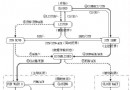
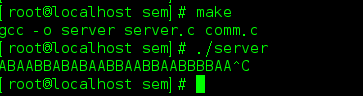
我們通常會把應用部署在Linux上,而在使用vi查詢應用日志時,可能會發現有一個^M符號,如下所示
這裡就引伸出一個概念:換行符,也就是CR(Carriage Return)和LF(Line Feed)的問題
通常我們在EditPlus——工具——參數設置——文本——新建文件—>>中可以看到PC/UNIX/MAC三種格式
而在UltraEdit——高級——配置——文件處理——新建文件類型——>>中可以看到DOS/UNIX/MAC三種格式
而且UltraEdit在保存文件時也可以指定文件格式:DOS為CRLF,UNIX為LF,MAC為CR
實際上CR(回車符)和LF(換行符)都是用來表示下一行的,只不過各個系統采用的方式不同而已
DOS/Windows系統采用CRLF(即回車+換行)表示下一行
Linux/UNIX系統采用LF表示下一行
MAC系統采用CR表示下一行
注:CR的ASCII是十進制數的13,十六進制的0x0D,LF為10和0x0A
多數的計算機語言中,CR表示為字符或者字符串就是"\r",LF為"\n"
而各語言的printf()函數中的"\n"則代表的是一個邏輯上的意義,即當前操作系統中的下一行
所以在UNIX上它代表的是LF,在Windows上則是CRLF
另外,HTTP/1.1協議的RFC2616規范中明確說到:
HTTP/1.1將CRLF的序列定義為任何協議元素的行尾標志,但這個規定對實體主體(endtity-body)除外
實體主體(entity-body)的行尾標志是由其相應的媒體類型定義的
於是,可以粗略理解為上面貼出來的HTTP報文中的"【報文內容】"部分(即HTTP請求的原始報文)
它的每一行都是以CRLF結尾的(所以在使用Mina2.x編寫HTTP服務器時就可以根據0x0D和0x0A來判斷了)
最後,回歸主題:Linux上的報文尾部出現的^M符號
當使用vi查詢日志時,vi內部會認為該日志為Linux格式的,它也只認LF
於是vi就會把遇到的CR干掉,取而代之的就是顯示出來一個^M符號
下面再引申出來一個關於CR(回車)和LF(換行)的歷史,僅供了解
計算機出現之前,是使用電傳打字機(Teletype Model 33)打印字符的,它每秒可以打10個字符
但在打完一行後,准備換行時發現,換行需要用去0.2秒,而這0.2秒又正好可以打印兩個字符
而如果在這0.2秒期間,又有新的字符傳過來,那麼傳過來的這個字符將丟失,因為它正在換行
於是,研制人員為了解決此問題,就決定在每行後面添加兩個表示結束的字符,即CR(回車)和LF(換行)
CR(回車):告訴打字機把打印頭重定位在該行的左邊界
LF(換行):告訴打字機把打印頭下移一行,即把紙向下移一行
接著,隨著計算機的發明,這種處理機制也就被移到了計算機上
但當時存儲器很貴,有些人認為在每行結尾加兩個字符太浪費了,應該加一個就行了,於是乎分歧出現了
DOS/Windows系統采用CRLF(即回車+換行)表示下一行
Linux/UNIX系統采用LF表示下一行
MAC系統采用CR表示下一行
這種分歧導致的直接後果就是:
Windows中打開Linux/UNIX系統下的文件時,所有的文字都會變成一行(因為Windows只認為CRLF才表示換行)
Linux/UNIX中打開Windows系統下的文件時,在每行的結尾可能會多出一個^M符號
而^M符號是Linux等系統規定的一個特殊標記,它占一個字符的大小,它不是^和M的組合,是打印不出來的
並且^M符號也只是用於顯示而已,它不會真正的寫入到文件中