不小心刪除了spark的目錄,但是hadoop集群是使用 NFS 來同步spark的整個目錄。
showmount 命令用於查詢NFS服務器的相關信息,在所有slave上執行 showmount -e,提示:
mount clntudp_create: RPC: Program not registered
rpc.mountd 命令全名叫 NFS mount daemon,執行後部分機器恢復正常,但仍有部分slave提示:
clnt_create: RPC: Port mapper failure - Unable to receive: errno 111 (Connection refused)
根據以上的錯誤提示,可以大概知道是RPC的問題。
NFS(Network FileSystem)服務啟動時會綁定一個隨機的端口(至於為何要綁定隨機端口而不是指定固定端口可能是為了防止沖突),
並會通知到RPC服務(RPC服務的進程由一個叫rpcbind的程序來完成,它會綁定一個固定的端口如111),NFS借助這個隨機端口來實現與客戶端的文件傳輸與狀態共享,
因此客戶端一開始需要向RPC服務端詢問NFS具體綁定的端口信息。整個NFS集群包含NFS和RPC兩部分,並且NFS的工作依賴於RPC。
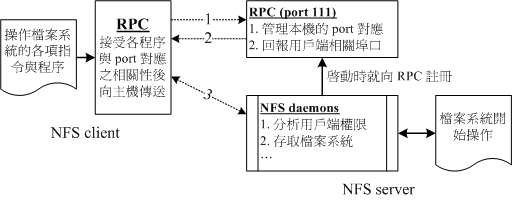
說完原理,再來解釋報錯的含義:
先卸載目錄掛載:umount /spark,出錯:umount.nfs: /spark: device is busy
查找使用該目錄的進程:fuser -m -v /spark/,仍舊報錯:Cannot stat : Stale file handle
於是強制卸載:umount -l /spark,執行成功但是showmount 繼續報錯。
於是只好重啟NFS了:service rpcbind restart、service nfs restart
這裡必須先重啟RPC然後再啟動NFS,否則會報錯:
Starting NFS mountd: [FAILED]
Starting NFS daemon: rpc.nfsd: writing fd to kernel failed: errno 111 (Connection refused)
rpc.nfsd: unable to set any sockets for nfsd
原因前面已經講過,恢復整個集群的腳本如下:
ssh='ssh -p2222'
all_slave={1..10}
eval eval \"$ssh slave\"$all_slave\" \'rpc.mountd\'\;\"
eval eval \"$ssh slave\"$all_slave\" \'umount -l /spark\'\;\"
eval eval \"$ssh slave\"$all_slave\" \'service rpcbind restart \&\& service nfs restart\'\;\"
eval eval \"$ssh slave\"$all_slave\" \'mount -t nfs master:/spark/ /spark/\'\;\"
master:/root/.ssh/ on /root/.ssh type nfs (rw,vers=4,addr=master,clientaddr=slave1) master:/usr/local/java/ on /usr/local/java type nfs (rw,vers=4,addr=master,clientaddr=slave1) master:/tmp/logs/ on /tmp/logs/ type nfs (rw,vers=4,addr=master,clientaddr=slave1) nfsd on /proc/fs/nfsd type nfsd (rw) master:/spark/ on /spark type nfs (rw,vers=4,addr=master,clientaddr=slave1)原文:http://my.oschina.net/cwalet/blog/386601