近年來,有一種趨勢是數據中心優先選擇商用的硬件和軟件而非采用專利的解決方案的商品。他們為什麼不能這樣做呢?這種做法具有非常低的成本並且可以以更有 利的方式來靈活地構建生態系統。唯一的限制是管理員想象的空間有多大。然而,一個問題要問:“與專利的和更昂貴的解決方案相比較,這樣的定制解決方案表現 如何呢?”
開放源碼項目已經發展成熟到了具有足夠的競爭力,並提供相同的功能豐富的解決方案,包括卷管理,數據快照,重復數據刪除等。雖然經常被忽視的,長期支持的概念是高可用性。
高可用性的想法很簡單:消除任何單點故障。這保證了如果一個服務器節點或一個底層存儲路徑停止工作了(計劃或非計劃的),還依然可以提供數據請求服務。現在存儲部署的解決方案都是多層結構的,並且是可以為高可用性進行配置的,這就是為什麼本文嚴格關注HA-LVM。
高可用性的邏輯卷管理器(HA-LVM)已經集成了LVM的套件。它提供共享卷一個故障轉移的配置,也就是說如果集群中的一台服務器出現故障或進行維護, 共享存儲配置將故障轉移到輔助服務器上,所有I / O請求將恢復,不間斷的。HA-LVM配置是一個主/從配置。這意味著在任何一個時間只有一個服務器訪問共享存儲。在許多情況下,這是一種理想的方法,因 為一些先進的LVM的功能,如快照和重復數據刪除,在主/從環境下是不支持的(當多個服務器訪問共享存儲)。
CLVM(LVM集群的守護進程)是HA-LVM一個非常重要的組件。當啟動HA-LVM後,CLVM守護進程會防止有多台機器同時對共享存儲做修 改,否則對LVM的元數據和邏輯卷會造成破壞。盡管在采用主從配置時,這樣的問題並不需要太多擔心。要做到這一點,守護進程得依賴於分布鎖管理器 (DLM). DLM的目的也是協助CLVM訪問磁盤。
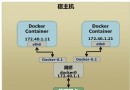
下面會舉一個2台服務器的集群訪問一個外部存儲的例子(圖一)。 這個外部存儲可以是采用磁盤陣列形勢的(RAID-enabled) 或者磁盤簇(JBOD)形式的磁盤驅動器,可以是通過光纖信道(Fibre Channel),串行連接(SAS),iSCSI或者其他的存儲區域網絡及其協議(SAN)接入到服務器的。這個配置是與協議無關的,只要求集群中的服務器能訪問到同一共享數據塊設備。
圖一.舉例兩台服務器訪問同一個共享存儲的配置
MD RAID還不支持集群,所有也就不能兼容CLVM.
CLVM 守護進程會將LVM元數據的更新分發到整個集群中,前提是集群中的每個節點都必須運行守護進程。
磁盤簇(就是一堆磁盤)是一種使用多個磁盤驅動器的架構,但是不支持具有冗余能力的配置。
幾乎所有的Linux發行套件都提供必要的工具包。但是,工具包的名字可能各有差異。你需要安裝lvm2-clumster(在部分發行套件中,可能命名 為clvm),Corosync集群引擎,紅帽集群管理器(cman),資源組管理進程(rgmanager),還有所有其他運行在服務器上的獨立的工 具。盡管紅帽集群管理器的描述中就包含了“紅帽”的發行套件的名字,但是其他與紅帽無關的大多數Linux的發行套件還在會把cman列在他們的資源庫 中。
當集群中所有的服務器都安裝好合適的集群工具包後,必須修改集群配置文件來啟動集群。創建文件/etc/cluster/cluster.conf,如下編輯內容就可以了:
<cluster name="lvm-cluster" config_version="1">
<cman two_node="1" expected_votes="1" />
<clusternodes>
<clusternode name="serv-0001" nodeid="1">
<fence>
</fence>
</clusternode>
<clusternode name="serv-0002" nodeid="2">
<fence>
</fence>
</clusternode>
</clusternodes>
<logging debug="on">
</logging>
<dlm protocol="tcp" timewarn="500">
</dlm>
<fencedevices>
</fencedevices>
<rm>
</rm>
</cluster>
強調一下clusternode的名字是主機名(按需修改),而且務必保證所有集群中的服務器上的cluster.conf文件是一致的。
啟動紅帽集群管理器(cman):
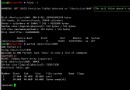
$ sudo /etc/rc.d/init.d/cman start Starting cluster: Checking if cluster has been disabled at boot... [ OK ] Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Tuning DLM kernel config... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ]
如果集群中的某個節目沒有激活,它的狀態顯示為離線:
$ sudo clustat Cluster Status for lvm-cluster @ Sun Aug 3 11:31:51 2014 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ serv-0001 1 Online, Local serv-0002 2 Offline
如果所有服務器都配置好了,cman服務也啟動了,所有節點顯示狀態為在線:
$ sudo clustat Cluster Status for lvm-cluster @ Sun Aug 3 11:36:43 2014 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ serv-0001 1 Online serv-0002 2 Online, Local
現在你就有一個集群的工作環境了。下一步就是啟動CLVM的高可用模式。當前場景中,你只有2台服務器共享的存儲中的一個卷,這2台服務器都可以監視和訪問/dev/sdb中的數據。
/etc/lvm/lvm.conf 也需要被修改。在全局參數 locking_type 的值默認為 1,必須改為 3:
# Type of locking to use. Defaults to local file-based # locking (1). # Turn locking off by setting to 0 (dangerous: risks metadata # corruption if LVM2 commands get run concurrently). # Type 2 uses the external shared library locking_library. # Type 3 uses built-in clustered locking. # Type 4 uses read-only locking which forbids any operations # that might change metadata. locking_type = 3
找一台集群中的服務器,在指定的共享卷上面創建一個卷組,一個邏輯卷和一個文件系統:
$ sudo pvcreate /dev/sdb $ sudo vgcreate -cy shared_vg /dev/sdb $ sudo lvcreate -L 50G -n ha_lv shared_vg $ sudo mkfs.ext4 /dev/shared_vg/ha_lv $ sudo lvchange -an shared_vg/ha_lv
上例中消耗卷組中的50GB的來創建邏輯卷,然後用其創建4個拓展的文件文件系統。vgcreate (創建卷組命令)的 -cy 選項 用於啟動,並在集群中鎖定卷組。lvchange (邏輯卷修改命令)的 -an 選項用來停用邏輯組。但是你必須依賴CLVM和資源管理器的進程,按上面創建的/etc/cluster/cluster.conf的配置中的故障轉移的策略來激活他們。一旦邏輯卷被激活,你就可以從/dev/shared_vg/ha_lv訪問共享的卷了。
在 cluster.conf 文件中添加故障轉移的詳細配置信息:
<rm>
<failoverdomains>
<failoverdomain name="FD" ordered="1" restricted="0">
<failoverdomainnode name="serv-0001" priority="1"/>
<failoverdomainnode name="serv-0002" priority="2"/>
</failoverdomain>
</failoverdomains>
<resources>
<lvm name="lvm" vg_name="shared_vg" lv_name="ha-lv"/>
<fs name="FS" device="/dev/shared_vg/ha-lv"
↪force_fsck="0" force_unmount="1" fsid="64050"
↪fstype="ext4" mountpoint="/mnt" options=""
↪self_fence="0"/>
</resources>
<service autostart="1" domain="FD" name="serv"
↪recovery="relocate">
<lvm ref="lvm"/>
<fs ref="FS"/>
</service>
</rm>
"rm"中的內容會作用到資源管理器上(rgmanager)。這部分的配置通知集群管理器,serv-0001優先獨占訪問共享卷。數據會掛載在 /mnt 這個絕對目錄下面。 如果serv-0001因為某些原因當機了,資源管理器就會做故障轉移處理,使serv-0002獨占訪問共享卷,數據會掛載在serv-0002的 /mnt的這個目錄下。所有發送到serv-0001的處於等待的I/O請求會由serv-0002響應。
在所有服務器中,重啟cman服務是配置修改生效:
$ sudo /etc/rc.d/init.d/cman restart
同樣,還需要再所有服務器中重啟 rgmanager 和 clvmd 服務:
$ sudo /etc/rc.d/init.d/rgmanager start Starting Cluster Service Manager: [ OK ] $ sudo /etc/rc.d/init.d/clvmd start Starting clvmd: [ OK ]
如果都沒問題,那麼你就配置好了一個主/從的集群配置。你可以通過查看服務器對共享卷的訪問權限來校驗配置是否生效。實驗應該可以發現,serv- 0001 可以掛在共享卷,但是 serv-0002 不可以。接著就是檢驗真理的時刻了——那就是測試故障轉移。手動對 serv-0001 斷電,你可以發現rgmanager 影子,並且 serv-0002 可以訪問/掛在共享卷了。
對應一個理想的配置,fencing相關的配置必須出現在/etc/cluster/cluster.conf文件中。fencing的目的是在有問題的 節點對集群造成顯而易見的問題之前就對其進行處理。比如,某台服務器發生Kernel panic,或者無法與集群中的其他服務器通信,再或者遇到其他各種災難性的崩潰等情況下,可以配置IPMI來重啟問題服務器:
<clusternode name="serv-0001" nodeid="1">
<fence>
<method name="1">
<device name="ipmirecover1"/>
</method>
</fence>
</clusternode>
<clusternode name="serv-0002" nodeid="2">
<fence>
<method name="1">
<device name="ipmirecover2"/>
</method>
</fence>
</clusternode>
[ ... ]
<fencedevices>
<fencedevice agent="fence_ipmilan" ipaddr="192.168.1.50"
↪login="ADMIN" passwd="ADMIN" name="ipmirecover1"/>
<fencedevice agent="fence_ipmilan" ipaddr="192.168.10"
↪login="ADMIN" passwd="ADMIN" name="ipmirecover2"/>
</fencedevices>
HA-LVM的設計初衷是為數據中心提供廉價的容錯處理機制。沒有人希望服務器當機,話說回來,只有配置得當,當機也不是肯定的。從數據中心到家庭辦公,幾乎任何場景都可以實施這套方案。
譯文:http://www.oschina.net/translate/high-availability-storage-ha-lvm