to ensure that, when
Fast Recovery eventually ends, approximately ssthresh amount of data will be outstanding in the network.
但是不同的是什麼?不同是NewReno在快速恢復階段的窗口是從ssthresh逐步以擁塞避免方式增加的,而Linux rate halving算法在快速恢復階段窗口是只降不升的,這是根本的區別,NewReno在收到patial ACK的時候降窗的理由在Linux rate halving看來並不充分:
Note that in Step 5, the congestion window is deflated when a partial acknowledgement is received.
The congestion window was likely to have been inflated considerably when the partial acknowledgement
was received. In addition, depending on the original pattern of packet losses, the partial acknowledgement
might acknowledge nearly a window of data. In this case, if the congestion window was not deflated, the
data sender might be able to send nearly a window of data back-to-back.
現在我們知道Linux rate halving降窗算法的實際效果了,現在我們來看一下窗口陡降帶來的影響以及造成這種影響的根源。窗口陡降的效果就是它會降到ssthresh以下,從而在快速恢復階段結束後進入慢啟動狀態。其實如果你仔細看這個算法,會發現它根本就沒有檢查ssthresh,而只是限定了“halving”這個動作,因此就算窗口不是陡降,算法也無法感知窗口與ssthresh當前的關系。
Linux rate halving的根源在於:
1.如其名稱中的half單詞,它的目標是將窗口減半,然而首先,並不是所有的擁塞控制算法都是將窗口減半的,這只是早期Reno/NewReno的規范而已;
2.即便是將窗口減半,在執行的過程中,算法並沒有好好的履行承諾,而是過分依賴於一個自己無法控制的in_flight變量,且被其控制;
3.再退一步,即便窗口已經降到了一半以下(已經不再用ssthresh約束它了),Linux rate halving算法並沒有任何補償措施將窗口拉上來;
4.拋開窗口會降到哪裡不說,Linux rate halving算法在快速恢復階段,每次最多只允許1個數據段被發送,即窗口in_flight+1。
鑒於Linux rate halving的不足,google推出了其Linux PRR算法,解決了上面提到的三個問題。
google的Linux PRR降窗算法
我們先看它解決了哪些問題,針對Linux rate halving的缺點,PRR算法:
1.不再僅僅halving,而是完全根據擁塞算法計算出的ssthresh,來將窗口逼近於它;
2.執行的過程不再受當前的in_flight控制,而是根據快速重傳以來的發送/接收ACK的總數量來將窗口按照等比例的方式逼近ssthresh;
3.如果窗口降到了ssthresh以下(比如沒有數據包可發送或大量包被標記LOST),算法執行慢啟動將其拉升到ssthresh附近;
4快速恢復階段,最多“還”可以發送(或者說重傳)多少數據,不再限定為1,而是取決於“當前收到的ACK/SACK總量,發出數據總量,窗口與ssthresh的關系”。
其中最重要的是上述第2點,它簡單的指出了PRR算法是依靠ACK來驅動的,這就形成了一個反饋系統,只可惜PRR只利用了這個反饋系統的一部分,另一部分待我
在下一部分描述我的一個優化時再討論。緊跟著上面的4點,這個PRR算法的最終效果就是:
1).在快速恢復過程中,擁塞窗口非常平滑地向ssthresh收斂;
2).在快速恢復結束後,擁塞窗口處在ssthresh附近。
為了實現上述的目標,PRR降窗算法必須實時監控以下的變量:
in_flight:它是窗口的一個度量,in_flight的值任何時候都不能大於擁塞窗口的大小。
(s)acked:本次收到ACK進入降窗函數的時候,一共被ACK或者SACK的數據段數量。它度量了本次從網絡中清空了哪些數據段,從而影響in_flight。
out:進入快速恢復狀態後已經被發送了多少數據包。在transmit例程和retransmit例程中遞增。
to_be_out:當前還可以再發多少數據包。