


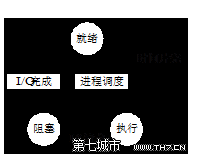
 進程因創建而就緒,因調度而執行;因時間片用完而重新就緒;
執行中因I/O請求而阻塞;
I/O完成而就緒
注意:阻塞以後不能直接執行,必須進入就緒狀態。
運行態:進程占用CPU,並在CPU上運行;
就緒態:進程已經具備運行條件,但是CPU還沒有分配過來;
阻塞態:進程因等待某件事發生而暫時不能運行;
進程在一生中,都處於上述3中狀態之一。
知道了進程的三種基本狀態,但是在操作系統具體實現中,設計者可以根據實際情況設計不同的狀態,於是就有了以下幾種狀態:
Linux內核中的進程狀態
進程因創建而就緒,因調度而執行;因時間片用完而重新就緒;
執行中因I/O請求而阻塞;
I/O完成而就緒
注意:阻塞以後不能直接執行,必須進入就緒狀態。
運行態:進程占用CPU,並在CPU上運行;
就緒態:進程已經具備運行條件,但是CPU還沒有分配過來;
阻塞態:進程因等待某件事發生而暫時不能運行;
進程在一生中,都處於上述3中狀態之一。
知道了進程的三種基本狀態,但是在操作系統具體實現中,設計者可以根據實際情況設計不同的狀態,於是就有了以下幾種狀態:
Linux內核中的進程狀態
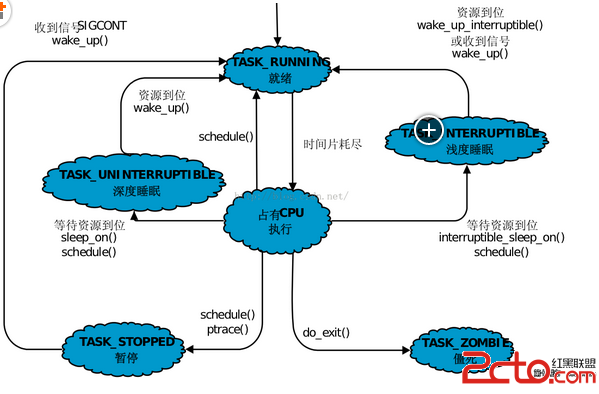 運行狀態(TASK_RUNNING)
可中斷睡眠狀態(TASK_INTERRUPTIBLE)
不可中斷睡眠狀態(TASK_UNINTERRUPTIBLE)
暫停狀態(TASK_STOPPED)
僵死狀態(TASK_ZOMBIE)
進程調度
進程調度的任務
保存處理機的現場信息
按某種算法選取進程
把處理器分配給進程
進程編程相關術語
進程標志:
每個進程都會分配到一個獨一無二的數字編號,我們稱之為“進程標識”(process identifier),或者就直接叫它PID.
是一個正整數,取值范圍從2到32768
當一個進程被啟動時,它會順序挑選下一個未使用的編號數字做為自己的PID
1號進程是特殊進程init
0號進程空閒進程
關於0,1的解釋:
進程0:Linux引導中創建的第一個進程,完成加載系統後,演變為進程調度、交換及存儲管理進程;
進程1:init 進程,由0進程創建,完成系統的初始化. 是系統中所有其它用戶進程的祖先進程;
Linux內核通過一個被稱為進程描述符的task_struct結構體來管理進程,這個結構體包含了一個進程所需的所有信息。
進程創建
不同的操作系統所提供的進程創建原語的名稱和格式不盡相同,但執行創建進程原語後,操作系統所做的工作卻大致相同,都包括以下幾點:
(1)給新創建的進程分配一個內部標識,在內核中建立進程結構。
(2)復制父進程的環境
(3)為進程分配資源, 包括進程映像所需要的所有元素(程序、數據、用戶棧等),
(4)復制父進程地址空間的內容到該進程地址空間中。
(5)置該進程的狀態為就緒,插入就緒隊列。
進程撤銷
進程終止時操作系統做以下工作:
(1)關閉軟中斷:因為進程即將終止而不再處理任何軟中斷信號;
(2)回收資源:釋放進程分配的所有資源,如關閉所有已打開文件,釋放進程相應的數據結構等;
(3)寫記帳信息:將進程在運行過程中所產生的記帳數據(其中包括進程運行時的各種統計信息)記錄到一個全局記帳文件中;
(4)置該進程為僵死狀態:向父進程發送子進程死的軟中斷信號,將終止信息status送到指定的存儲單元中;
(5)轉進程調度:因為此時CPU已經被釋放,需要由進程調度進行CPU再分配。
fork系統調用
復制一個進程映象
使用fork函數得到的子進程從父進程的繼承了整個進程的地址空間,包括:進程上下文、進程堆棧、內存信息、打開的文件描述符、信號控制設置、進程優先級、進程組號、當前工作目錄、根目錄、資源限制、控制終端等。
子進程與父進程的區別:
1、父進程設置的鎖,子進程不繼承
2、各自的進程ID: 父子進程ID不同
3、子進程的未決警告被清除;
4、子進程的未決信號集設置為空集;
fork系統調用
[cpp] view plaincopy在CODE上查看代碼片派生到我的代碼片
#include <unistd.h>
pid_t fork(void);
創建一個子進程
返回值:
如果成功創建一個子進程,對於父進程來說返回子進程ID
如果成功創建一個子進程,對於子進程來說返回值為0
如果為-1表示創建失敗
怎樣理解fork函數一次調用,二次返回?
問題的本質是:兩次返回,是在各自的進程空間中返回的。
子進程和父進程各有自己的內存空間 (fork:代碼段、數據段、堆棧段、PCB進程控制塊的copy)。
子進程對的count的改變並不會影響到父進程,因為他們有著自己的數據段。
運行狀態(TASK_RUNNING)
可中斷睡眠狀態(TASK_INTERRUPTIBLE)
不可中斷睡眠狀態(TASK_UNINTERRUPTIBLE)
暫停狀態(TASK_STOPPED)
僵死狀態(TASK_ZOMBIE)
進程調度
進程調度的任務
保存處理機的現場信息
按某種算法選取進程
把處理器分配給進程
進程編程相關術語
進程標志:
每個進程都會分配到一個獨一無二的數字編號,我們稱之為“進程標識”(process identifier),或者就直接叫它PID.
是一個正整數,取值范圍從2到32768
當一個進程被啟動時,它會順序挑選下一個未使用的編號數字做為自己的PID
1號進程是特殊進程init
0號進程空閒進程
關於0,1的解釋:
進程0:Linux引導中創建的第一個進程,完成加載系統後,演變為進程調度、交換及存儲管理進程;
進程1:init 進程,由0進程創建,完成系統的初始化. 是系統中所有其它用戶進程的祖先進程;
Linux內核通過一個被稱為進程描述符的task_struct結構體來管理進程,這個結構體包含了一個進程所需的所有信息。
進程創建
不同的操作系統所提供的進程創建原語的名稱和格式不盡相同,但執行創建進程原語後,操作系統所做的工作卻大致相同,都包括以下幾點:
(1)給新創建的進程分配一個內部標識,在內核中建立進程結構。
(2)復制父進程的環境
(3)為進程分配資源, 包括進程映像所需要的所有元素(程序、數據、用戶棧等),
(4)復制父進程地址空間的內容到該進程地址空間中。
(5)置該進程的狀態為就緒,插入就緒隊列。
進程撤銷
進程終止時操作系統做以下工作:
(1)關閉軟中斷:因為進程即將終止而不再處理任何軟中斷信號;
(2)回收資源:釋放進程分配的所有資源,如關閉所有已打開文件,釋放進程相應的數據結構等;
(3)寫記帳信息:將進程在運行過程中所產生的記帳數據(其中包括進程運行時的各種統計信息)記錄到一個全局記帳文件中;
(4)置該進程為僵死狀態:向父進程發送子進程死的軟中斷信號,將終止信息status送到指定的存儲單元中;
(5)轉進程調度:因為此時CPU已經被釋放,需要由進程調度進行CPU再分配。
fork系統調用
復制一個進程映象
使用fork函數得到的子進程從父進程的繼承了整個進程的地址空間,包括:進程上下文、進程堆棧、內存信息、打開的文件描述符、信號控制設置、進程優先級、進程組號、當前工作目錄、根目錄、資源限制、控制終端等。
子進程與父進程的區別:
1、父進程設置的鎖,子進程不繼承
2、各自的進程ID: 父子進程ID不同
3、子進程的未決警告被清除;
4、子進程的未決信號集設置為空集;
fork系統調用
[cpp] view plaincopy在CODE上查看代碼片派生到我的代碼片
#include <unistd.h>
pid_t fork(void);
創建一個子進程
返回值:
如果成功創建一個子進程,對於父進程來說返回子進程ID
如果成功創建一個子進程,對於子進程來說返回值為0
如果為-1表示創建失敗
怎樣理解fork函數一次調用,二次返回?
問題的本質是:兩次返回,是在各自的進程空間中返回的。
子進程和父進程各有自己的內存空間 (fork:代碼段、數據段、堆棧段、PCB進程控制塊的copy)。
子進程對的count的改變並不會影響到父進程,因為他們有著自己的數據段。
//示例: 父子進程中數據的關系(其實基本沒關系)
int main(int argc, char *argv[])
{
signal(SIGCHLD, SIG_IGN);
int count = 10;
pid_t pid = fork();
if (pid == -1)
err_exit("fork error");
else if (pid == 0)//子進程
{
++ count;
cout << "In child: pid = " << getpid() << ", ppid = " << getppid() << endl;
cout << "count = " << count << endl;
}
else if (pid > 0)//父進程
{
++ count;
cout << "In parent: pid = " << getpid() << ", child pid = " << pid << endl;
cout << "count = " << count << endl;
}
exit(0);
}
//深入理解: Hello World 為什麼會打印8次
int main(int argc, char *argv[])
{
signal(SIGCHLD, SIG_IGN);
fork();//每個fork創建一個子進程,然後復制父親的進程,繼續向下執行,所以就像一個二叉樹,有4層,所以一共執行了8次 hello wold
fork();
fork();
cout << "Hello World" << endl;
exit(0);
}
//示例: 產生N個子進程
int main(int argc, char *argv[])
{
signal(SIGCHLD, SIG_IGN);
int processCount;
cin >> processCount;
for (int i = 0; i < processCount; ++i)
{
pid_t pid = fork();
if (pid < 0)
err_exit("fork error");
else if (pid == 0)
{
cout << "Child ..." << endl;
exit(0);
}
}
exit(0);
}
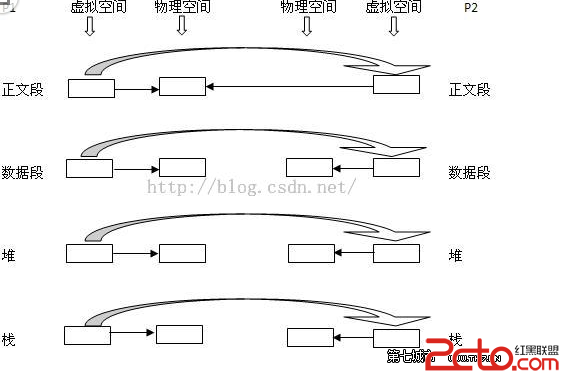
COW初窺: 在Linux程序中,fork()會產生一個和父進程完全相同的子進程,但子進程在此後多會exec系統調用,出於效率考慮,Linux中引入了“寫時復制“技術,也就是只有進程空間的各段的內容要發生變化時,才會將父進程的內容復制一份給子進程。 那麼子進程的物理空間沒有代碼,怎麼去取指令執行exec系統調用呢? 在fork之後exec之前兩個進程用的是相同的物理空間(內存區),子進程的代碼段、數據段、堆棧都是指向父進程的物理空間,也就是說,兩者的虛擬空間不同,但其對應的物理空間是同一個。當父子進程中有更改相應段的行為發生時,再為子進程相應的段分配物理空間,如果不是因為exec,內核會給子進程的數據段、堆棧段分配相應的物理空間(至此兩者有各自的進程空間,互不影響),而代碼段繼續共享父進程的物理空間(兩者的代碼完全相同)。而如果是因為exec,由於兩者執行的代碼不同,子進程的代碼段也會分配單獨的物理空間。 COW詳述: 現在有一個父進程P1,這是一個主體,那麼它是有靈魂也就身體的。現在在其虛擬地址空間(有相應的數據結構表示)上有:正文段,數據段,堆,棧這四個部分,相應的,內核要為這四個部分分配各自的物理塊。即:正文段塊,數據段塊,堆塊,棧塊。 1. 現在P1用fork()函數為進程創建一個子進程P2, 內核: (1)復制P1的正文段,數據段,堆,棧這四個部分,注意是其內容相同。 (2)為這四個部分分配物理塊,P2的:正文段->P1的正文段的物理塊,其實就是不為P2分配正文段塊,讓P2的正文段指向P1的正文段塊,數據段->P2自己的數據段塊(為其分配對應的塊),堆->P2自己的堆塊,棧->P2自己的棧塊。 如下圖所示:從左到右大的方向箭頭表示復制內容。
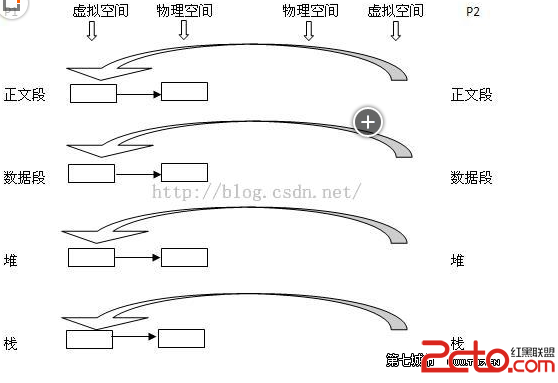
 2.寫時復制技術:內核只為新生成的子進程創建虛擬空間結構,它們復制於來自父進程的虛擬空間結構,但是不為這些段分配物理內存,它們共享父進程的物理空間,當父子進程中有更改相應段的行為發生時,再為子進程相應的段分配物理空間。
3. vfork():這個做法更加火爆,內核連子進程的虛擬地址空間結構也不創建了,直接共享了父進程的虛擬空間,當然了,這種做法就順水推舟的共享了父進程的物理空間
2.寫時復制技術:內核只為新生成的子進程創建虛擬空間結構,它們復制於來自父進程的虛擬空間結構,但是不為這些段分配物理內存,它們共享父進程的物理空間,當父子進程中有更改相應段的行為發生時,再為子進程相應的段分配物理空間。
3. vfork():這個做法更加火爆,內核連子進程的虛擬地址空間結構也不創建了,直接共享了父進程的虛擬空間,當然了,這種做法就順水推舟的共享了父進程的物理空間
 小結: 進程是一個主體,那麼它就有靈魂與身體,系統必須為實現它創建相應的實體, 靈魂實體與物理實體。這兩者在系統中都有相應的數據結構表示,物理實體更是體現了它的物理意義。
傳統的fork()系統調用直接把所有的資源復制給新創建的進程。這種實現過於簡單並且效率低下,因為它拷貝的數據也許並不共享,更糟的情況是,如果新進程打算立即執行一個新的映像,那麼所有的拷貝都將前功盡棄。Linux的fork()使用寫時拷貝(copy-on-write)頁實現。寫時拷貝是一種可以推遲甚至免除拷貝數據的技術。內核此時並不復制整個進程地址空間,而是讓父進程和子進程共享同一個拷貝。只有在需要寫入的時候,數據才會被復制,從而使各個進程擁有各自的拷貝。也就是說,資源的復制只有在需要寫入的時候才進行,在此之前,只是以只讀方式共享。這種技術使地址空間上的頁的拷貝被推遲到實際發生寫入的時候。在頁根本不會被寫入的情況下{舉例來說:fork()後立即調用exec()}它們就無需復制了。fork()的實際開銷就是復制父進程的頁表以及給子進程創建惟一的進程描述符。在一般情況下,進程創建後都會馬上運行一個可執行的文件,這種優化可以避免拷貝大量根本就不會被使用的數據(地址空間裡常常包含數十兆的數據)。由於Unix強調進程快速執行的能力,所以這個優化是很重要的。這裡補充一點:Linux COW與exec沒有必然聯系。
string str1 = "hello world";
string str2 = str1;
之後執行代碼:
str1[1]='q';
str2[1]='w';
在開始的兩個語句後,str1和str2存放數據的地址是一樣的,而在修改內容後,str1的地址發生了變化,而str2的地址還是原來的,這就是C++中的COW技術的應用;
小結: 進程是一個主體,那麼它就有靈魂與身體,系統必須為實現它創建相應的實體, 靈魂實體與物理實體。這兩者在系統中都有相應的數據結構表示,物理實體更是體現了它的物理意義。
傳統的fork()系統調用直接把所有的資源復制給新創建的進程。這種實現過於簡單並且效率低下,因為它拷貝的數據也許並不共享,更糟的情況是,如果新進程打算立即執行一個新的映像,那麼所有的拷貝都將前功盡棄。Linux的fork()使用寫時拷貝(copy-on-write)頁實現。寫時拷貝是一種可以推遲甚至免除拷貝數據的技術。內核此時並不復制整個進程地址空間,而是讓父進程和子進程共享同一個拷貝。只有在需要寫入的時候,數據才會被復制,從而使各個進程擁有各自的拷貝。也就是說,資源的復制只有在需要寫入的時候才進行,在此之前,只是以只讀方式共享。這種技術使地址空間上的頁的拷貝被推遲到實際發生寫入的時候。在頁根本不會被寫入的情況下{舉例來說:fork()後立即調用exec()}它們就無需復制了。fork()的實際開銷就是復制父進程的頁表以及給子進程創建惟一的進程描述符。在一般情況下,進程創建後都會馬上運行一個可執行的文件,這種優化可以避免拷貝大量根本就不會被使用的數據(地址空間裡常常包含數十兆的數據)。由於Unix強調進程快速執行的能力,所以這個優化是很重要的。這裡補充一點:Linux COW與exec沒有必然聯系。
string str1 = "hello world";
string str2 = str1;
之後執行代碼:
str1[1]='q';
str2[1]='w';
在開始的兩個語句後,str1和str2存放數據的地址是一樣的,而在修改內容後,str1的地址發生了變化,而str2的地址還是原來的,這就是C++中的COW技術的應用;