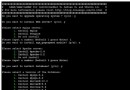
通過上面fork()的說明,這個程序的輸出應該是:
./test
count= 1
count= 1
2)而將fork()換成vfork()呢,程序如下
#include <unistd.h>
#include <stdio.h>
int main(void)
{
pid_t pid;
int count=0;
pid=vfork();
count++;
printf("count= %d\n",count);
return 0;
}
執行結果:
./test
count= 1
count= 1
Segmentation fault (core dumped)
分析:
通過將fork()換成vfork(),由於vfork()是共享數據段,為什麼結果不是2呢,答案是:
vfork保證子進程先運行,在它調用 exec 或 exit 之後父進程才可能被調度運行.如果在調用這兩個函數之前子進程依賴於父進程的進一步動作,則會導致死鎖.
3)做最後的修改,在子進程執行時,調用_exit(),程序如下:
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
int main(void)
{
pid_t pid;
int count=0;
pid=vfork();
if(pid==0)
{
count++;
_exit(0);
}
else
{
count++;
}
printf("count= %d\n",count);
return 0;
}
執行結果:
./test
count= 2
分析:如果子進程中如果沒有調用_exit(0),則父進程不可能被執行,在子進程調用exec(),exit()之後父進程才可能被調用.
所以加上_exit(0),使子進程退出,父進程執行.
這樣 else 後的語句就會被父進程執行,又因在子進程調用 exec 或 exit 之前與父進程數據是共享的,
所以子進程退出後把父進程的數據段 count 改成1了,子進程退出後,父進程又執行,最終就將count 變成了 2.
五)寫拷貝技術
寫拷貝或叫做寫時拷貝,就是子進程在創建後共享父進程的虛存內存空間,只是在兩個進程中某一個進程需要向虛擬內存寫入數據時才拷貝相應部分的虛擬內存.
寫拷貝的目的是通過消除不必要的復制來提高效率,當運行一個fork進程時,兩個進程將盡可能長地共享相同的物理內存,也就是說內核只復制頁表入口地址和標記所有寫拷貝的頁面.
當有一個進程修改內存時,將會引起缺頁,這時內核將分配一個新的物理存儲頁,並在它被修改之前復制該頁.
這樣對像init,xinetd,sshd這樣的進程將非常有用,因為他們的工作也只是調用fork和exec.
六)clone
.clone函數是Linux所特有的,可以用於創建進程和線程,所有可移植代碼從來不使用clone系統調用.
.clone是一個復雜的系統調用,它給予應用程序很大的權限,可以控制父進程共享哪些子進程,它可以將一個線程當作一個特定進程,與其父進程共享用戶共間.
七)最後的總結:
1)fork()系統調用是創建一個新進程的首選方式,fork的返回值要麼是0,要麼是非0,父進程與子進程的根本區別在於fork函數的返回值.
2)vfork()系統調用除了能保證用戶空間內存不會被復制之外,它與fork幾乎是完全相同的.vfork存在的問題是它要求子進程立即調用exec,
而不用修改任何內存,這在真正實現的時候要困難的多,尤其是考慮到exec調用有可能失敗.
3)vfork()的出現是為了解決當初fork()浪費用戶空間內存的問題,因為在fork()後,很有可能去執行exec(),vfork()的思想就是取消這種復制.
4)現在的所有unix變量都使用一種寫拷貝的技術(copy on write),它使得一個普通的fork調用非常類似於vfork.因此vfork變得沒有必要.