作者杜航,Websense雲基礎架構組開發經理,專注於OpenStack和Docker。以下為原文:
第 一次接觸CaaS這個概念,第一次接觸靈雀雲的時候,我並沒有像很多人一樣馬上推送一個應用以體驗Docker所帶來的快感。因為我從不懷疑docker 的出現所解決環境依賴性問題,提高了產品部署速度。我也從不懷疑靈雀雲作為一個CaaS共有雲平台對容易的管理,調度,運行的能力。這就是Docker以 及CaaS平台出現帶來的優勢,一分鐘之前我還剛把代碼提交到github,一分鐘之後我提交的代碼已經在生產環境上線。可能是因為我長期和一個十分嚴謹 又追求完美的英國團隊,特別是英國運維團隊合作的背景,在審視任何一個新東西的時候我都會先去嘗試發現它與production ready之間到底有多少距離。所以當我准備把應用推送到靈雀雲之前,我首先考慮的是除了應用之外我還需要部署什麼樣的服務來達到生產環境的標准。
第 一點考慮到的是log的處理。我想我不需要花太多篇幅解釋log的重要性,大家應該都有體會。Docker作為一個短暫存在(ephemeral)的運行 環境,數據的持久化是一個要解決的問題。CaaS平台不會像IaaS那樣給你vm的登錄管理權限,所以你不能想把docker容器運行在物理主機或者虛擬 主機上那樣通過將存儲卷映射到主機上或者鏈接一個數據容器(data-only container)來保存log數據。靈雀雲平台提供了存儲卷的功能,可以將log數據存放在一個穩定的雲存儲平台(從鏈接看是AWS S3)並提供下載。當時當你管理上百個甚至上千個容器的時候,這種方式也會給你帶來很大的工作量。綜合以上原因,我決定在靈雀雲上搭建一個ELK stack。(E – Elasticsearch, L – Logstash, K – Kibana)
我沒有使用網上現有的ELK image,原因有三:
深度CentOS依賴者;
體驗一下靈雀雲提供的代碼倉庫集成的功能;
將容器鏡像存儲在靈雀雲鏡像倉庫可以提高服務啟動速度
代碼可以在github找到https://github.com/darkheaven1983/elk
以下是如何在靈雀雲上部署ELK stack的具體步驟:
1. 關聯github代碼倉庫與靈雀雲構建系統,指明Dockerfile在github的路徑,並創建一個構建
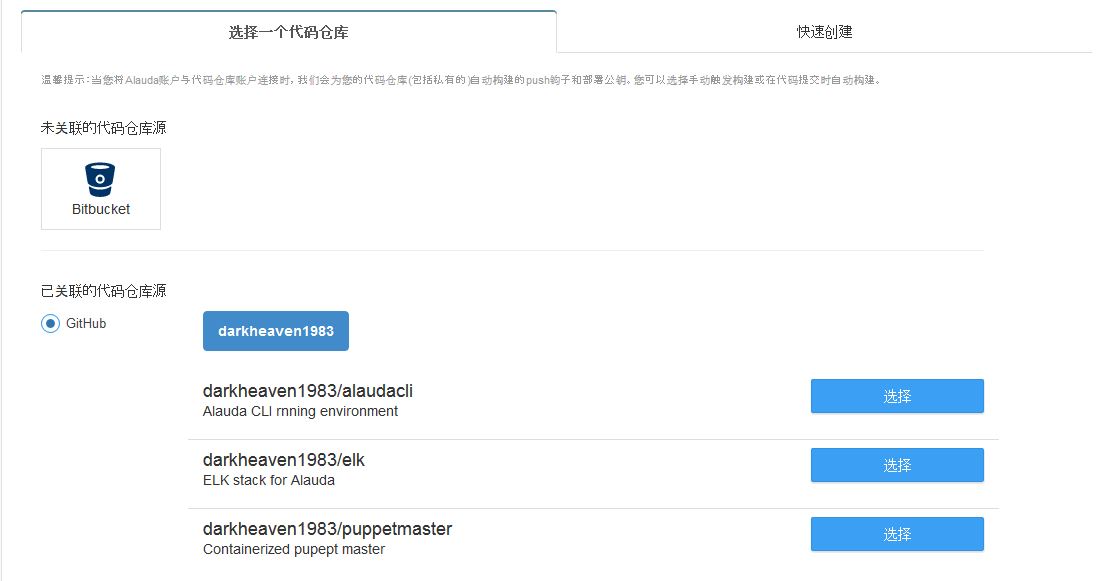
2. git push代碼到github觸發靈雀雲構建docker鏡像

鏡像build成功之後會出現在個人鏡像參倉庫裡面

3. 通過靈雀雲CLI提供的compose功能一鍵部署ELK stack。Alauda支持的compose在docker compose yaml文件的基礎之上做了一些針對自己平台的改動。

以下是elk-alauda.yml的內容
elasticsearch: extends: file: ./docker-compose.yml service: elasticsearch expose: - "9200" volumes: - /var/lib/elasticsearch:10 kibana: extends: file: ./docker-compose.yml service: kibana ports: - "5601/http" links: - elasticsearch:elasticsearch logstash: extends: file: ./docker-compose.yml service: logstash ports: - "5000" links: - elasticsearch:elasticsearch
extends:關聯docker compose yaml文件當中對此容器的配置。
expose:指定一個只有Alauda內部才能訪問的端口,我將elsaticsearch的9200端口聲明為內部端口保證了數據的安全性,避免將9200端口暴露在公網上。
volumes:創建一個存儲卷,確保數據的持久化 – 可以通過alauda CLI中backup功能定期保存存儲卷,並且從某一個指定的存儲卷恢復數據。
ports:指定一個公網可訪問的端口,此端口可以為load balance之後的http端口(80),也可以是load balance之後的TCP端口(隨機)。
links:容器之間的連接 – 通過Alauda提供的服務發現功能鏈接多個容器是容器間可以互相訪問。
至此,ELK stack在alauda平台的搭建已經結束。由於本實驗只是一個PoC的功能,所以logstash的輸入是tcp,歡迎大家加入更加復雜的logstash配置。
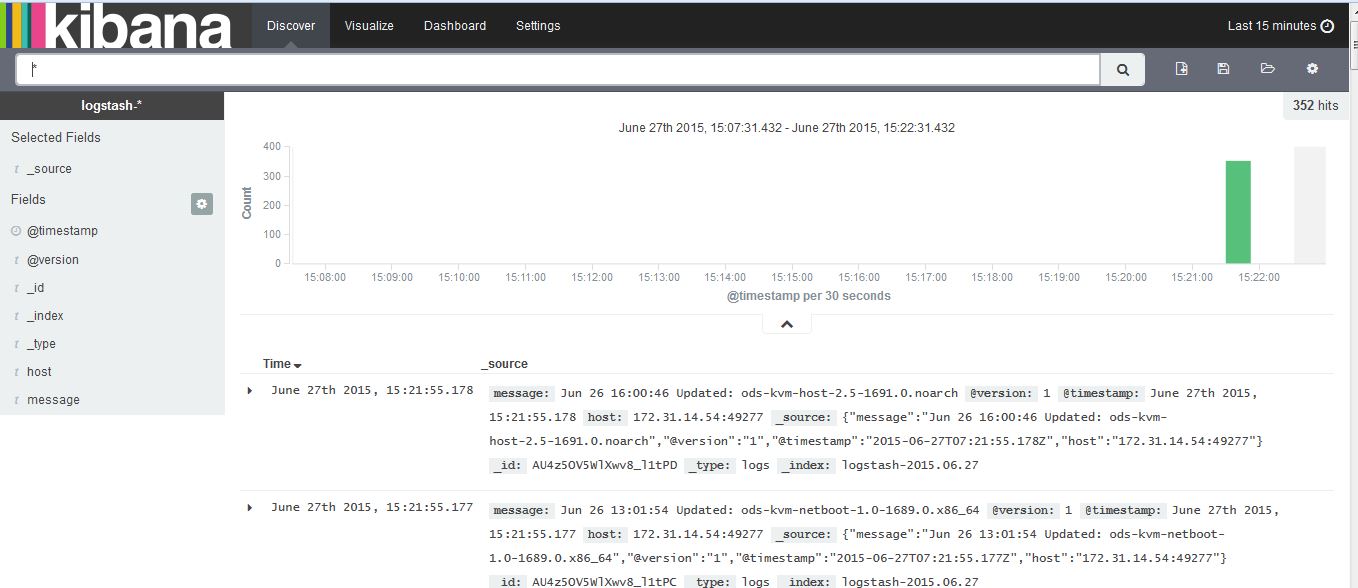
測試結果:
nc logstash-darkheaven.myalauda.cn 62316 < /var/log/yum.log