對於傳統的操作系統來說,普通的 I/O 操作一般會被內核緩存,這種 I/O 被稱作緩存 I/O。本文所介紹的文件訪問機制不經過操作系統內核的緩存,數據直接在磁盤和應用程序地址空間進行傳輸,所以該文件訪問的機制稱作為直接 I/O。
Linux 中就提供了這樣一種文件訪問機制,對於那種將 I/O 緩存存放在用戶地址空間的應用程序來說,直接 I/O 是一種非常高效的手段。本文將基於 2.6.18 版本的內核來討論 Linux 中直接 I/O 的技術的設計與實現。
直接 I/O 的動機
在介紹直接 I/O 之前,這一小節先介紹一下為什麼會出現直接 I/O 這種機制,即傳統的 I/O 操作存在哪些缺點。
什麼是緩存 I/O (Buffered I/O)
緩存 I/O 又被稱作標准 I/O,大多數文件系統的默認 I/O 操作都是緩存 I/O。在 Linux 的緩存 I/O 機制中,操作系統會將 I/O 的數據緩存在文件系統的頁緩存( page cache )中,也就是說,數據會先被拷貝到操作系統內核的緩沖區中,然後才會從操作系統內核的緩沖區拷貝到應用程序的地址空間。緩存 I/O 有以下這些優點:
-
緩存 I/O 使用了操作系統內核緩沖區,在一定程度上分離了應用程序空間和實際的物理設備。
-
緩存 I/O 可以減少讀盤的次數,從而提高性能。
當應用程序嘗試讀取某塊數據的時候,如果這塊數據已經存放在了頁緩存中,那麼這塊數據就可以立即返回給應用程序,而不需要經過實際的物理讀盤操作。當然,如果數據在應用程序讀取之前並未被存放在頁緩存中,那麼就需要先將數據從磁盤讀到頁緩存中去。對於寫操作來說,應用程序也會將數據先寫到頁緩存中去,數據是否被立即寫到磁盤上去取決於應用程序所采用的寫操作機制:如果用戶采用的是同步寫機制( synchronous writes ), 那麼數據會立即被寫回到磁盤上,應用程序會一直等到數據被寫完為止;如果用戶采用的是延遲寫機制( deferred writes ),那麼應用程序就完全不需要等到數據全部被寫回到磁盤,數據只要被寫到頁緩存中去就可以了。在延遲寫機制的情況下,操作系統會定期地將放在頁緩存中的數據刷到磁盤上。與異步寫機制( asynchronous writes )不同的是,延遲寫機制在數據完全寫到磁盤上的時候不會通知應用程序,而異步寫機制在數據完全寫到磁盤上的時候是會返回給應用程序的。所以延遲寫機制本身是存在數據丟失的風險的,而異步寫機制則不會有這方面的擔心。
緩存 I/O 的缺點
在緩存 I/O 機制中,DMA 方式可以將數據直接從磁盤讀到頁緩存中,或者將數據從頁緩存直接寫回到磁盤上,而不能直接在應用程序地址空間和磁盤之間進行數據傳輸,這樣的話,數據在傳輸過程中需要在應用程序地址空間和頁緩存之間進行多次數據拷貝操作,這些數據拷貝操作所帶來的 CPU 以及內存開銷是非常大的。
對於某些特殊的應用程序來說,避開操作系統內核緩沖區而直接在應用程序地址空間和磁盤之間傳輸數據會比使用操作系統內核緩沖區獲取更好的性能,下邊這一小節中提到的自緩存應用程序就是其中的一種。
自緩存應用程序( self-caching applications)
對於某些應用程序來說,它會有它自己的數據緩存機制,比如,它會將數據緩存在應用程序地址空間,這類應用程序完全不需要使用操作系統內核中的高速緩沖存儲器,這類應用程序就被稱作是自緩存應用程序( self-caching applications )。
數據庫管理系統是這類應用程序的一個代表。自緩存應用程序傾向於使用數據的邏輯表達方式,而非物理表達方式;當系統內存較低的時候,自緩存應用程序會讓這種數據的邏輯緩存被換出,而並非是磁盤上實際的數據被換出。自緩存應用程序對要操作的數據的語義了如指掌,所以它可以采用更加高效的緩存替換算法。自緩存應用程序有可能會在多台主機之間共享一塊內存,那麼自緩存應用程序就需要提供一種能夠有效地將用戶地址空間的緩存數據置為無效的機制,從而確保應用程序地址空間緩存數據的一致性。
對於自緩存應用程序來說,緩存 I/O 明顯不是一個好的選擇。由此引出我們這篇文章著重要介紹的 Linux 中的直接 I/O 技術。Linux 中的直接 I/O 技術非常適用於自緩存這類應用程序,該技術省略掉緩存 I/O 技術中操作系統內核緩沖區的使用,數據直接在應用程序地址空間和磁盤之間進行傳輸,從而使得自緩存應用程序可以省略掉復雜的系統級別的緩存結構,而執行程序自己定義的數據讀寫管理,從而降低系統級別的管理對應用程序訪問數據的影響。在下面一節中,我們會著重介紹 Linux 中提供的直接 I/O 機制的設計與實現,該機制為自緩存應用程序提供了很好的支持。
Linux 2.6 中的直接 I/O 技術
Linux 2.6 中提供的幾種文件訪問方式
所有的 I/O 操作都是通過讀文件或者寫文件來完成的。在這裡,我們把所有的外圍設備,包括鍵盤和顯示器,都看成是文件系統中的文件。訪問文件的方法多種多樣,這裡列出下邊這幾種 Linux 2.6 中支持的文件訪問方式。
標准訪問文件的方式
在 Linux 中,這種訪問文件的方式是通過兩個系統調用實現的:read() 和 write()。當應用程序調用 read() 系統調用讀取一塊數據的時候,如果該塊數據已經在內存中了,那麼就直接從內存中讀出該數據並返回給應用程序;如果該塊數據不在內存中,那麼數據會被從磁盤上讀到頁高緩存中去,然後再從頁緩存中拷貝到用戶地址空間中去。如果一個進程讀取某個文件,那麼其他進程就都不可以讀取或者更改該文件;對於寫數據操作來說,當一個進程調用了 write() 系統調用往某個文件中寫數據的時候,數據會先從用戶地址空間拷貝到操作系統內核地址空間的頁緩存中去,然後才被寫到磁盤上。但是對於這種標准的訪問文件的方式來說,在數據被寫到頁緩存中的時候,write() 系統調用就算執行完成,並不會等數據完全寫入到磁盤上。Linux 在這裡采用的是我們前邊提到的延遲寫機制( deferred writes )。
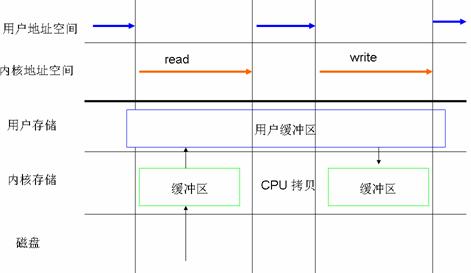
圖 1. 以標准的方式對文件進行讀寫
同步訪問文件的方式
同步訪問文件的方式與上邊這種標准的訪問文件的方式比較類似,這兩種方法一個很關鍵的區別就是:同步訪問文件的時候,寫數據的操作是在數據完全被寫回磁盤上才算完成的;而標准訪問文件方式的寫數據操作是在數據被寫到頁高速緩沖存儲器中的時候就算執行完成了。
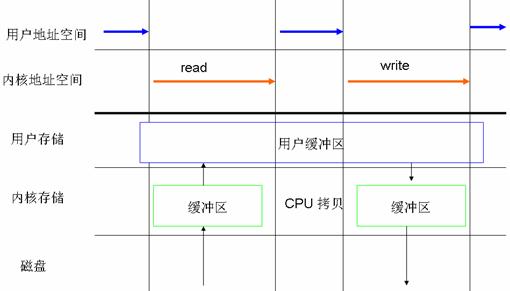
圖 2. 數據同步寫回磁盤
內存映射方式
在很多操作系統包括 Linux 中,內存區域( memory region )是可以跟一個普通的文件或者塊設備文件的某一個部分關聯起來的,若進程要訪問內存頁中某個字節的數據,操作系統就會將訪問該內存區域的操作轉換為相應的訪問文件的某個字節的操作。Linux 中提供了系統調用 mmap() 來實現這種文件訪問方式。與標准的訪問文件的方式相比,內存映射方式可以減少標准訪問文件方式中 read() 系統調用所帶來的數據拷貝操作,即減少數據在用戶地址空間和操作系統內核地址空間之間的拷貝操作。映射通常適用於較大范圍,對於相同長度的數據來講,映射所帶來的開銷遠遠低於 CPU 拷貝所帶來的開銷。當大量數據需要傳輸的時候,采用內存映射方式去訪問文件會獲得比較好的效率。
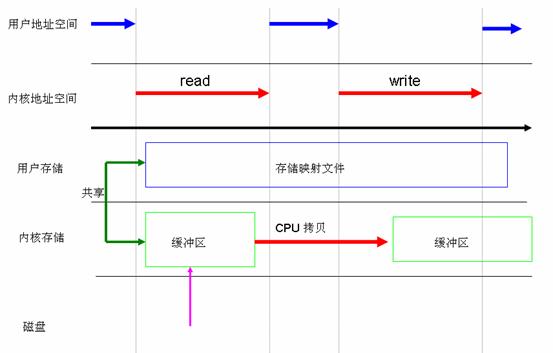
圖 3. 利用 mmap 代替 read
直接 I/O 方式
凡是通過直接 I/O 方式進行數據傳輸,數據均直接在用戶地址空間的緩沖區和磁盤之間直接進行傳輸,完全不需要頁緩存的支持。操作系統層提供的緩存往往會使應用程序在讀寫數據的時候獲得更好的性能,但是對於某些特殊的應用程序,比如說數據庫管理系統這類應用,他們更傾向於選擇他們自己的緩存機制,因為數據庫管理系統往往比操作系統更了解數據庫中存放的數據,數據庫管理系統可以提供一種更加有效的緩存機制來提高數據庫中數據的存取性能。
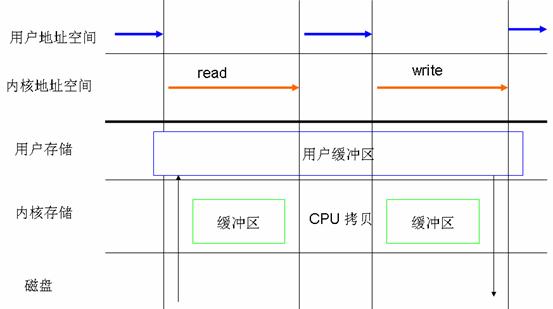
圖 4. 數據傳輸不經過操作系統內核緩沖區
異步訪問文件的方式
Linux 異步 I/O 是 Linux 2.6 中的一個標准特性,其本質思想就是進程發出數據傳輸請求之後,進程不會被阻塞,也不用等待任何操作完成,進程可以在數據傳輸的時候繼續執行其他的操作。相對於同步訪問文件的方式來說,異步訪問文件的方式可以提高應用程序的效率,並且提高系統資源利用率。直接 I/O 經常會和異步訪問文件的方式結合在一起使用。
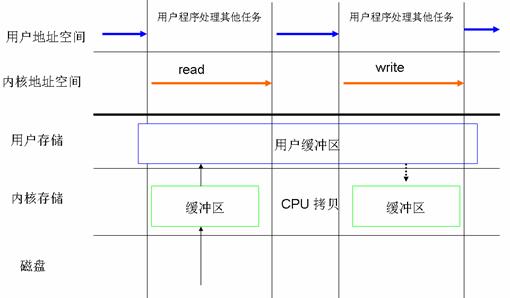
圖 5.CPU 處理其他任務和 I/O 操作可以重疊執行
在下邊這一小節中,我們會重點介紹 Linux 2.6 內核中直接 I/O 的設計與實現。
Linux 2.6 中直接 I/O 的設計與實現
在塊設備或者網絡設備中執行直接 I/O 完全不用擔心實現直接 I/O 的問題,Linux 2.6 操作系統內核中高層代碼已經設置和使用了直接 I/O,驅動程序級別的代碼甚至不需要知道已經執行了直接 I/O;但是對於字符設備來說,執行直接 I/O 是不可行的,Linux 2.6 提供了函數 get_user_pages() 用於實現直接 I/O。本小節會分別對這兩種情況進行介紹。
內核為塊設備執行直接 I/O 提供的支持
要在塊設備中執行直接 I/O,進程必須在打開文件的時候設置對文件的訪問模式為 O_DIRECT,這樣就等於告訴操作系統進程在接下來使用 read() 或者 write() 系統調用去讀寫文件的時候使用的是直接 I/O 方式,所傳輸的數據均不經過操作系統內核緩存空間。使用直接 I/O 讀寫數據必須要注意緩沖區對齊( buffer alignment )以及緩沖區的大小的問題,即對應 read() 以及 write() 系統調用的第二個和第三個參數。這裡邊說的對齊指的是文件系統塊大小的對齊,緩沖區的大小也必須是該塊大小的整數倍。
這一節主要介紹三個函數:open(),read() 以及 write()。Linux 中訪問文件具有多樣性,所以這三個函數對於處理不同的文件訪問方式定義了不同的處理方法,本文主要介紹其與直接 I/O 方式相關的函數與功能.首先,先來看 open() 系統調用,其函數原型如下所示:
int open(const char *pathname, int oflag, … /*, mode_t mode * / ) ;
以下列出了 Linux 2.6 內核定義的系統調用 open() 所使用的標識符宏定義:
表 1. open() 系統調用提供的標識符
標識符名 |
標識符描述 |
O_RDONLY
以只讀的方式打開文件
O_WRONLY
以只寫的方式打開文件
O_RDWR
以讀寫的方式打開文件
O_CREAT
若文件不存在,則創建該文件
O_EXCL
以獨占模式打開文件;若同時設置 O_EXCL 和 O_CREATE, 那麼若文件已經存在,則打開操作會失敗
O_NOCTTY
若設置該描述符,則該文件不可以被當成終端處理
O_TRUNC
截斷文件,若文件存在,則刪除該文件
O_APPEND
若設置了該描述符,則在寫文件之前,文件指針會被設置到文件的底部
O_NONBLOCK
以非阻塞的方式打開文件
O_NELAY
同 O_NELAY,若同時設置 O_NELAY 和 O_NONBLOCK,O_NONBLOCK 優先起作用
O_SYNC
該描述符會對普通文件的寫操作產生影響,若設置了該描述符,則對該文件的寫操作會等到數據被寫到磁盤上才算結束
FASYNC
若設置該描述符,則 I/O 事件通知是通過信號發出的
O_DIRECT
該描述符提供對直接 I/O 的支持
O_LARGEFILE
該描述符提供對超過 2GB 大文件的支持
O_DIRECTORY
該描述符表明所打開的文件必須是目錄,否則打開操作失敗
O_NOFOLLOW
若設置該描述符,則不解析路徑名尾部的符號鏈接
當應用程序需要直接訪問文件而不經過操作系統頁高速緩沖存儲器的時候,它打開文件的時候需要指定 O_DIRECT 標識符。
操作系統內核中處理 open() 系統調用的內核函數是 sys_open(),sys_open() 會調用 do_sys_open() 去處理主要的打開操作。它主要做了三件事情:首先, 它調用 getname() 從進程地址空間中讀取文件的路徑名;接著,do_sys_open() 調用 get_unused_fd() 從進程的文件表中找到一個空閒的文件表指針,相應的新文件描述符就存放在本地變量 fd 中;之後,函數 do_filp_open() 會根據傳入的參數去執行相應的打開操作。清單 1 列出了操作系統內核中處理 open() 系統調用的一個主要函數關系圖。
清單 1. 主要調用函數關系圖
sys_open()
|-----do_sys_open()
|---------getname()
|---------get_unused_fd()
|---------do_filp_open()
|--------nameidata_to_filp()
|----------__dentry_open()
函數 do_flip_open() 在執行的過程中會調用函數 nameidata_to_filp(),而 nameidata_to_filp() 最終會調用 __dentry_open() 函數,若進程指定了 O_DIRECT 標識符,則該函數會檢查直接 I./O 操作是否可以作用於該文件。清單 2 列出了 __dentry_open() 函數中與直接 I/O 操作相關的代碼。
清單 2. 函數 dentry_open() 中與直接 I/O 相關的代碼
if (f->f_flags & O_DIRECT) {
if (!f->f_mapping->a_ops ||
((!f->f_mapping->a_ops->direct_IO) &&
(!f->f_mapping->a_ops->get_xip_page))) {
fput(f);
f = ERR_PTR(-EINVAL);
}
}
當文件打開時指定了 O_DIRECT 標識符,那麼操作系統就會知道接下來對文件的讀或者寫操作都是要使用直接 I/O 方式的。
下邊我們來看一下當進程通過 read() 系統調用讀取一個已經設置了 O_DIRECT 標識符的文件的時候,系統都做了哪些處理。 函數 read() 的原型如下所示:
ssize_t read(int feledes, void *buff, size_t nbytes) ;
操作系統中處理 read() 函數的入口函數是 sys_read(),其主要的調用函數關系圖如下清單 3 所示:
清單 3. 主調用函數關系圖
sys_read()
|-----vfs_read()
|----generic_file_read()
|----generic_file_aio_read()
|--------- generic_file_direct_IO()
函數 sys_read() 從進程中獲取文件描述符以及文件當前的操作位置後會調用 vfs_read() 函數去執行具體的操作過程,而 vfs_read() 函數最終是調用了 file 結構中的相關操作去完成文件的讀操作,即調用了 generic_file_read() 函數,其代碼如下所示:
清單 4. 函數 generic_file_read()
ssize_t
generic_file_read(struct file *filp,
char __user *buf, size_t count, loff_t *ppos)
{
struct iovec local_iov = { .iov_base = buf, .iov_len = count };
struct kiocb kiocb;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
ret = __generic_file_aio_read(&kiocb, &local_iov, 1, ppos);
if (-EIOCBQUEUED == ret)
ret = wait_on_sync_kiocb(&kiocb);
return ret;
}
函數 generic_file_read() 初始化了 iovec 以及 kiocb 描述符。描述符 iovec 主要是用於存放兩個內容:用來接收所讀取數據的用戶地址空間緩沖區的地址和緩沖區的大小;描述符 kiocb 用來跟蹤 I/O 操作的完成狀態。之後,函數 generic_file_read() 凋用函數 __generic_file_aio_read()。該函數檢查 iovec 中描述的用戶地址空間緩沖區是否可用,接著檢查訪問模式,若訪問模式描述符設置了 O_DIRECT,則執行與直接 I/O 相關的代碼。函數 __generic_file_aio_read() 中與直接 I/O 有關的代碼如下所示:
清單 5. 函數 __generic_file_aio_read() 中與直接 I/O 有關的代碼
if (filp->f_flags & O_DIRECT) {
loff_t pos = *ppos, size;
struct address_space *mapping;
struct inode *inode;
mapping = filp->f_mapping;
inode = mapping->host;
retval = 0;
if (!count)
goto out;
size = i_size_read(inode);
if (pos < size) {
retval = generic_file_direct_IO(READ, iocb,
iov, pos, nr_segs);
if (retval > 0 && !is_sync_kiocb(iocb))
retval = -EIOCBQUEUED;
if (retval > 0)
*ppos = pos + retval;
}
file_accessed(filp);
goto out;
}
上邊的代碼段主要是檢查了文件指針的值,文件的大小以及所請求讀取的字節數目等,之後,該函數調用 generic_file_direct_io(),並將操作類型 READ,描述符 iocb,描述符 iovec,當前文件指針的值以及在描述符 io_vec 中指定的用戶地址空間緩沖區的個數等值作為參數傳給它。當 generic_file_direct_io() 函數執行完成,函數 __generic_file_aio_read()會繼續執行去完成後續操作:更新文件指針,設置訪問文件 i 節點的時間戳;這些操作全部執行完成以後,函數返回。 函數 generic_file_direct_IO() 會用到五個參數,各參數的含義如下所示:
-
rw:操作類型,可以是 READ 或者 WRITE
-
iocb:指針,指向 kiocb 描述符
-
iov:指針,指向 iovec 描述符數組
-
offset:file 結構偏移量
-
nr_segs:iov 數組中 iovec 的個數
函數 generic_file_direct_IO() 代碼如下所示:
清單 6. 函數 generic_file_direct_IO()
static ssize_t
generic_file_direct_IO(int rw, struct kiocb *iocb, const struct iovec *iov,
loff_t offset, unsigned long nr_segs)
{
struct file *file = iocb->ki_filp;
struct address_space *mapping = file->f_mapping;
ssize_t retval;
size_t write_len = 0;
if (rw == WRITE) {
write_len = iov_length(iov, nr_segs);
if (mapping_mapped(mapping))
unmap_mapping_range(mapping, offset, write_len, 0);
}
retval = filemap_write_and_wait(mapping);
if (retval == 0) {
retval = mapping->a_ops->direct_IO(rw, iocb, iov,
offset, nr_segs);
if (rw == WRITE && mapping->nrpages) {
pgoff_t end = (offset + write_len - 1)
>> PAGE_CACHE_SHIFT;
int err = invalidate_inode_pages2_range(mapping,
offset >> PAGE_CACHE_SHIFT, end);
if (err)
retval = err;
}
}
return retval;
}
函數 generic_file_direct_IO() 對 WRITE 操作類型進行了一些特殊處理,這在下邊介紹 write() 系統調用的時候再做說明。除此之外,它主要是調用了 direct_IO 方法去執行直接 I/O 的讀或者寫操作。在進行直接 I/O 讀操作之前,先將頁緩存中的相關髒數據刷回到磁盤上去,這樣做可以確保從磁盤上讀到的是最新的數據。這裡的 direct_IO 方法最終會對應到 __blockdev_direct_IO() 函數上去。__blockdev_direct_IO() 函數的代碼如下所示:
清單 7. 函數 __blockdev_direct_IO()
ssize_t
__blockdev_direct_IO(int rw, struct kiocb *iocb, struct inode *inode,
struct block_device *bdev, const struct iovec *iov, loff_t offset,
unsigned long nr_segs, get_block_t get_block, dio_iodone_t end_io,
int dio_lock_type)
{
int seg;
size_t size;
unsigned long addr;
unsigned blkbits = inode->i_blkbits;
unsigned bdev_blkbits = 0;
unsigned blocksize_mask = (1 << blkbits) - 1;
ssize_t retval = -EINVAL;
loff_t end = offset;
struct dio *dio;
int release_i_mutex = 0;
int acquire_i_mutex = 0;
if (rw & WRITE)
rw = WRITE_SYNC;
if (bdev)
bdev_blkbits = blksize_bits(bdev_hardsect_size(bdev));
if (offset & blocksize_mask) {
if (bdev)
blkbits = bdev_blkbits;
blocksize_mask = (1 << blkbits) - 1;
if (offset & blocksize_mask)
goto out;
}
for (seg = 0; seg < nr_segs; seg++) {
addr = (unsigned long)iov[seg].iov_base;
size = iov[seg].iov_len;
end += size;
if ((addr & blocksize_mask) || (size & blocksize_mask)) {
if (bdev)
blkbits = bdev_blkbits;
blocksize_mask = (1 << blkbits) - 1;
if ((addr & blocksize_mask) || (size & blocksize_mask))
goto out;
}
}
dio = kmalloc(sizeof(*dio), GFP_KERNEL);
retval = -ENOMEM;
if (!dio)
goto out;
dio->lock_type = dio_lock_type;
if (dio_lock_type != DIO_NO_LOCKING) {
if (rw == READ && end > offset) {
struct address_space *mapping;
mapping = iocb->ki_filp->f_mapping;
if (dio_lock_type != DIO_OWN_LOCKING) {
mutex_lock(&inode->i_mutex);
release_i_mutex = 1;
}
retval = filemap_write_and_wait_range(mapping, offset,
end - 1);
if (retval) {
kfree(dio);
goto out;
}
if (dio_lock_type == DIO_OWN_LOCKING) {
mutex_unlock(&inode->i_mutex);
acquire_i_mutex = 1;
}
}
if (dio_lock_type == DIO_LOCKING)
down_read_non_owner(&inode->i_alloc_sem);
}
dio->is_async = !is_sync_kiocb(iocb) && !((rw & WRITE) &&
(end > i_size_read(inode)));
retval = direct_io_worker(rw, iocb, inode, iov, offset,
nr_segs, blkbits, get_block, end_io, dio);
if (rw == READ && dio_lock_type == DIO_LOCKING)
release_i_mutex = 0;
out:
if (release_i_mutex)
mutex_unlock(&inode->i_mutex);
else if (acquire_i_mutex)
mutex_lock(&inode->i_mutex);
return retval;
}
該函數將要讀或者要寫的數據進行拆分,並檢查緩沖區對齊的情況。本文在前邊介紹 open() 函數的時候指出,使用直接 I/O 讀寫數據的時候必須要注意緩沖區對齊的問題,從上邊的代碼可以看出,緩沖區對齊的檢查是在 __blockdev_direct_IO() 函數裡邊進行的。用戶地址空間的緩沖區可以通過 iov 數組中的 iovec 描述符確定。直接 I/O 的讀操作或者寫操作都是同步進行的,也就是說,函數 __blockdev_direct_IO() 會一直等到所有的 I/O 操作都結束才會返回,因此,一旦應用程序 read() 系統調用返回,應用程序就可以訪問用戶地址空間中含有相應數據的緩沖區。但是,這種方法在應用程序讀操作完成之前不能關閉應用程序,這將會導致關閉應用程序緩慢。
接下來我們看一下 write() 系統調用中與直接 I/O 相關的處理實現過程。函數 write() 的原型如下所示:
ssize_t write(int filedes, const void * buff, size_t nbytes) ;
操作系統中處理 write() 系統調用的入口函數是 sys_write()。其主要的調用函數關系如下所示:
清單 8. 主調用函數關系圖
sys_write()
|-----vfs_write()
|----generic_file_write()
|----generic_file_aio_read()
|---- __generic_file_write_nolock()
|-- __generic_file_aio_write_nolock
|-- generic_file_direct_write()
|-- generic_file_direct_IO()
函數 sys_write() 幾乎與 sys_read() 執行相同的步驟,它從進程中獲取文件描述符以及文件當前的操作位置後即調用 vfs_write() 函數去執行具體的操作過程,而 vfs_write() 函數最終是調用了 file 結構中的相關操作完成文件的寫操作,即調用了 generic_file_write() 函數。在函數 generic_file_write() 中, 函數 generic_file_write_nolock() 最終調用 generic_file_aio_write_nolock() 函數去檢查 O_DIRECT 的設置,並且調用 generic_file_direct_write() 函數去執行直接 I/O 寫操作。
函數 generic_file_aio_write_nolock() 中與直接 I/O 相關的代碼如下所示:
清單 9. 函數 generic_file_aio_write_nolock() 中與直接 I/O 相關的代碼
if (unlikely(file->f_flags & O_DIRECT)) {
written = generic_file_direct_write(iocb, iov,
&nr_segs, pos, ppos, count, ocount);
if (written < 0 || written == count)
goto out;
pos += written;
count -= written;
}
從上邊代碼可以看出, generic_file_aio_write_nolock() 調用了 generic_file_direct_write() 函數去執行直接 I/O 操作;而在 generic_file_direct_write() 函數中,跟讀操作過程類似,它最終也是調用了 generic_file_direct_IO() 函數去執行直接 I/O 寫操作。與直接 I/O 讀操作不同的是,這次需要將操作類型 WRITE 作為參數傳給函數 generic_file_direct_IO()。
前邊介紹了 generic_file_direct_IO() 的主體 direct_IO 方法:__blockdev_direct_IO()。函數 generic_file_direct_IO() 對 WRITE 操作類型進行了一些額外的處理。當操作類型是 WRITE 的時候,若發現該使用直接 I/O 的文件已經與其他一個或者多個進程存在關聯的內存映射,那麼就調用 unmap_mapping_range() 函數去取消建立在該文件上的所有的內存映射,並將頁緩存中相關的所有 dirty 位被置位的髒頁面刷回到磁盤上去。對於直接 I/O 寫操作來說,這樣做可以保證寫到磁盤上的數據是最新的,否則,即將用直接 I/O 方式寫入到磁盤上的數據很可能會因為頁緩存中已經存在的髒數據而失效。在直接 I/O 寫操作完成之後,在頁緩存中相關的髒數據就都已經失效了,磁盤與頁緩存中的數據內容必須保持同步。
如何在字符設備中執行直接 I/O
在字符設備中執行直接 I/O 可能是有害的,只有在確定了設置緩沖 I/O 的開銷非常巨大的時候才建議使用直接 I/O。在 Linux 2.6 的內核中,實現直接 I/O 的關鍵是函數 get_user_pages() 函數。其函數原型如下所示:
int get_user_pages(struct task_struct *tsk,
struct mm_struct *mm,
unsigned long start,
int len,
int write,
int force,
struct page **pages,
struct vm_area_struct **vmas);
該函數的參數含義如下所示:
-
tsk:指向執行映射的進程的指針;該參數的主要用途是用來告訴操作系統內核,映射頁面所產生的頁錯誤由誰來負責,該參數幾乎總是 current。
-
mm:指向被映射的用戶地址空間的內存管理結構的指針,該參數通常是 current->mm 。
-
start: 需要映射的用戶地址空間的地址。
-
len:頁內緩沖區的長度。
-
write:如果需要對所映射的頁面有寫權限,該參數的設置得是非零。
-
force:該參數的設置通知 get_user_pages() 函數無需考慮對指定內存頁的保護,直接提供所請求的讀或者寫訪問。
-
page:輸出參數。調用成功後,該參數中包含一個描述用戶空間頁面的 page 結構的指針列表。
-
vmas:輸出參數。若該參數非空,則該參數包含一個指向 vm_area_struct 結構的指針,該 vm_area_struct 結構包含了每一個所映射的頁面。
在使用 get_user_pages() 函數的時候,往往還需要配合使用以下這些函數:
void down_read(struct rw_semaphore *sem);
void up_read(struct rw_semaphore *sem);
void SetPageDirty(struct page *page);
void page_cache_release(struct page *page);
首先,在使用 get_user_pages() 函數之前,需要先調用 down_read() 函數將 mmap 為獲得用戶地址空間的讀取者 / 寫入者信號量設置為讀模式;在調用完 get_user_pages() 函數之後,再調用配對函數 up_read() 釋放信號量 sem。若 get_user_pages() 調用失敗,則返回錯誤代碼;若調用成功,則返回實際被映射的頁面數,該數目有可能比請求的數量少。調用成功後所映射的用戶頁面被鎖在內存中,調用者可以通過 page 結構的指針去訪問這些用戶頁面。
直接 I/O 的調用者必須進行善後工作,一旦直接 I/O 操作完成,用戶內存頁面必須從頁緩存中釋放。在用戶內存頁被釋放之前,如果這些頁面中的內容改變了,那麼調用者必須要通知操作系統內核,否則虛擬存儲子系統會認為這些頁面是干淨的,從而導致這些數據被修改了的頁面在被釋放之前無法被寫回到永久存儲中去。因此,如果改變了頁中的數據,那麼就必須使用 SetPageDirty() 函數標記出每個被改變的頁。對於 Linux 2.6.18.1,該宏定義在 /include/linux/page_flags.h 中。執行該操作的代碼一般需要先檢查頁,以確保該頁不在內存映射的保留區域內,因為這個區的頁是不會被交換出去的,其代碼如下所示:
if (!PageReserved(page))
SetPageDirty(page);
但是,由於用戶空間所映射的頁面通常不會被標記為保留,所以上述代碼中的檢查並不是嚴格要求的。
最終,在直接 I/O 操作完成之後,不管頁面是否被改變,它們都必須從頁緩存中釋放,否則那些頁面永遠都會存在在那裡。函數 page_cache_release() 就是用於釋放這些頁的。頁面被釋放之後,調用者就不能再次訪問它們。
關於如何在字符設備驅動程序中加入對直接 I/O 的支持,Linux 2.6.18.1 源代碼中 /drivers/scsi/st.c 給出了一個完整的例子。其中,函數 sgl_map_user_pages()和 sgl_map_user_pages()幾乎涵蓋了本節中介紹的所有內容。
直接 I/O 技術的特點
直接 I/O 的優點
直接 I/O 最主要的優點就是通過減少操作系統內核緩沖區和應用程序地址空間的數據拷貝次數,降低了對文件讀取和寫入時所帶來的 CPU 的使用以及內存帶寬的占用。這對於某些特殊的應用程序,比如自緩存應用程序來說,不失為一種好的選擇。如果要傳輸的數據量很大,使用直接 I/O 的方式進行數據傳輸,而不需要操作系統內核地址空間拷貝數據操作的參與,這將會大大提高性能。
直接 I/O 潛在可能存在的問題
直接 I/O 並不一定總能提供令人滿意的性能上的飛躍。設置直接 I/O 的開銷非常大,而直接 I/O 又不能提供緩存 I/O 的優勢。緩存 I/O 的讀操作可以從高速緩沖存儲器中獲取數據,而直接 I/O 的讀數據操作會造成磁盤的同步讀,這會帶來性能上的差異 , 並且導致進程需要較長的時間才能執行完;對於寫數據操作來說,使用直接 I/O 需要 write() 系統調用同步執行,否則應用程序將會不知道什麼時候才能夠再次使用它的 I/O 緩沖區。與直接 I/O 讀操作類似的是,直接 I/O 寫操作也會導致應用程序關閉緩慢。所以,應用程序使用直接 I/O 進行數據傳輸的時候通常會和使用異步 I/O 結合使用。
總結
Linux 中的直接 I/O 訪問文件方式可以減少 CPU 的使用率以及內存帶寬的占用,但是直接 I/O 有時候也會對性能產生負面影響。所以在使用直接 I/O 之前一定要對應用程序有一個很清醒的認識,只有在確定了設置緩沖 I/O 的開銷非常巨大的情況下,才考慮使用直接 I/O。直接 I/O 經常需要跟異步 I/O 結合起來使用,本文對異步 I/O 沒有作詳細介紹,有興趣的讀者可以參看 Linux 2.6 中相關的文檔介紹。
原文:http://www.ibm.com/developerworks/cn/linux/l-cn-directio